大数据实战Flume+Kafka+Spark+Spring Boot 统计网页访问量项目
Posted 大数据肌肉猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实战Flume+Kafka+Spark+Spring Boot 统计网页访问量项目相关的知识,希望对你有一定的参考价值。
1.需求说明
1.1 需求
到现在为止的网页访问量
到现在为止从搜索引擎引流过来的网页访问量
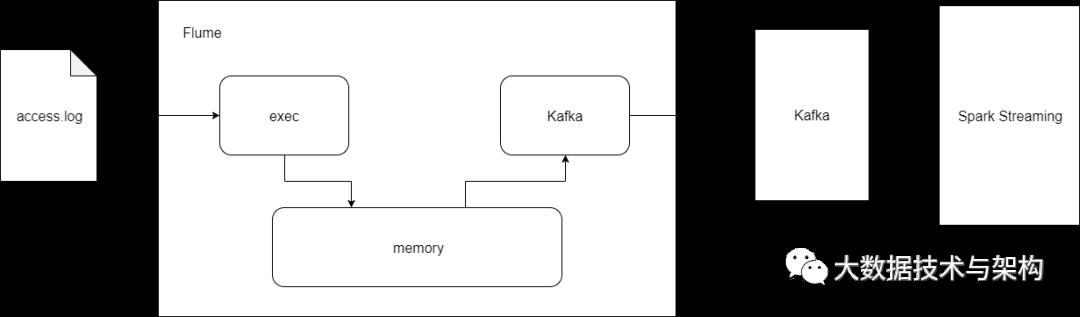
项目总体框架如图所示:
1.2 用户行为日志内容
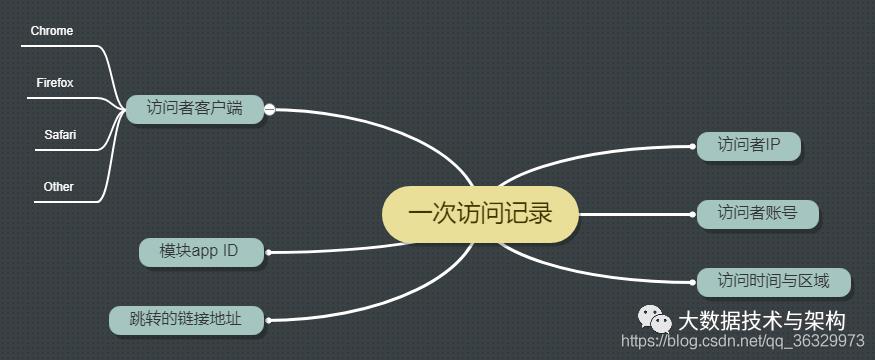
2.模拟日志数据制作
用Python制作模拟数据,数据包含:
不同的搜索关键词->search_keyword
不同的状态码->status_codes
#coding=UTF-8import randomimport timeurl_paths = ["class/112.html","class/128.html","class/145.html","class/146.html","class/131.html","class/130.html","class/145.html","learn/821.html","learn/825.html","course/list"]http_refers=["http://www.baidu.com/s?wd={query}","https://www.sogou.com/web?query={query}","http://cn.bing.com/search?q={query}","http://search.yahoo.com/search?p={query}",]search_keyword = ["Spark+Sql","Hadoop","Storm","Spark+Streaming","大数据","面试"]status_codes = ["200","404","500"]ip_slices = [132,156,132,10,29,145,44,30,21,43,1,7,9,23,55,56,241,134,155,163,172,144,158]def sample_url():return random.sample(url_paths,1)[0]def sample_ip():slice = random.sample(ip_slices,4)return ".".join([str(item) for item in slice])def sample_refer():if random.uniform(0,1) > 0.2:return "-"refer_str = random.sample(http_refers,1)query_str = random.sample(search_keyword,1)return refer_str[0].format(query=query_str[0])def sample_status():return random.sample(status_codes,1)[0]def generate_log(count = 10):time_str = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())f = open("/home/hadoop/tpdata/project/logs/access.log","w+")while count >= 1:query_log = "{ip}\t{local_time}\t\"GET /{url} HTTP/1.1\"\t{status}\t{refer}".format(local_time=time_str,url=sample_url(),ip=sample_ip(),refer=sample_refer(),status=sample_status())print(query_log)f.write(query_log + "\n")count = count - 1if __name__ == '__main__':generate_log(100)
使用Linux Crontab定时调度工具,使其每一分钟产生一批数据。
表达式:
*/1 * * * *编写python运行脚本:
vi log_generator.shpython /home/hadoop/tpdata/log.pychmod u+x log_generator.sh
配置Crontab:
crontab -e*/1 * * * * /home/hadoop/tpdata/project/log_generator.sh
2.Flume实时收集日志信息
开发时选型:
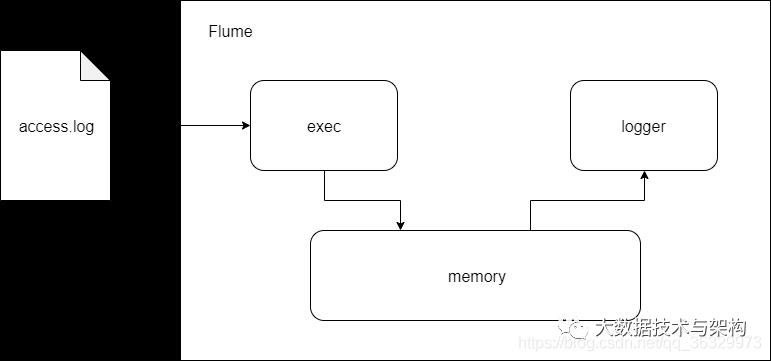
编写streaming_project.conf:
vi streaming_project.confexec-memory-logger.sources = exec-sourceexec-memory-logger.sinks = logger-sinkexec-memory-logger.channels = memory-channelexec-memory-logger.sources.exec-source.type = execexec-memory-logger.sources.exec-source.command = tail -F /home/hadoop/tpdata/project/logs/access.logexec-memory-logger.sources.exec-source.shell = /bin/sh -cexec-memory-logger.channels.memory-channel.type = memoryexec-memory-logger.sinks.logger-sink.type = loggerexec-memory-logger.sources.exec-source.channels = memory-channelexec-memory-logger.sinks.logger-sink.channel = memory-channel
