GreedyAlgorithm(贪心算法)
Posted ComputerNotes
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GreedyAlgorithm(贪心算法)相关的知识,希望对你有一定的参考价值。

4110:圣诞老人的礼物-Santa Clau’s Gifts
总时间限制: 1000ms内存限制: 65536kB
描述
圣诞节来临了,在城市A中圣诞老人准备分发糖果,现在有多箱不同的糖果,每箱糖果有自己的价值和重量,每箱糖果都可以拆分成任意散装组合带走。圣诞老人的驯鹿最多只能承受一定重量的糖果,请问圣诞老人最多能带走多大价值的糖果。
输入
第一行由两个部分组成,分别为糖果箱数正整数n(1 <= n <= 100),驯鹿能承受的最大重量正整数w(0 < w < 10000),两个数用空格隔开。其余n行每行对应一箱糖果,由两部分组成,分别为一箱糖果的价值正整数v和重量正整数w,中间用空格隔开。
输出
输出圣诞老人能带走的糖果的最大总价值,保留1位小数。输出为一行,以换行符结束。
样例输入
4 15
100 4
412 8
266 7
591 2样例输出
1193.0
1
解法:
按照礼物的价值/重量比从大到小依次选取礼物,对选取的礼物尽可能多地装,直到达到总重量w.
复杂度:O(NlogN)
证明:
替换法。对于用非此法选取的最大价值糖果箱序列,可以将其按价值/重量比从大到小排序后得到:
序列1:a1,a2.....
用序列1和按上述解法选取的序列2依次进行比较:
序列2:b1,b2.....
价值/重量比相同的若干箱糖果,可以合并成一箱,所以两个序列中元素对于发现的第一个ai != bi,则必有:ai < bi
则在序列1中,用bi这种糖果,替代若干重量的ai这种糖果,则会使得序列1的总价值增加,这和序列1是价值最大的取法矛盾。
所以:序列1=序列2(序列2不可能使序列1的一个前缀且比序列1短)
每一步行动总是按某种指标选取最优的操作来进行,该指标只看眼前,并不考虑以后可能造成的影响。
贪心算法需要证明其正确性。
“圣诞老人礼物”题,若糖果只能整箱拿,则贪心法错误。
考虑下面例子:
3个箱子(8,6)(5,5)(5,5)雪橇总容量10
using namespace std;using pii = pair<double,double>;int N,W;vector<pii> stu;bool cmp(pii & a, pii & b){return a.first/a.second - b.first/b.second > EPS;}int main(){cin>>N>>W;for(int i = 0;i < N;++i){double v,h;cin>>v>>h;stu.push_back({v,h});}sort(stu.begin(),stu.end(),cmp);double total = 0,countW = 0;for(int i = 0;i < N;++i){if(countW + stu[i].second <= W){total += stu[i].first;countW += stu[i].second;}else{total += (stu[i].first/stu[i].second)*(W - countW);break;}}cout<<fixed<<setprecision(1)<<total<<endl;return 0;}
方法二:
重载小于号操作:按照价值/重量比大的排序
首先可以整箱整箱的拿走,最后不能整箱拿,就拿剩下的一部分(就结束了)
using namespace std;const double eps = 1e-6;struct Candy{int v;int w;bool operator < (const Candy & c)const{return double(v)/w - double(c.v)/c.w > eps;}}candies[110];int main(){int n,w;cin>>n>>w;for(int i = 0;i < n;++i)cin>>candies[i].v>>candies[i].w;sort(candies,candies+n);int totalW = 0;double totalV = 0;for(int i = 0;i < n;++i){if(totalW + candies[i].w <= w){totalW += candies[i].w;totalV += candies[i].v;}else{//计算到最后结束,整箱装不进去,或者已经满了totalV += candies[i].v*double(w - totalW)/candies[i].w;//结束操作break;}}cout<<fixed<<setprecision(1)<<totalV<<endl;return 0;}


4151:电影节
总时间限制: 1000ms内存限制: 65536kB
描述
大学生电影节在北大举办! 这天,在北大各地放了多部电影,给定每部电影的放映时间区间,区间重叠的电影不可能同时看(端点可以重合),问李雷最多可以看多少部电影。
输入
多组数据。每组数据开头是n(n<=100),表示共n场电影。
接下来n行,每行两个整数(0到1000之间),表示一场电影的放映区间
n=0则数据结束输出
对每组数据输出最多能看几部电影
样例输入
8
3 4
0 7
3 8
15 19
15 20
10 15
8 18
6 12
0样例输出
3

