Java 实现贪心算法实例介绍
Posted ImportNew
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 实现贪心算法实例介绍相关的知识,希望对你有一定的参考价值。
(给ImportNew加星标,提高Java技能)
编译:ImportNew/覃佑桦
www.baeldung.com/java-greedy-algorithms
1.引言
本文将介绍如何用 Java 实现贪心算法。
2.贪心问题
通常一个数学问题会有几种解法。可以迭代解决,也可以用分治法(快速排序算法)或者动态规划(背包问题)这样的高级方法。
大多数情况我们都在寻找最优解,但可悲的是并非每次都能得到期望的结果。某些情况下,即使是次优解也很有用。借助一些策略或者启发式方法,我们能得到这样的宝贵结果。
假定问题可以分解,并且在过程的每一步都选择局部最优即“贪心选择”,那么可以称为贪心算法。
这里的重点是问题“可拆分”:即问题可以被描述为一组相似的子问题。大多数情况下,贪心算法都采用递归实现。
即使有诸多限制,像计算资源限制、限制执行时间、API 或其它限制,贪心算法仍然有办法找到合理的解决方案。
2.1.问题
作为示例,接下来会实现一个贪心策略通过 API 从社交网络提取数据。
假设我们希望在社交网络“小蓝鸟”上吸引更多的用户。要达成目标最好的方法是发布原创内容或者转发,引起大家的兴趣。
如何找到感兴趣的观众呢?好吧,我们必须找到一个流量大 V,为他们发布一些内容。
2.2.经典算法 vs 贪心算法
考虑下面的情况:如下图所示,大 V 帐户有4个粉丝,每个粉丝分别又有2个、2个、1个和3个关注者,以此类推:
带着之前的目标,我们会挑选粉丝较多的关注者。接下来把这个过程重复两次以上,直到抵达第3级(共4级)。
通过这种方式我们确定了一组粉丝最多的用户。如果可以向这组用户推荐,那么他们中一定会有人打开页面。
先从“传统方式”开始。每一次都查询关注此帐户的粉丝。随着选择地进行,查询的帐户数量会逐渐增加。
令人吃惊的是,总共要执行25次查询:
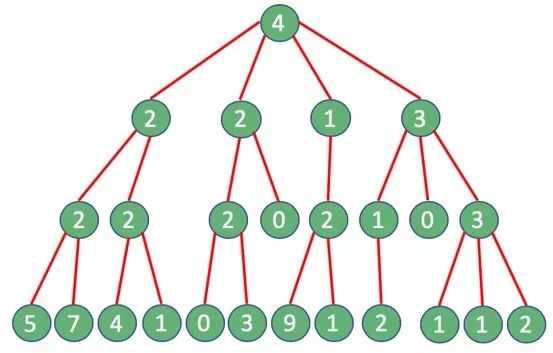
这里有一个问题:Twitter API 的查询限制是每15分钟最多查询15次。如果超过调用限制,则会报告 “Rate limit exceeded code – 88” 或者“API v1.1 由于应用程序 rate limit 达到限值无法处理请求”。如何突破限制?
远在天边,近在眼前:贪心算法。在贪心算法中,每一步只有粉丝最多的用户才是我们考虑的对象:结果只需要4次查询,效果显著!
