那些经典算法:贪心算法
Posted 尧字节
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了那些经典算法:贪心算法相关的知识,希望对你有一定的参考价值。
贪心算法和分治算法、动态规划算法、回溯算法都是一种编程思想,深入理解这些编程思想,我们也可以根据实际情况设计自己的算法。
一 贪心算法原理
贪心算法的原理比较简单,就是对问题求解的时候,每步都选择当前的最优解,然后已期望得到全局最优解。
贪心算法的适用场景是每次选择是没有状态的,也就是不会对后面的步骤产生影响。
二 贪心算法举例
同样用老师课件中的两个例子:
背包问题:
假如我们有一个可以装100kg物品的背包,我们有5种豆子,每种豆子的总量和总价值各不相同。为了让背包中所装的物品的总价值最大,我们如何选择装哪些豆子,每种装多少?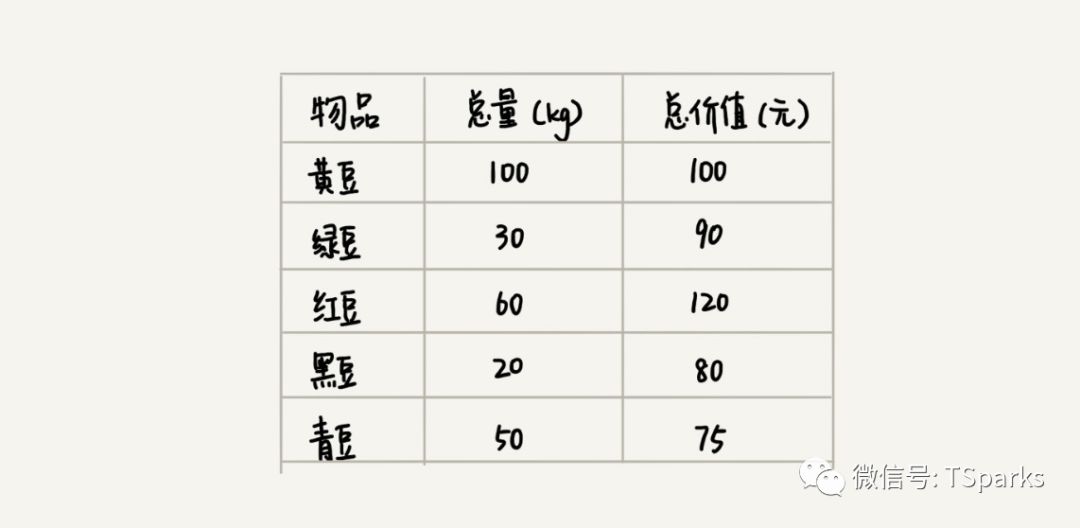
分析
直观来想,我们的总重是100kg是限制的,要求装的物品总价值最大,那么我们可以把各种豆子的单价计算下每种豆子的单价,然后按照从高到低排序,每次装完最有价值的豆子后,再继续装稍次价值的豆子,直到装满整个背包。
分糖果:
我们有m个糖果和n个孩子,现在要把糖果分给这些孩子吃,但是糖果少m<n,所以只有一部分孩子能够得到糖果,每个糖果的大小不一样,m个糖果大小分别为s1,s2,s3….sm.除此之外,每个孩子对糖果大小需求不一样,假设这些孩子对糖果的需求大小分别为g1,g2…gn,只有糖果大小大于孩子对糖果需求的时候,他们才会满足,求我们如何分糖果才能够满足最多数量的孩子。
分析:
这个问题是我们选择一部分小孩分给他们糖果,要满足一共最多只能分给m个孩子,还要让满意的孩子最多。和上一个问题类似,就是我们按照孩子对糖果满足从小到大排序,然后依次选能够满足孩子需求的最小糖果,这样依次分下去就可以达到满足最多孩子的目的。
这类题目的特点:
1) 都是有限制的请求下求解
背包问题限制是100kg,分糖果问题限制问题是最多有m个糖果。
2)都是求限制条件下的最优解,背包问题是求最大价值,分糖果是为了求满足最多孩子。
3)每步都是局部最优的,比如背包问题的时候,因为要求最大价值,所以先装最贵的,这样质量不变的情况下,增加的价值最大;分糖果也一样,是在最小糖果的情况下满足一个孩子,满足孩子的都是一个,那么我们需要减少分出去的糖果。
三 霍夫曼编码
霍夫曼编码是一种广泛用于数据文件压缩的编码方法,压缩率通常在20%到90%之间,霍夫曼编码算法根据字符出现频率,用不同的0,1串来标识字符,从而达到缩短字符串,达到压缩的目的。
还是拿课程中的算法举例:
假设有一个包含1000字符的文件,每个字符占1byte,一共需要8000bits来存储。
如果这1000个字符只包括6种字符,分别是a,b,c,d,e,f那么我们通过3个bit(最多可以标识8个字符)来表示这6个字符,那么总共需要3000bits就可以表示这个字符串了。
用这种三个bit标识一个字符,编码和解码比较简单,但是没有充分考虑每个字符在文件中出现的频率。而霍夫曼编码是结合字符在文件中的频率来进行对字符编码的,出现字符多的编码更短,由于霍夫曼编码的长短是不一样的,所以如何不让两种不同的编码之间产生混淆?那就需要保证每种编码不能为另一种编码的前缀。
假设这些字符在文件中出现的频率如下: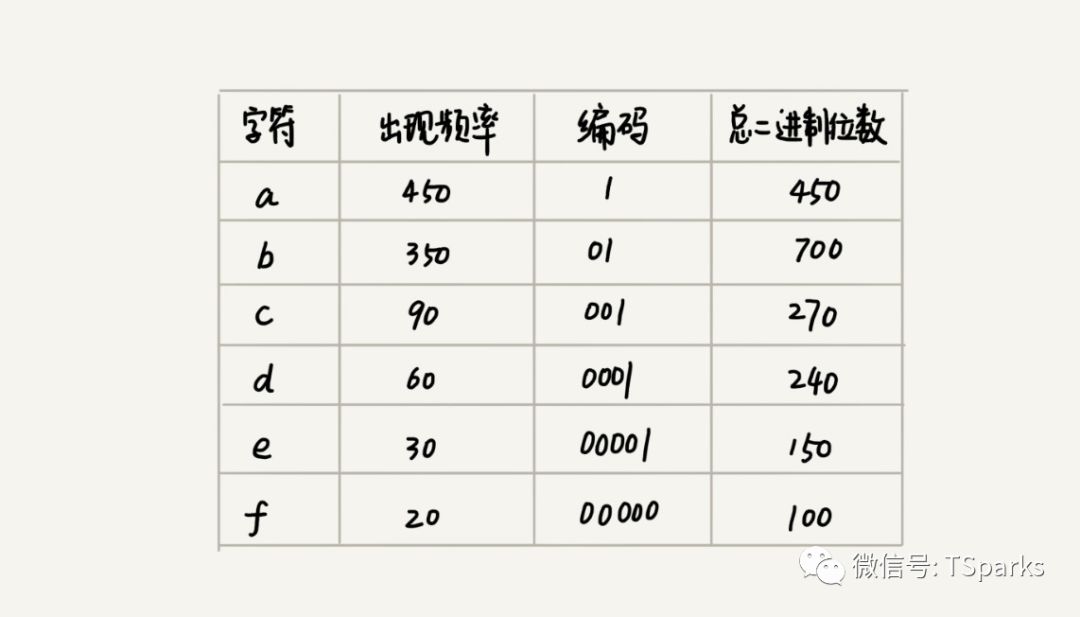
总bits 数:
1*450+2*350+3*90+4*60+5*30+5*20=2100
2100bits比原来3000bits又压缩了近1/3, 下面问题就是如何进行霍夫曼编码了。
王争老师的算法很巧妙也简单:
1)把所有涉及到的字符按照出现频率的高低放入到优先级队列中。
2)我们从队列中取出频率最小的两个字符上图中为f和e,然后新建个字符比如X,频率为f和e的频率之和,然后X作为f和e的父亲节点。
3)再把X节点放入到优先级队列中。
4)转到2继续指向,直到队列为空。
构造完一颗二叉树之后,我们给每条边都做个编码,比如左边的边为0,右边的为1,得到如下:
这样每个节点的编码可以用从根节点到此节点的边来表示:
1)比如a这个节点编码为1
2)c这个编码为001。
四 代码实现
在网上找一段求霍夫曼编码的C++代码,可以对照理解下:
#include <iostream>
using namespace std;
//最大字符编码数组长度
#define MAXCODELEN 100
//最大哈夫曼节点结构体数组个数
#define MAXHAFF 100
//最大哈夫曼编码结构体数组的个数
#define MAXCODE 100
#define MAXWEIGHT 10000;
typedef struct Haffman
{
//权重
int weight;
//字符
char ch;
//父节点
int parent;
//左儿子节点
int leftChild;
//右儿子节点
int rightChild;
}HaffmaNode;
typedef struct Code
{
//字符的哈夫曼编码的存储
int code[MAXCODELEN];
//从哪个位置开始
int start;
}HaffmaCode;
HaffmaNode haffman[MAXHAFF];
HaffmaCode code[MAXCODE];
void buildHaffman(int all)
{
//哈夫曼节点的初始化之前的工作, weight为0,parent,leftChile,rightChile都为-1
for (int i = 0; i < all * 2 - 1; ++i)
{
haffman[i].weight = 0;
haffman[i].parent = -1;
haffman[i].leftChild = -1;
haffman[i].rightChild = -1;
}
std::cout << "请输入需要哈夫曼编码的字符和权重大小" << std::endl;
for (int i = 0; i < all; i++)
{
std::cout << "请分别输入第个" << i << "哈夫曼字符和权重" << std::endl;
std::cin >> haffman[i].ch;
std::cin >> haffman[i].weight;
}
//每次找出最小的权重的节点,生成新的节点,需要all - 1 次合并
int x1, x2, w1, w2;
for (int i = 0; i < all - 1; ++i)
{
x1 = x2 = -1;
w1 = w2 = MAXWEIGHT;
//注意这里每次是all + i次里面便利
for (int j = 0; j < all + i; ++j)
{
//得到最小权重的节点
if (haffman[j].parent == -1 && haffman[j].weight < w1)
{
//如果每次最小的更新了,那么需要把上次最小的给第二个最小的
w2 = w1;
x2 = x1;
x1 = j;
w1 = haffman[j].weight;
}
//这里用else if而不是if,是因为它们每次只选1个就可以了。
else if(haffman[j].parent == -1 && haffman[j].weight < w2)
{
x2 = j;
w2 = haffman[j].weight;
}
}