flume-ng agent \--name exec-memory-logger \--conf $FLUME_HOME/conf \--conf-file /home/hadoop/tpdata/project/streaming_project.conf \-Dflume.root.logger=INFO,console
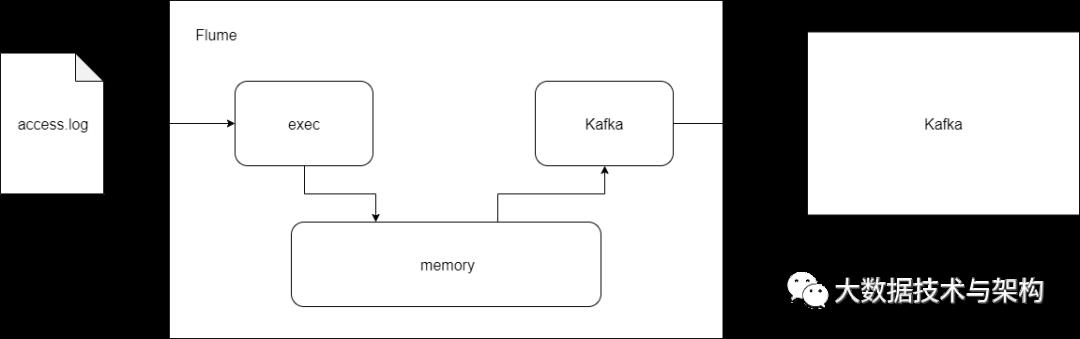
./zkServer.sh start./kafka-server-start.sh -daemon $KAFKA_HOME/config/server.propertiesbroker.id=0############################# Socket Server Settings #############################listeners=PLAINTEXT://:9092host.name=hadoop000advertised.host.name=192.168.1.9advertised.port=9092num.network.threads=3num.io.threads=8socket.send.buffer.bytes=102400socket.receive.buffer.bytes=102400socket.request.max.bytes=104857600############################# Log Basics #############################log.dirs=/home/hadoop/app/tmp/kafka-logsnum.partitions=1num.recovery.threads.per.data.dir=1############################# Log Retention Policy #############################log.retention.hours=168log.segment.bytes=1073741824log.retention.check.interval.ms=300000log.cleaner.enable=false############################# Zookeeper #############################zookeeper.connect=hadoop000:2181zookeeper.connection.timeout.ms=6000
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic streamingtopicvi streaming_project2.confexec-memory-kafka.sources = exec-sourceexec-memory-kafka.sinks = kafka-sinkexec-memory-kafka.channels = memory-channelexec-memory-kafka.sources.exec-source.type = execexec-memory-kafka.sources.exec-source.command = tail -F /home/hadoop/tpdata/project/logs/access.logexec-memory-kafka.sources.exec-source.shell = /bin/sh -cexec-memory-kafka.channels.memory-channel.type = memoryexec-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSinkexec-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092exec-memory-kafka.sinks.kafka-sink.topic = streamingtopicexec-memory-kafka.sinks.kafka-sink.batchSize = 5exec-memory-kafka.sinks.kafka-sink.requiredAcks = 1exec-memory-kafka.sources.exec-source.channels = memory-channelexec-memory-kafka.sinks.kafka-sink.channel = memory-channel
flume-ng agent \--name exec-memory-kafka \--conf $FLUME_HOME/conf \--conf-file /home/hadoop/tpdata/project/streaming_project2.conf \-Dflume.root.logger=INFO,console
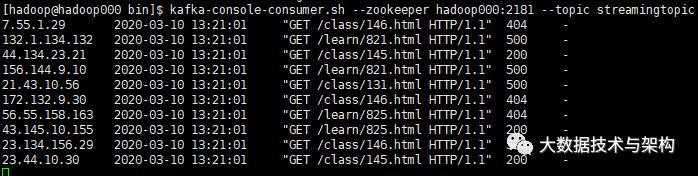
4.Spark Streaming对接Kafka对数据消费
4.1 pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.taipark.spark</groupId><artifactId>sparktrain</artifactId><version>1.0</version><inceptionYear>2008</inceptionYear><properties><scala.version>2.11.8</scala.version><kafka.version>0.9.0.0</kafka.version><spark.version>2.2.0</spark.version><hadoop.version>2.6.0-cdh5.7.0</hadoop.version><hbase.version>1.2.0-cdh5.7.0</hbase.version></properties><repositories><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos</url></repository></repositories><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!