最优的方法竟然来自“贪心算法”
Posted 大数据与车联网创新中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最优的方法竟然来自“贪心算法”相关的知识,希望对你有一定的参考价值。
科技热词全知道(上篇)

在介绍这些热词之前,创萌君不忘初心,牢记使命,为大家送干货送彻底。
先奉上汇总表,点击查看图片,双击保存,方便快速查询,方便GET知识点,方便下载随时记。


Tips
对应序号,可以在下文中具体了解这些高B格名词的含义哦~
不过,创萌君还是觉得,想要涨更多姿势,还是都看一遍比较好。
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学,是计算机科学的一个分支。
它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能研究的主要目标是使机器能胜任一些通常需要人类智能才能完成的复杂工作。
狭义来讲,区块链是一种按照时间顺序将数据区块以顺序相连的方式组合成的一 种链式数据结构, 并以密码学方式保证的不可篡改和不可伪造的分布式账本。
广义来讲,区块链技术是利用块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新数据、利用密码学的方式保证数据传输和访问的安全、利用由自动化脚本代码组成的智能合约来编程和操作数据的一种全新的分布式基础架构与计算范式。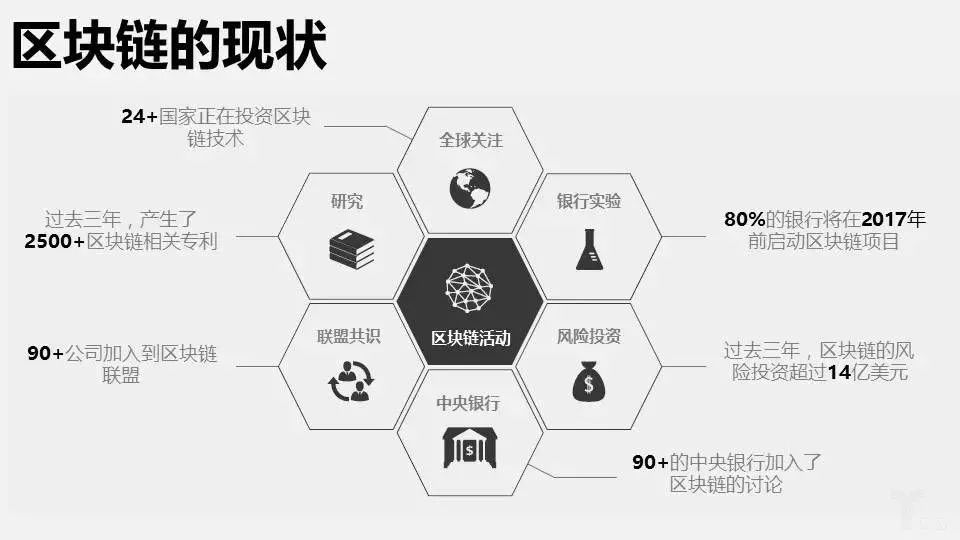
图灵测试(The Turing test)源于计算机科学和密码学的先驱艾伦·麦席森·图灵写于1950年的一篇论文《计算机器与智能》,指测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。
进行多次测试后,如果有超过30%的测试者不能确定出被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。其中30%是图灵对2000年时的机器思考能力的一个预测,目前我们已远远落后于这个预测。