//么次找到最小的两个节点后要记得合并成一个新的节点
haffman[all + i].leftChild = x1;
haffman[all + i].rightChild = x2;
haffman[all + i].weight = w1 + w2;
haffman[x1].parent = all + i;
haffman[x2].parent = all + i;
std::cout << "x1 is" << x1 <<" x1 parent is"<<haffman[x1].parent<< " x2 is" << x2 <<" x2 parent is "<< haffman[x2].parent<< " new Node is " << all + i << "new weight is" << haffman[all + i].weight << std::endl;
}
}
//打印每个字符的哈夫曼编码
void printCode(int all)
{
//保存当前叶子节点的字符编码
HaffmaCode hCode;
//当前父节点
int curParent;
//下标和叶子节点的编号
int c;
//遍历的总次数
for (int i = 0; i < all; ++i)
{
hCode.start = all - 1;
c = i;
curParent = haffman[i].parent;
//遍历的条件是父节点不等于-1
while (curParent != -1)
{
//我们先拿到父节点,然后判断左节点是否为当前值,如果是取节点0
//否则取节点1,这里的c会变动,所以不要用i表示,我们用c保存当前变量i
if (haffman[curParent].leftChild == c)
{
hCode.code[hCode.start] = 0;
std::cout << "hCode.code[" << hCode.start << "] = 0" << std::endl;
}
else
{
hCode.code[hCode.start] = 1;
std::cout << "hCode.code[" << hCode.start << "] = 1" << std::endl;
}
hCode.start--;
c = curParent;
curParent = haffman[c].parent;
}
//把当前的叶子节点信息保存到编码结构体里面
for (int j = hCode.start + 1; j < all; ++j)
{
code[i].code[j] = hCode.code[j];
}
code[i].start = hCode.start;
}
}
int main()
{
std::cout << "请输入有多少个哈夫曼字符" << std::endl;
int all = 0;
std::cin >> all;
if (all <= 0)
{
std::cout << "您输入的个数有误" << std::endl;
return -1;
}
buildHaffman(all);
printCode(all);
for (int i = 0; i < all; ++i)
{
std::cout << haffman[i].ch << ": Haffman Code is:";
for (int j = code[i].start + 1; j < all; ++j)
{
std::cout << code[i].code[j];
}
std::cout << std::endl;
}
return 0;以上是关于那些经典算法:贪心算法的主要内容,如果未能解决你的问题,请参考以下文章