--<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.11</artifactId><version>${kafka.version}</version></dependency>--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-8_2.11</artifactId><version>2.2.0</version></dependency><!--SS整合Flume依赖--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-flume_2.11</artifactId><version>${spark.version}</version></dependency><!--SS整合sink依赖--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-flume-sink_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>3.5</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.13</version></dependency><dependency><groupId>com.fasterxml.jackson.module</groupId><artifactId>jackson-module-scala_2.11</artifactId><version>2.6.5</version></dependency><dependency><groupId>net.jpountz.lz4</groupId><artifactId>lz4</artifactId><version>1.3.0</version></dependency><dependency><groupId>org.apache.flume.flume-ng-clients</groupId><artifactId>flume-ng-log4jappender</artifactId><version>1.6.0</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory><testSourceDirectory>src/test/scala</testSourceDirectory><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions><configuration><scalaVersion>${scala.version}</scalaVersion><args><arg>-target:jvm-1.5</arg></args></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-eclipse-plugin</artifactId><configuration><downloadSources>true</downloadSources><buildcommands><buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand></buildcommands><additionalProjectnatures><projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature></additionalProjectnatures><classpathContainers><classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer><classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer></classpathContainers></configuration></plugin></plugins></build><reporting><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><configuration><scalaVersion>${scala.version}</scalaVersion></configuration></plugin></plugins></reporting></project>
4.2 连通Kafka
新建Scala文件——WebStatStreamingApp.scala,首先使用Direct模式连通Kafka:
package com.taipark.spark.projectimport kafka.serializer.StringDecoderimport org.apache.spark.SparkConfimport org.apache.spark.streaming.kafka.KafkaUtilsimport org.apache.spark.streaming.{Seconds, StreamingContext}/*** 使用Spark Streaming消费Kafka的数据*/object WebStatStreamingApp {def main(args: Array[String]): Unit = {if(args.length != 2){System.err.println("Userage:WebStatStreamingApp <brokers> <topics>");System.exit(1);}val Array(brokers,topics) = argsval sparkConf = new SparkConf().setAppName("WebStatStreamingApp").setMaster("local[2]")val ssc = new StreamingContext(sparkConf,Seconds(60))val kafkaParams = Map[String,String]("metadata.broker.list"-> brokers)val topicSet = topics.split(",").toSetval messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topicSet)messages.map(_._2).count().print()ssc.start()ssc.awaitTermination()}}