解析:注意题目是多组数据,定义一个用来存储电影的集合,根据电影的结束时间从小到大排序,从前向后取时间不冲突的电影。(存储电影的数组不能设置为全局变量容易和其他组的数据冲突,输入的结束条件是N为0)。这里设置一个while循环来测试每组数据 首先输入的有多少电影 N为0 即如果某组数据电影数量为0结束循环
贪心解法:
将所有电影按结束时间从小到大排序,第一步选结束时间最早的那部电影。然后,每步都选和上一步选中的电影不冲突且结束时间最早的电影。
复杂度:O(NlogN)
证明:
替换法。假设用贪心法挑选的电影序列为:
a1,a2....
不用此法挑选的最长的电影序列为:
b1,b2....
现可证明,对任意i,bi均可以替换成ai
用S(x)表示x开始时间,E(x)表示x结束时间,则:

using namespace std;using pii = pair<int,int>;//按照电影的结束时间排序bool cmp(pii & a,pii & b){return a.second < b.second;}int main(){int N;while (true){cin>>N;if(N== 0)break;vector<pii> stu;for(int i = 0;i < N;++i){int s,e;cin>>s>>e;stu.push_back({s,e});}sort(stu.begin(),stu.end(),cmp);int ans = 1,countEnd = stu[0].second;for(int i = 1;i < stu.size();++i){if(stu[i].first >= countEnd){countEnd = stu[i].second;ans++;}}cout<<ans<<endl;}return 0;}





贪心解法:
所有奶牛都必须挤奶。到了一个奶牛的挤奶开始时间,就必须为这个奶牛找畜栏。因此按照奶牛的开始时间逐个处理它们,是必然的。
S(x)表示奶牛x的开始时间。E(x)表示x的结束时间。对E(x),x可以是奶牛,也可以是畜栏。畜栏的结束时间,就是正在其里面挤奶的奶牛的结束时间。同一个畜栏的结束时间是不断在变的。


这里定义一个结构体来存储奶牛的开始和结束时间,该奶牛的编号,一个结构体用来定义畜栏的结束时间以及畜栏的编号。
用数组来存储编号为i的奶牛对应的畜栏编号。畜栏从1开始编号。
using namespace std;struct Cow{//挤奶区间起终点int a,b;int No;//编号//按照奶牛挤奶 开始时间排序bool operator < (const Cow & c)const{return a < c.a;}}cows[50100];//pos[i]表示编号为i的奶牛去的畜栏编号int pos[50100];struct Stall{//结束时间int end;//编号int No;//畜栏结束的时间从小到大排序//这里的有限队列是最大堆 因此需要改成最小堆bool operator< (const Stall & s)const{return end > s.end;}Stall(int e,int n):end(e),No(n){}};int main(){int n;cin>>n;for(int i = 0;i < n;++i){//每个牛的起始时间 ,另外是第i头牛的编号cin>>cows[i].a>>cows[i].b;cows[i].No = i;}sort(cows,cows+n);int total = 0;//畜栏 编号priority_queue<Stall> pq;//每次进入畜栏都要存储指定牛所在的畜栏for(int i = 0;i < n;++i){//畜栏是空的选择几号畜栏都可以 (可以当做初始化条件)if(pq.empty()){//首先第一头牛入队列 ,即开始时间最早的先挤奶++total;pq.push(Stall(cows[i].b,total));//第No头牛所在的畜栏号pos[cows[i].No] = total;}else{ //如果畜栏中有奶牛挤奶,查看结束时间最早的是否小于这头//正要挤奶的牛 开始时间 ,如果可以的话,这头牛就进入这个畜栏Stall st = pq.top();//查看下一个牛的开始时间是否小于最小堆的结束时间if(st.end < cows[i].a){pq.pop();pos[cows[i].No] = st.No;//存入新的结束时间(更改结束时间)pq.push(Stall(cows[i].b,st.No));}//如果不可以的话就进入新的畜栏else{++total;pq.push(Stall(cows[i].b,total));pos[cows[i].No] = total;}}}cout<<total<<endl;//输出每头牛的畜栏编号for(int i = 0;i < n;++i)cout<<pos[i]<<endl;return 0;}
1328:Radar Installation
总时间限制: 1000ms内存限制:65536kB
描述
Assume the coasting is an infinite straight line. Land is in one side of coasting, sea in the other. Each small island is a point locating in the sea side. And any radar installation, locating on the coasting, can only cover d distance, so an island in the sea can be covered by a radius installation, if the distance between them is at most d.
We use Cartesian coordinate system, defining the coasting is the x-axis. The sea side is above x-axis, and the land side below. Given the position of each island in the sea, and given the distance of the coverage of the radar installation, your task is to write a program to find the minimal number of radar installations to cover all the islands. Note that the position of an island is represented by its x-y coordinates.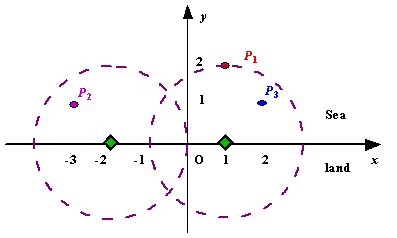
Figure A Sample Input of Radar Installations输入
The input consists of several test cases. The first line of each case contains two integers n (1<=n<=1000) and d, where n is the number of islands in the sea and d is the distance of coverage of the radar installation. This is followed by n lines each containing two integers representing the coordinate of the position of each island. Then a blank line follows to separate the cases.
The input is terminated by a line containing pair of zeros输出
For each test case output one line consisting of the test case number followed by the minimal number of radar installations needed. "-1" installation means no solution for that case.
样例输入
3 2
1 2
-3 1
2 1
1 2
0 2
0 0样例输出
Case 1: 2
Case 2: 1