回归分析(regression analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。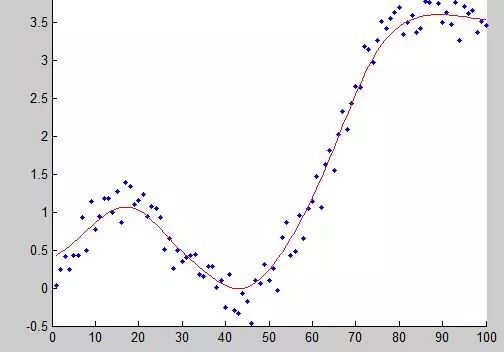
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多重线性回归分析。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。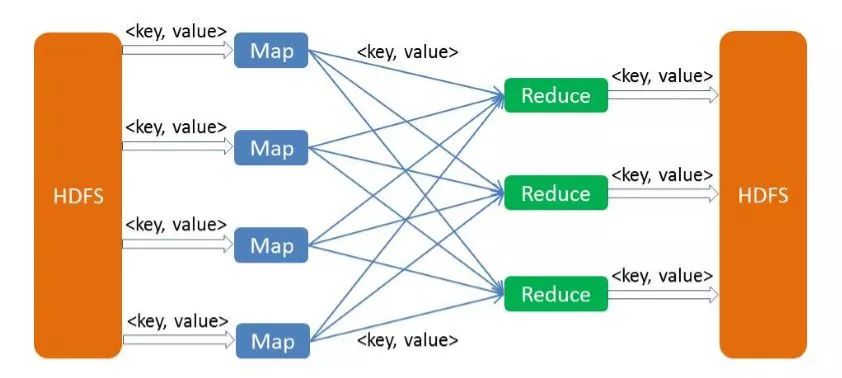
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
贪心算法(又称贪婪算法),是指在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
贪心算法关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关。
贪心算法的基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解。每一步只考虑一个数据,他的选取应该满足局部优化的条件。若下一个数据和部分最优解连在一起不再是可行解时,就不把该数据添加到部分解中,直到把所有数据枚举完,或者不能再添加算法停止 。
数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。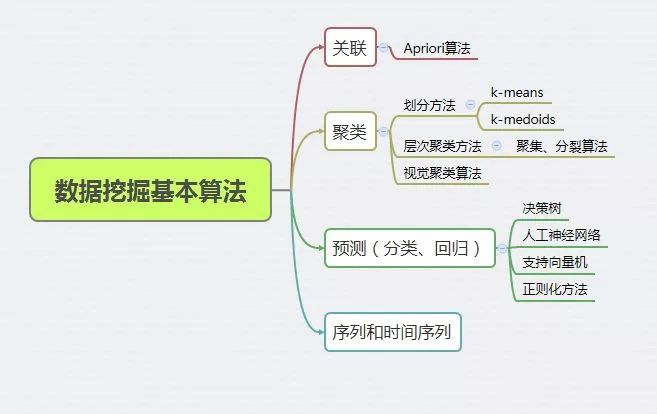
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为:一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。
它是一个处于不断演变之中的概念,其边界在不断地扩大。主要指的是技术上较为高级的技术方法,而这些技术方法允许利用图形、图像处理、计算机视觉以及用户界面,通过表达、建模以及对立体、表面、属性以及动画的显示,对数据加以可视化解释。与立体建模之类的特殊技术方法相比,数据可视化所涵盖的技术方法要广泛得多。