这两种方法的结果将有所不同。使用传统方法,最好的情况下需要16次查询,而贪心算法最多需要12次。
这种差异是否真的有价值?这个稍后再讨论。
3.实现
为了实现上述逻辑,我们做了一个 Java 程序模拟 Twitter API。此外,还用到了Lombok 开发库。
定义SocialConnector 实现代码逻辑。注意:包含的 counter 模拟调用限制,为方便测试把限制减少到4次:
public class SocialConnector {
private boolean isCounterEnabled = true;
private int counter = 4;
@Getter @Setter
List users;
public SocialConnector() {
users = new ArrayList<>();
}
public boolean switchCounter() {
this.isCounterEnabled = !this.isCounterEnabled;
return this.isCounterEnabled;
}
}接着添加 getFollowers 方法获取粉丝列表:
public List getFollowers(String account) {
if (counter < 0) {
throw new IllegalStateException ("API limit reached");
} else {
if (this.isCounterEnabled) {
counter--;
}
for (SocialUser user : users) {
if (user.getUsername().equals(account)) {
return user.getFollowers();
}
}
}
return new ArrayList<>();
}为了流程需要,还需要添加 User 实体类:
public class SocialUser {
@Getter
private String username;
@Getter
private List<SocialUser> followers;
@Override
public boolean equals(Object obj) {
return ((SocialUser) obj).getUsername().equals(username);
}
public SocialUser(String username) {
this.username = username;
this.followers = new ArrayList<>();
}
public SocialUser(String username, List<SocialUser> followers) {
this.username = username;
this.followers = followers;
}
public void addFollowers(List<SocialUser> followers) {
this.followers.addAll(followers);
}
}3.1.贪心算法
最后实现贪心算法,添加 GreedyAlgorithm 开始实现递归:
public class GreedyAlgorithm {
int currentLevel = 0;
final int maxLevel = 3;
SocialConnector sc;
public GreedyAlgorithm(SocialConnector sc) {
this.sc = sc;
}
}需要添加一个 findMostFollowersPath 方法,找到粉丝最多的用户并对其进行计数,然后继续执行下一步:
public long findMostFollowersPath(String account) {
long max = 0;
SocialUser toFollow = null;
List followers = sc.getFollowers(account);
for (SocialUser el : followers) {
long followersCount = el.getFollowersCount();
if (followersCount > max) {
toFollow = el;
max = followersCount;
}
}
if (currentLevel < maxLevel - 1) {
currentLevel++;
max += findMostFollowersPath(toFollow.getUsername());
}
return max;
}请记住:在这里进行贪心选择。每次调用 findMostFollowersPath 时,从列表中仅选择一个元素并继续:已选择的路径不再返回。
完美!准备就绪,可以开始测试我们的程序。在此之前需要初始化迷你关系网,然后启动单元测试:
public void greedyAlgorithmTest() {
GreedyAlgorithm ga = new GreedyAlgorithm(prepareNetwork());
assertEquals(ga.findMostFollowersPath("root"), 5);
}3.2.非贪心算法
创建一个非贪心方法,看看执行效果。新建 NonGreedyAlgorithm 类:
public class NonGreedyAlgorithm {
int currentLevel = 0;
final int maxLevel = 3;
SocialConnector tc;
public NonGreedyAlgorithm(SocialConnector tc, int level) {
this.tc = tc;
this.currentLevel = level;
}
}实现一个功能等价的 findMostFollowersPath 方法:
public long findMostFollowersPath(String account) {
List<SocialUser> followers = tc.getFollowers(account);
long total = currentLevel > 0? followers.size() : 0;
if (currentLevel < maxLevel ) {
currentLevel++;
long[] count = new long[followers.size()];
int i = 0;
for (SocialUser el : followers) {
NonGreedyAlgorithm sub = new NonGreedyAlgorithm(tc, currentLevel);
count[i] = sub.findMostFollowersPath(el.getUsername());
i++;
}
long max = 0;
for (; i > 0; i--) {
if (count[i-1] > max) {
max = count[i-1];
}
}
return total + max;
}
return total;
}准备相应的单元测试:一个用来验证是否超出调用限制,另一个用来检查使用非贪心算法的返回值:
public void nongreedyAlgorithmTest() {
NonGreedyAlgorithm nga = new NonGreedyAlgorithm(prepareNetwork(), 0);
Assertions.assertThrows(IllegalStateException.class, () -> {
nga.findMostFollowersPath("root");
});
}
public void nongreedyAlgorithmUnboundedTest() {
SocialConnector sc = prepareNetwork();
sc.switchCounter();
NonGreedyAlgorithm nga = new NonGreedyAlgorithm(sc, 0);
assertEquals(nga.findMostFollowersPath("root"), 6);
}4.结果
回顾一下前面的工作。
首先,我们尝试了贪心算法并验证了其有效性。然后,在启用和取消 API 限制的情况下验证了传统方法的结果(穷尽式搜索)。
贪心算法能快速返回结果,每次都选择局部最优解。相反,由于 API 限制,非贪心算法可能无法返回结果(抛异常)。
比较两种方法及结果可以看到,即使得到的不是最优解,贪心算法也能为我们解忧。可以把它称为局部最优解。
5.总结
在社交媒体瞬息万变今天,找到最优解也许已经成为一种不切实际的妄想:既难以达到,也不太现实。
如何克服限制与优化 API 调用是一个很大的课题,但正如本文讨论的那样,贪心算法是一种有效的办法。选择贪心算法能帮助我们减轻寻找最优解的痛苦,进而得到有价值的结果。
请记住,贪心算法也非银弹,不是每种情况都适用:需要具体问题具体分析。
本文中的示例代码可在 GitHub 上找到。
github.com/eugenp/tutorials/tree/master/algorithms-miscellaneous-5
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能
好文章,我在看❤️
以上是关于Java 实现贪心算法实例介绍的主要内容,如果未能解决你的问题,请参考以下文章