解析:如果找到一个雷达同时覆盖多个区间,那么把这多个区间按起点坐标从小到大排序,则最后一个区间(起点最靠右的)k的起点,就能覆盖所有区间。
证明:如果它不能覆盖某个区间x,那么它必然位于
1)x起点的左边
或者
2)x终点的右边。
情况1)和k的起点是最靠右的矛盾
情况2)如果发生,则不可能找到一个点同时覆盖x和k,也和前提矛盾
有了这个结论,就可以只挑区间的起点来放置雷达了。
贪心算法:
1)将所有区间按照起点从小到大排序,编号0 到 (n-1)
2) 依次考察每个区间的起点,看要不要在那里放雷达。开始,所有区间都没被覆盖,所以目前编号最小的未被覆盖的区间的编号为
firstNoConverd = 0
3)考察一个区间i的起点xi的时候,要看从firstNoConverd到区间i-1中是否存在某个区间c,没有被xi覆盖。如果没有,则先不急于在xi放雷达,接着往下看。如果有,那么c的终点肯定在xi的左边,因此不可能用同一个雷达覆盖c和i。即能覆盖c的点,已经不可能覆盖i和i后面的区间了。此时,为了覆盖c,必须放一个雷达了,放在区间i-1的起点即可覆盖所有从firstNoConverd到i-1的区间。因为当初考察i-1的起点z时候,并没有发现z漏覆盖了从firstNoConverd到i-2之间的任何一个区间。
4)放完雷达后,将firstNoConverd改为i,再做下去。