hadoop000:9092 streamingtopic在本地测试是否连通:
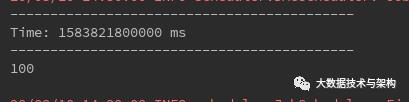
连通成功,可以开始编写业务代码完成数据清洗(ETL)。
4.3 ETL
新建工具类DateUtils.scala:
package com.taipark.spark.project.utilsimport java.util.Dateimport org.apache.commons.lang3.time.FastDateFormat/*** 日期时间工具类*/object DateUtils {val YYYYMMDDHHMMSS_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")val TARGET_FORMAT = FastDateFormat.getInstance("yyyyMMddHHmmss")def getTime(time:String)={YYYYMMDDHHMMSS_FORMAT.parse(time).getTime}def parseToMinute(time:String)={TARGET_FORMAT.format(new Date(getTime(time)))}def main(args: Array[String]): Unit = {// println(parseToMinute("2020-03-10 15:00:05"))}}
package com.taipark.spark.project.domian/*** 清洗后的日志信息*/case class ClickLog(ip:String,time:String,courseId:Int,statusCode:Int,referer:String)
修改WebStatStreamingApp.scala:
package com.taipark.spark.project.sparkimport com.taipark.spark.project.domian.ClickLogimport com.taipark.spark.project.utils.DateUtilsimport kafka.serializer.StringDecoderimport org.apache.spark.SparkConfimport org.apache.spark.streaming.kafka.KafkaUtilsimport org.apache.spark.streaming.{Seconds, StreamingContext}/*** 使用Spark Streaming消费Kafka的数据*/object WebStatStreamingApp {def main(args: Array[String]): Unit = {if(args.length != 2){System.err.println("Userage:WebStatStreamingApp <brokers> <topics>");System.exit(1);}val Array(brokers,topics) = argsval sparkConf = new SparkConf().setAppName("WebStatStreamingApp").setMaster("local[2]")val ssc = new StreamingContext(sparkConf,Seconds(60))val kafkaParams = Map[String,String]("metadata.broker.list"-> brokers)val topicSet = topics.split(",").toSetval messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topicSet)//messages.map(_._2).count().print()//ETL// 30.163.55.7 2020-03-10 14:32:01 "GET /class/112.html HTTP/1.1" 404 http://www.baidu.com/s?wd=Hadoopval logs = messages.map(_._2)val cleanData = logs.map(line => {val infos = line.split("\t")//infos(2) = "GET /class/112.html HTTP/1.1"val url = infos(2).split(" ")(1)var courseId = 0//拿到课程编号if(url.startsWith("/class")){val courseIdHTML = url.split("/")(2)courseId = courseIdHTML.substring(0,courseIdHTML.lastIndexOf(".")).toInt}ClickLog(infos(0),DateUtils.parseToMinute(infos(1)),courseId,infos(3).toInt,infos(4))}).filter(clicklog => clicklog.courseId != 0)cleanData.print()ssc.start()ssc.awaitTermination()}}
run起来测试一下:
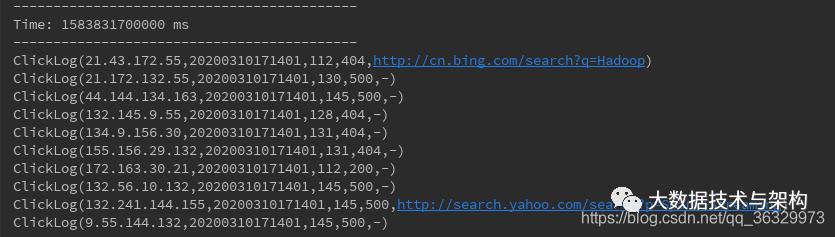
ETL完成。
4.4 功能一:到现在为止某网站的访问量
使用数据库来存储统计结果,可视化前端根据yyyyMMdd courseid把数据库里的结果展示出来。
选择HBASE作为数据库。要启动HDFS与Zookeeper。
启动HDFS:
./start-dfs.sh./start-hbase.sh./hbase shelllist
create 'web_course_clickcount','info'hbase(main):008:0> desc 'web_course_clickcount'Table web_course_clickcount is ENABLEDweb_course_clickcountCOLUMN FAMILIES DESCRIPTION{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}1 row(s) in 0.1650 seconds