在计算机科学中,分布式计算(又译为分散式计算)这个研究领域,主要研究分散系统(Distributed system)如何进行计算。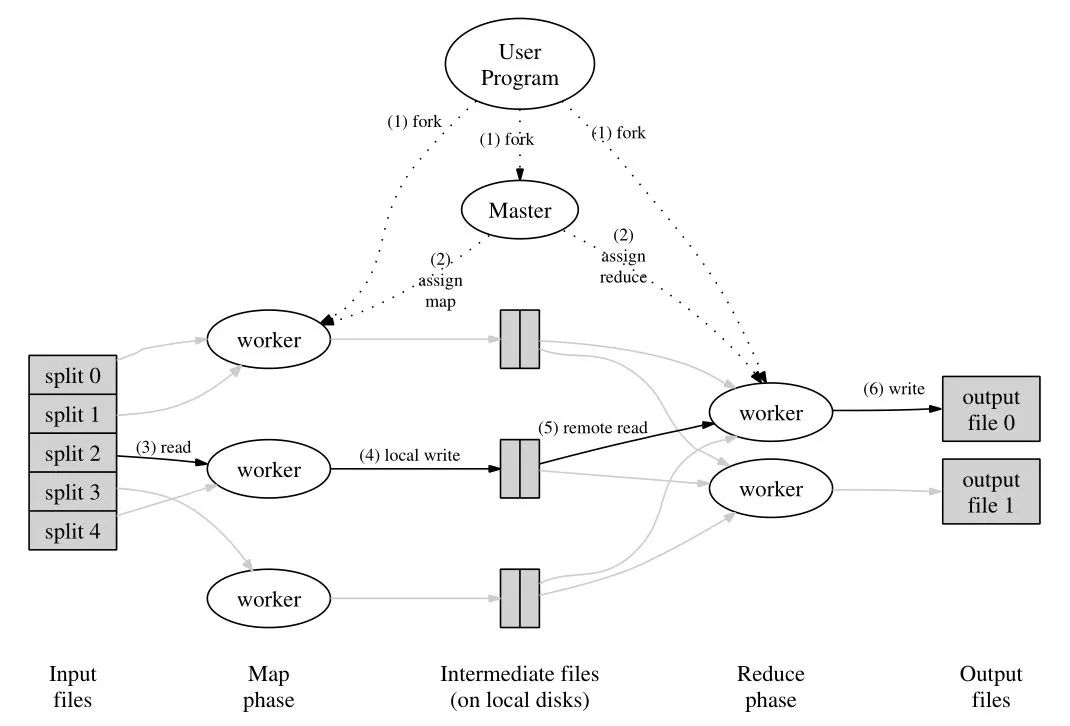
分散系统是一组电子计算机,通过计算机网络相互链接与通信后形成的系统。把需要进行大量计算的工程数据分区成小块,由多台计算机分别计算,在上传运算结果后,将结果统一合并得出数据结论的科学。
分布式架构是分布式计算技术的应用和工具,目前成熟的技术包括J2EE, CORBA和.NET(DCOM),这些技术牵扯的内容非常广,在互联网大行其道的今天,各种分布式系统已经司空见惯。搜索引擎、电商网站、微博、微信、O2O平台等等。凡是涉及到大规模用户、高并发访问的,无一不是分布式。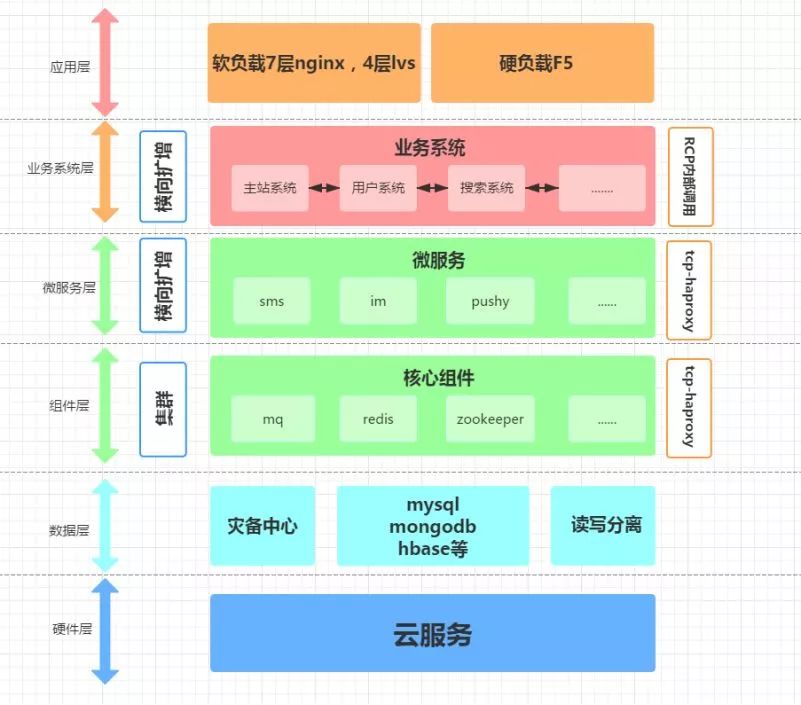
对于分布式架构的具体内容,创萌君会在今后的推文中做详细介绍,要记得持续关注并点赞哦~
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
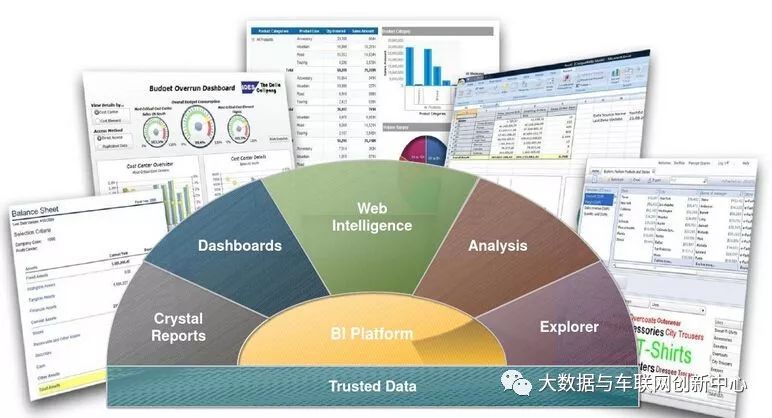
BI(Business Intelligence)即商务智能,它是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,快速准确的提供报表并提出决策依据,帮助企业做出明智的业务经营决策。
商业智能的概念最早在1996年提出。当时将商业智能定义为一类由数据仓库(或数据集市)、查询报表、数据分析、数据挖掘、数据备份和恢复等部分组成的、以帮助企业决策为目的技术及其应用。而这些数据可能来自企业的CRM(客户关系管理)、SCM(软件配置管理)等业务系统。
商业智能能够辅助的业务经营决策,既可以是操作层的,也可以是战术层和战略层的决策。为了将数据转化为知识,需要利用数据仓库、联机分析处理(OLAP)工具和数据挖掘等技术。因此,从技术层面上讲,商业智能不是什么新技术,它只是数据仓库、OLAP和数据挖掘等技术的综合运用。