注意如果岛屿到海岸线的距离超过了雷达所能覆盖的最大范围则输出-1。另外还要判断结束条件 0 0;这里用flag标致在这些岛屿中是否到海岸线的距离超出范围。勾股定理求出雷达作用的范围(即以岛屿为圆心,d为半径,与海岸线的两个交点。在这两个交点所能组成的区间内雷达放在里面就可以覆盖岛屿)。
using namespace std;struct node{double s,e;bool operator < (const node & n)const{return s < n.s;}}Stall[1100];int main(){int n,d;int t = 0;while(cin>>n>>d && n ){t++;int flag = 0;for(int i = 0;i < n;i++){double x,y;cin>>x>>y;//岛屿到平面的距离超过了雷达的距离if(y > d){flag = 1;}//勾股定理求出雷达的范围double x1 = sqrt(d*d - y*y);Stall[i].s = x - x1;Stall[i].e = x + x1;}if(flag){cout<<"Case "<<t<<": "<<"-1"<<endl;continue;}//按照起点从小到大排序sort(Stall,Stall+n);//从第一个岛屿判断(最右边的端点作为判断条件)double firstNoConverd = Stall[0].e;int ans = 1;for(int i = 1;i < n;++i){//如果下一个岛屿的最左端在firstNoConverd的左边那么可以被前一个雷达覆盖不用在加雷达if(Stall[i].s <= firstNoConverd){//这个时候还要判断这个岛屿的范围//如果它的右端点在前一个右端点的前面那么这个firstNoConverd要更新firstNoConverd = firstNoConverd < Stall[i].e ? firstNoConverd : Stall[i].e;}else{ //到该岛屿不能被上一个覆盖的时候用新的雷达firstNoConverd = Stall[i].e;ans++;}}cout<<"Case "<<t<<": "<<ans<<endl;}return 0;}
1042:Gone Fishing
总时间限制: 2000ms内存限制: 65536kB
描述
John is going on a fishing trip. He has h hours available (1 <= h <= 16), and there are n lakes in the area (2 <= n <= 25) all reachable along a single, one-way road. John starts at lake 1, but he can finish at any lake he wants. He can only travel from one lake to the next one, but he does not have to stop at any lake unless he wishes to. For each i = 1,...,n - 1, the number of 5-minute intervals it takes to travel from lake i to lake i + 1 is denoted ti (0 < ti <=192). For example, t3 = 4 means that it takes 20 minutes to travel from lake 3 to lake 4. To help plan his fishing trip, John has gathered some information about the lakes. For each lake i, the number of fish expected to be caught in the initial 5 minutes, denoted fi( fi >= 0 ), is known. Each 5 minutes of fishing decreases the number of fish expected to be caught in the next 5-minute interval by a constant rate of di (di >= 0). If the number of fish expected to be caught in an interval is less than or equal to di , there will be no more fish left in the lake in the next interval. To simplify the planning, John assumes that no one else will be fishing at the lakes to affect the number of fish he expects to catch.
Write a program to help John plan his fishing trip to maximize the number of fish expected to be caught. The number of minutes spent at each lake must be a multiple of 5.输入
You will be given a number of cases in the input. Each case starts with a line containing n. This is followed by a line containing h. Next, there is a line of n integers specifying fi (1 <= i <=n), then a line of n integers di (1 <=i <=n), and finally, a line of n - 1 integers ti (1 <=i <=n - 1). Input is terminated by a case in which n = 0.
输出
For each test case, print the number of minutes spent at each lake, separated by commas, for the plan achieving the maximum number of fish expected to be caught (you should print the entire plan on one line even if it exceeds 80 characters). This is followed by a line containing the number of fish expected.
If multiple plans exist, choose the one that spends as long as possible at lake 1, even if no fish are expected to be caught in some intervals. If there is still a tie, choose the one that spends as long as possible at lake 2, and so on. Insert a blank line between cases.样例输入
2
1
10 1
2 5
2
4
4
10 15 20 17
0 3 4 3
1 2 3
4
4
10 15 50 30
0 3 4 3
1 2 3
0样例输出
45, 5
Number of fish expected: 31
240, 0, 0, 0
Number of fish expected: 480
115, 10, 50, 35
Number of fish expected: 724