day_courseid使用Scala来操作HBASE:
新建网页点击数实体类 CourseClickCount.scala:
package com.taipark.spark.project.domian/*** 课程网页点击数* @param day_course HBASE中的rowkey* @param click_count 对应的点击总数*/case class CourseClickCount(day_course:String,click_count:Long)
package com.taipark.spark.project.daoimport com.taipark.spark.project.domian.CourseClickCountimport scala.collection.mutable.ListBufferobject CourseClickCountDAO {val tableName = "web_course_clickcount"val cf = "info"val qualifer = "click_count"/*** 保存数据到HBASE* @param list*/def save(list:ListBuffer[CourseClickCount]): Unit ={}/*** 根据rowkey查询值* @param day_course* @return*/def count(day_course:String):Long={0l}}
利用Java实现HBaseUtils打通其与HBASE:
package com.taipark.spark.project.utils;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.client.HBaseAdmin;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;/*** HBase操作工具类:Java工具类采用单例模式封装*/public class HBaseUtils {HBaseAdmin admin = null;Configuration configuration = null;//私有构造方法(单例模式)private HBaseUtils(){configuration = new Configuration();configuration.set("hbase.zookeeper.quorum","hadoop000:2181");configuration.set("hbase.rootdir","hdfs://hadoop000:8020/hbase");try {admin = new HBaseAdmin(configuration);} catch (IOException e) {e.printStackTrace();}}private static HBaseUtils instance = null;public static synchronized HBaseUtils getInstance(){if(instance == null){instance = new HBaseUtils();}return instance;}//根据表名获取HTable实例public HTable getTable(String tableName){HTable table = null;try {table = new HTable(configuration,tableName);} catch (IOException e) {e.printStackTrace();}return table;}/*** 添加一条记录到HBASE表* @param tableName 表名* @param rowkey 表rowkey* @param cf 表的columnfamily* @param column 表的列* @param value 写入HBASE的值*/public void put(String tableName,String rowkey,String cf,String column,String value){HTable table = getTable(tableName);Put put = new Put(Bytes.toBytes(rowkey));put.add(Bytes.toBytes(cf),Bytes.toBytes(column),Bytes.toBytes(value));try {table.put(put);} catch (IOException e) {e.printStackTrace();}}public static void main(String[] args) {// HTable hTable = HBaseUtils.getInstance().getTable("web_course_clickcount");// System.out.println(hTable.getName().getNameAsString());String tableName = "web_course_clickcount";String rowkey = "20200310_88";String cf = "info";String column = "click_count";String value = "2";HBaseUtils.getInstance().put(tableName,rowkey,cf,column,value);}}
测试运行:
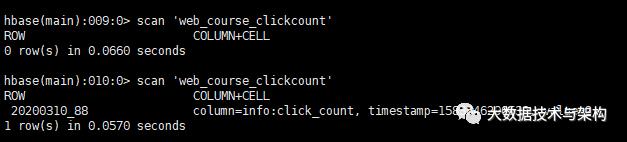
测试工具类成功后继续编写DAO的代码:
package com.taipark.spark.project.daoimport com.taipark.spark.project.domian.CourseClickCountimport com.taipark.spark.project.utils.HBaseUtilsimport org.apache.hadoop.hbase.client.Getimport org.apache.hadoop.hbase.util.Bytesimport scala.collection.mutable.ListBufferobject CourseClickCountDAO {val tableName = "web_course_clickcount"val cf = "info"val qualifer = "click_count"/*** 保存数据到HBASE* @param list*/def save(list:ListBuffer[CourseClickCount]): Unit ={val table = HBaseUtils.getInstance().getTable(tableName)for(ele <- list){table.incrementColumnValue(Bytes.toBytes(ele.day_course),Bytes.toBytes(cf),Bytes.toBytes(qualifer),ele.click_count)}}/*** 根据rowkey查询值* @param day_course* @return*/def count(day_course:String):Long={val table = HBaseUtils.getInstance().getTable(tableName)val get = new Get(Bytes.toBytes(day_course))val value = table.get(get).getValue(cf.getBytes,qualifer.getBytes)if (value == null){0L}else{Bytes.toLong(value)}}def main(args: Array[String]): Unit = {val list = new ListBuffer[CourseClickCount]list.append(CourseClickCount("2020311_8",8))list.append(CourseClickCount("2020311_9",9))list.append(CourseClickCount("2020311_10",1))list.append(CourseClickCount("2020311_2",15))save(list)}}
scan 'web_course_clickcount'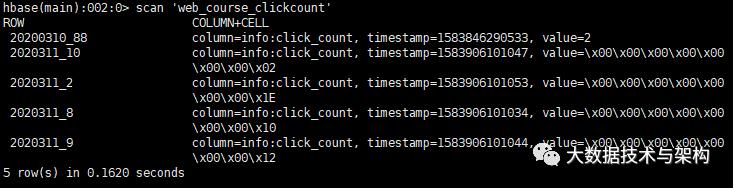
package com.taipark.spark.project.sparkimport com.taipark.spark.project.dao.CourseClickCountDAOimport com.taipark.spark.project.domian.{ClickLog, CourseClickCount}import com.taipark.spark.project.utils.DateUtilsimport kafka.serializer.StringDecoderimport org.apache.spark.SparkConfimport org.apache.spark.streaming.kafka.KafkaUtilsimport org.apache.spark.streaming.{Seconds, StreamingContext}import scala.collection.mutable.ListBuffer/*** 使用Spark Streaming消费Kafka的数据*/object WebStatStreamingApp {def main(args: Array[String]): Unit = {if(args.length != 2){System.err.println("Userage:WebStatStreamingApp <brokers> <topics>");System.exit(1);}val Array(brokers,topics) = argsval sparkConf = new SparkConf().setAppName("WebStatStreamingApp").setMaster("local[2]")val ssc = new StreamingContext(sparkConf,Seconds(60))val kafkaParams = Map[String,String]("metadata.broker.list"-> brokers)val topicSet = topics.split(",").toSetval messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topicSet)//messages.map(_._2).count().print()//ETL// 30.163.55.7 2020-03-10 14:32:01 "GET /class/112.html HTTP/1.1" 404 http://www.baidu.com/s?wd=Hadoopval logs = messages.map(_._2)val cleanData = logs.map(line => {val infos = line.split("\t")//infos(2) = "GET /class/112.html HTTP/1.1"val url = infos(2).split(" ")(1)var courseId = 0//拿到课程编号if(url.startsWith("/class")){val courseIdHTML = url.split("/")(2)courseId = courseIdHTML.substring(0,courseIdHTML.lastIndexOf(".")).toInt}ClickLog(infos(0),DateUtils.parseToMinute(infos(1)),courseId,infos(3).toInt,infos(4))}).filter(clicklog => clicklog.courseId != 0)// cleanData.print()cleanData.map(x => {//HBase rowkey设计:20200311_9((x.time.substring(0,8)) + "_" + x.courseId,1)}).reduceByKey(_+_).foreachRDD(rdd =>{rdd.foreachPartition(partitionRecords =>{val list = new ListBuffer[CourseClickCount]partitionRecords.foreach(pair =>{list.append(CourseClickCount(pair._1,pair._2))})CourseClickCountDAO.save(list)})})ssc.start()ssc.awaitTermination()}}