把商业智能看成一种解决方案应该比较恰当。商业智能的关键是从许多来自不同的企业运作系统的数据中提取出有用的数据并进行清理,以保证数据的正确性,然后经过抽取(Extraction)、转换(Transformation)和装载(Load),即ETL过程,合并到一个企业级的数据仓库里,从而得到企业数据的一个全局视图,在此基础上利用合适的查询和分析工具、数据挖掘工具、OLAP工具等对其进行分析和处理(这时信息变为辅助决策的知识),最后将知识呈现给管理者,为管理者的决策过程提供数据支持。
商业智能产品及解决方案大致可分为数据仓库产品、数据抽取产品、OLAP产品、展示产品、和集成以上几种产品的针对某个应用的整体解决方案等。
非关系型数据库,又被称为NoSQL(Not Only SQL ),意为不仅仅是SQL( Stmuctured QueryLanguage,结构化查询语言),据维基百科介绍,NoSQL最早出现于1998 年,是由Carlo Storzzi最早开发的个轻量、开源、不兼容SQL 功能的关系型数据库,2009 年,在一次分布式开源数据库的讨论会上,再次提出了NOSQL 的概念,此时NOSQL主要是指I非关系型、分布式、不提供ACID (数据库事务处理的四个本要素)的数据库设计模式。
同年,在业特兰大举行的“NO:SQL(east)”讨论会上,对NOSQL 最普遍的定义是“非关联型的”,强调Key-Value 存储和文档数据库的优点,而不是单纯地反对RDBMS,至此,NoSQL 开始正式出现在世人面前。
结构化数据,简单来说就是数据库。结合到典型场景中更容易理解,比如企业ERP、财务系统;医疗HIS数据库;教育一卡通;政府行政审批;其他核心数据库等。
基本包括高速存储应用需求、数据备份需求、数据共享需求以及数据容灾需求。
和普通纯文本相比,半结构化数据具有一定的结构性,但和具有严格理论模型的关系数据库的数据相比。OEM(Object exchange Model)是一种典型的半结构化数据模型。

在做一个信息系统设计时肯定会涉及到数据的存储,一般我们都会将系统信息保存在某个指定的关系数据库中。我们会将数据按业务分类,并设计相应的表,然后将对应的信息保存到相应的表中。比如我们做一个业务系统,要保存员工基本信息:工号、姓名、性别、出生日期等等;我们就会建立一个对应的staff表。

长按二维码,详情咨询
商务合作微信:polar0607
转载要备注哦~
以上是关于最优的方法竟然来自“贪心算法”的主要内容,如果未能解决你的问题,请参考以下文章