难点:
走路时间可多可少,不知道到底该花多长时间纯钓鱼才最好(可能有好湖在很右边)。
解决:
枚举最终停下来的湖,将方案分成n类。每类方案的走路时间就是确定的。在每类方案里找最优解,然后再优中选优。
贪心算法:
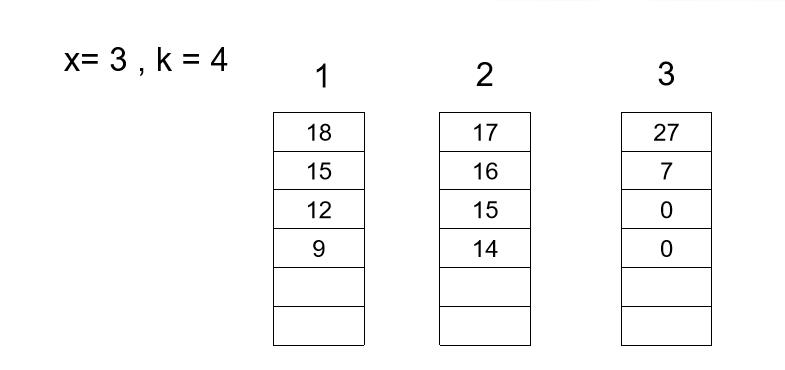
在确定停下来的湖是x的情况下,假定纯钓鱼时间是k个时间片。
用三元组(F,I,J)(1 <= i <= x,1 <= j <= k)表示湖i的第j个时间片能够钓的鱼的数目是F
将所有的(F,I,J)(共x*k个)按F值从大到小排序,选前k个,就构成了最佳钓鱼方案
Presentation Error 提交了好多次亦然没有通过,这个原因是因为每组测试结果输出完成之后。每组结果之间还要有一个换行,即每组结果要空一行分隔开!!!!!
输入 :湖的个数
给的时间(钓鱼和走路)
每个湖的最大钓鱼量(第一个时间片的)
每个湖的每次钓鱼减少的鱼量(每次少多少)
相邻湖之间的时间(从第i个湖到第i+1个湖的走路时间)
输出:最大钓鱼量
每个湖所呆的时间
空格
。。下一组数据的结果(即每组结果要空一行)
解析:从最左端开始枚举湖的终点,因此可以把花费的走路时间先计算出来。剩下的时间就都是钓鱼的时间了。采用优先队列进行存储每个湖的鱼量,每次选鱼量最大的湖,直到时间用完。用test数组存储测试的时候每个湖所耗费的时间。每次枚举,对每次情况的最大钓鱼量进行比较,选择最大的钓鱼量,和存储时间的测试数组。
对于走路的时间怎么处理,这里直接从第一个湖开始枚举,先减去走路的时间,剩下的时间片就是钓鱼的时间片了。用for循环来判断每个时间片在哪个湖钓鱼即可。每次向后枚举一个湖,就减去一个走路时间,(这里的湖是从左到右排开的有顺序的,可以经过这个湖不钓鱼)。在选择哪个湖钓鱼的时候湖的顺序按照鱼量从大到小排列(如果数量相同,按照从顺序从小到大,即从左到右的顺序选择)。
如果有多种方案,则优先选择在第一个湖呆时间最长的。如果还有多种,则优先选择在第二个湖呆的时间最长的。。(这就是排序的依据)
优先队列默认按照从大到小排列,这里要重载小于号,来满足输出要求
using namespace std;//每个湖第一个时间片的钓鱼量f[i], 每次减少d[i],湖之间的距离dis[i]int f[1000],d[1000],t[1000];int result[1000];//结果存储最后每个湖呆的时间//测试结果 用来保存每次测试时(各个湖所呆的时间)int testTime[1000];int testCount;//测试的最大钓鱼量struct node{int id;int num;};bool operator<(const node & a,const node & b){if(a.num == b.num)return a.id > b.id;elsereturn a.num < b.num;}int main(){//n个湖,钓鱼的时间hint n;while (cin>>n && n){int maxresult;//结果存储最大的钓鱼量maxresult = -1;int timeNum;cin>>timeNum;//将小时转换成时间片 1个小时12个时间片timeNum *= 12;for(int i = 0;i < n;++i)cin>>f[i];for(int i = 0;i < n;++i)cin>>d[i];for(int i = 0;i < n-1;++i)cin>>t[i];//枚举第i个湖为终点for(int i = 0;i < n;++i){//测试数组memset(testTime,0,sizeof(testTime));testCount = 0;//去除走路时间 (这里保留的是钓鱼的时间)if(i>0)timeNum -= t[i-1];//保存每个湖的最大钓鱼量priority_queue<node> pq;//初始化最大钓鱼量for(int j = 0;j <= i;++j){node xx;xx.id = j;xx.num = f[j];pq.push(xx);}//剩下的时间片 ,每个时间片选取最大的鱼量for(int j = 0;j < timeNum;j++){node v = pq.top();pq.pop();//每个湖呆的时间testTime[v.id] += 5;//最大钓鱼量testCount += v.num;//这里的钓完之后鱼量可能为负数v.num -= d[v.id];if(v.num < 0)v.num = 0;//改湖的鱼量减少d[i]pq.push(v);}//选取最大的钓鱼量if(maxresult < testCount){maxresult = testCount;//结果数组重新赋值for(int j = 0;j < n;j++)result[j] = testTime[j];}}cout<<result[0];for(int j = 1;j < n;++j)cout<<", "<<result[j];cout<<endl;cout<<"Number of fish expected: "<<maxresult<<endl;//注意每组数据之间有一空行!!!!cout<<endl;}return 0;}
以上是关于GreedyAlgorithm(贪心算法)的主要内容,如果未能解决你的问题,请参考以下文章