测试:
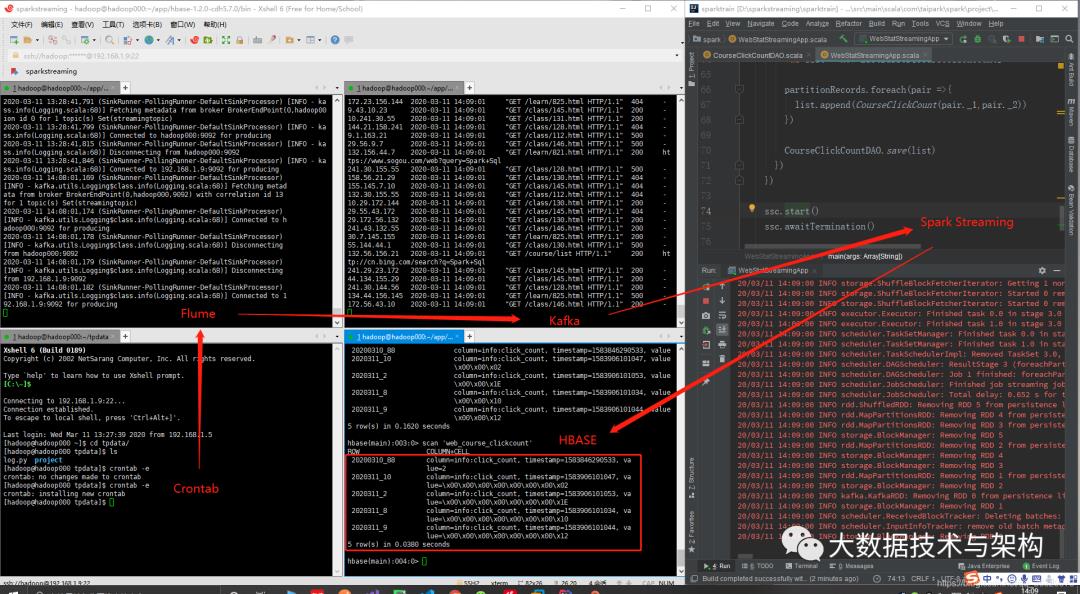
4.5 功能二:到现在为止某网站的搜索引擎引流访问量
HBASE表设计:
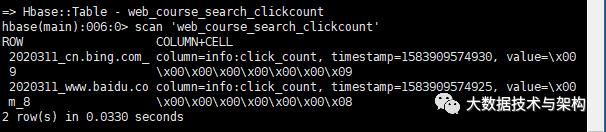
create 'web_course_search_clickcount','info'day_search_1package com.taipark.spark.project.domian/*** 网站从搜索引擎过来的点击数实体类* @param day_search_course* @param click_count*/case class CourseSearchClickCount (day_search_course:String,click_count:Long)
package com.taipark.spark.project.daoimport com.taipark.spark.project.domian.{CourseClickCount, CourseSearchClickCount}import com.taipark.spark.project.utils.HBaseUtilsimport org.apache.hadoop.hbase.client.Getimport org.apache.hadoop.hbase.util.Bytesimport scala.collection.mutable.ListBufferobject CourseSearchClickCountDAO {val tableName = "web_course_search_clickcount"val cf = "info"val qualifer = "click_count"/*** 保存数据到HBASE* @param list*/def save(list:ListBuffer[CourseSearchClickCount]): Unit ={val table = HBaseUtils.getInstance().getTable(tableName)for(ele <- list){table.incrementColumnValue(Bytes.toBytes(ele.day_search_course),Bytes.toBytes(cf),Bytes.toBytes(qualifer),ele.click_count)}}/*** 根据rowkey查询值* @param day_search_course* @return*/def count(day_search_course:String):Long={val table = HBaseUtils.getInstance().getTable(tableName)val get = new Get(Bytes.toBytes(day_search_course))val value = table.get(get).getValue(cf.getBytes,qualifer.getBytes)if (value == null){0L}else{Bytes.toLong(value)}}def main(args: Array[String]): Unit = {val list = new ListBuffer[CourseSearchClickCount]list.append(CourseSearchClickCount("2020311_www.baidu.com_8",8))list.append(CourseSearchClickCount("2020311_cn.bing.com_9",9))save(list)println(count("020311_www.baidu.com_8"))}}
测试:
在Spark Streaming中写到HBASE:
package com.taipark.spark.project.sparkimport com.taipark.spark.project.dao.{CourseClickCountDAO, CourseSearchClickCountDAO}import com.taipark.spark.project.domian.{ClickLog, CourseClickCount, CourseSearchClickCount}import com.taipark.spark.project.utils.DateUtilsimport kafka.serializer.StringDecoderimport org.apache.spark.SparkConfimport org.apache.spark.streaming.kafka.KafkaUtilsimport org.apache.spark.streaming.{Seconds, StreamingContext}import scala.collection.mutable.ListBuffer/*** 使用Spark Streaming消费Kafka的数据*/object WebStatStreamingApp {def main(args: Array[String]): Unit = {if(args.length != 2){System.err.println("Userage:WebStatStreamingApp <brokers> <topics>");System.exit(1);}val Array(brokers,topics) = argsval sparkConf = new SparkConf().setAppName("WebStatStreamingApp").setMaster("local[2]")val ssc = new StreamingContext(sparkConf,Seconds(60))val kafkaParams = Map[String,String]("metadata.broker.list"-> brokers)val topicSet = topics.split(",").toSetval messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topicSet)//messages.map(_._2).count().print()//ETL// 30.163.55.7 2020-03-10 14:32:01 "GET /class/112.html HTTP/1.1" 404 http://www.baidu.com/s?wd=Hadoopval logs = messages.map(_._2)val cleanData = logs.map(line => {val infos = line.split("\t")//infos(2) = "GET /class/112.html HTTP/1.1"val url = infos(2).split(" ")(1)var courseId = 0//拿到课程编号if(url.startsWith("/class")){val courseIdHTML = url.split("/")(2)courseId = courseIdHTML.substring(0,courseIdHTML.lastIndexOf(".")).toInt}ClickLog(infos(0),DateUtils.parseToMinute(infos(1)),courseId,infos(3).toInt,infos(4))}).filter(clicklog => clicklog.courseId != 0)// cleanData.print()//需求一cleanData.map(x => {//HBase rowkey设计:20200311_9((x.time.substring(0,8)) + "_" + x.courseId,1)}).reduceByKey(_+_).foreachRDD(rdd =>{rdd.foreachPartition(partitionRecords =>{val list = new ListBuffer[CourseClickCount]partitionRecords.foreach(pair =>{list.append(CourseClickCount(pair._1,pair._2))})CourseClickCountDAO.save(list)})})//需求二cleanData.map(x =>{//http://www.baidu.com/s?wd=Spark+Streamingval referer = x.referer.replaceAll("//","/")//http:/www.baidu.com/s?wd=Spark+Streamingval splits = referer.split("/")var host = ""//splits.length == 1 => -if(splits.length > 2){host = splits(1)}(host,x.courseId,x.time)}).filter(_._1 != "").map(x =>{(x._3.substring(0,8) + "_" + x._1 + "_" + x._2,1)}).reduceByKey(_+_).foreachRDD(rdd =>{rdd.foreachPartition(partitionRecords =>{val list = new ListBuffer[CourseSearchClickCount]partitionRecords.foreach(pair =>{list.append(CourseSearchClickCount(pair._1,pair._2))})CourseSearchClickCountDAO.save(list)})})ssc.start()ssc.awaitTermination()}}
测试:
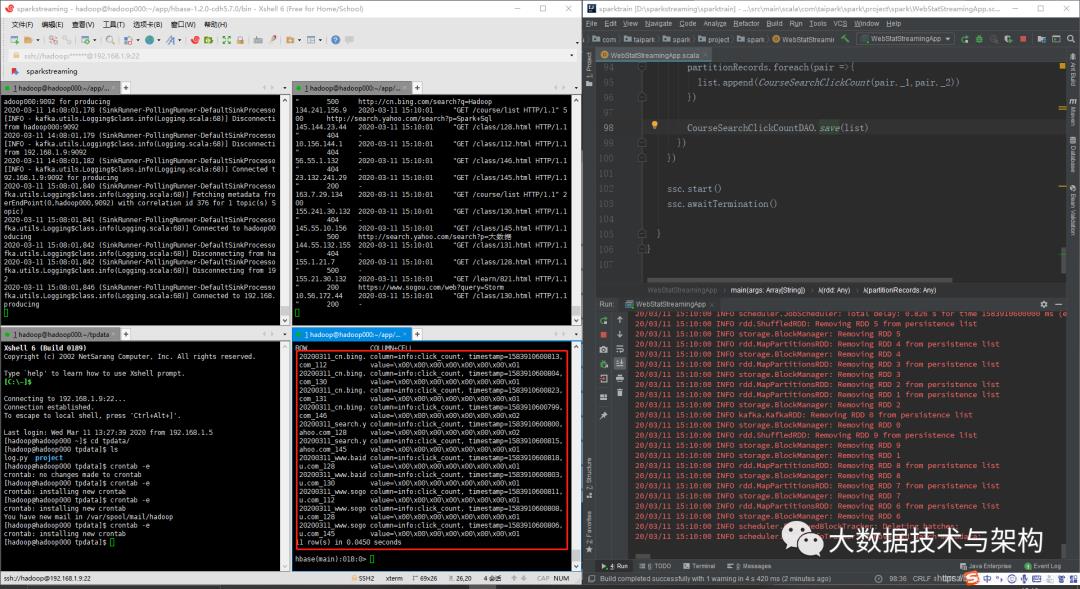
5.生产环境部署
不要硬编码,把setAppName和setMaster注释掉:
val sparkConf = new SparkConf()// .setAppName("WebStatStreamingApp")// .setMaster("local[2]")
<!--<sourceDirectory>src/main/scala</sourceDirectory><testSourceDirectory>src/test/scala</testSourceDirectory>-->
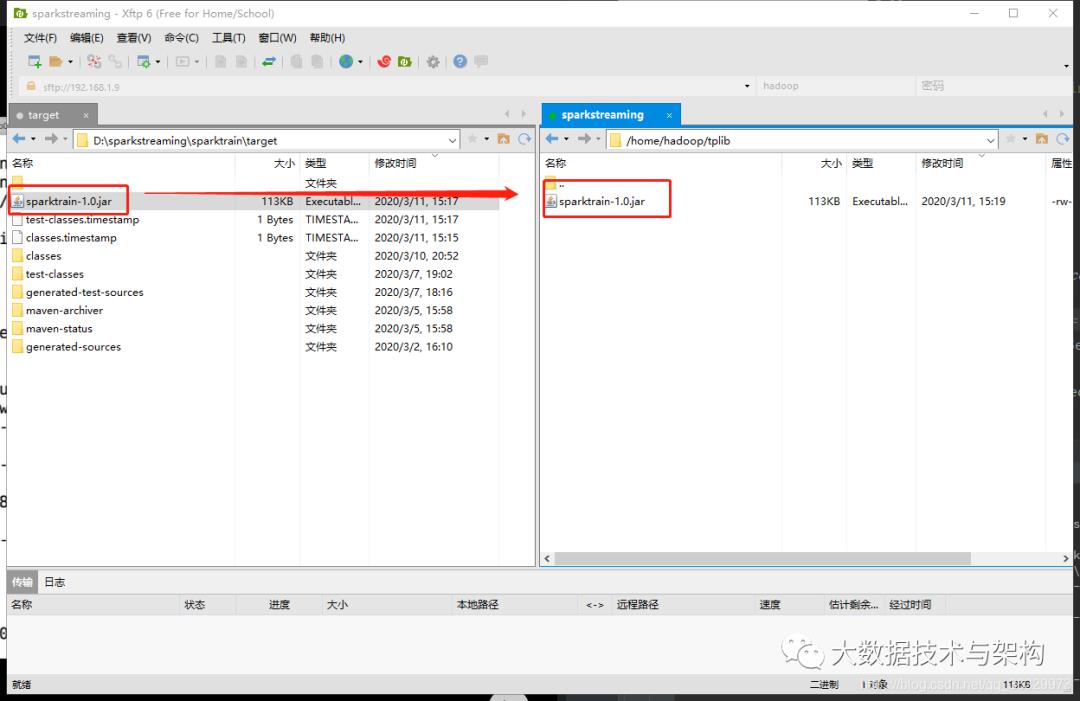
./spark-submit \--master local[5] \--name WebStatStreamingApp \--class com.taipark.spark.project.spark.WebStatStreamingApp \/home/hadoop/tplib/sparktrain-1.0.jar \hadoop000:9092 streamingtopic
报错:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils$
./spark-submit \--master local[5] \--name WebStatStreamingApp \--class com.taipark.spark.project.spark.WebStatStreamingApp \--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 \/home/hadoop/tplib/sparktrain-1.0.jar \hadoop000:9092 streamingtopic
报错:
java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/client/HBaseAdmin
修改,增加HBASE的jar包:
./spark-submit \--master local[5] \--name WebStatStreamingApp \--class com.taipark.spark.project.spark.WebStatStreamingApp \--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 \--jars $(echo /home/hadoop/app/hbase-1.2.0-cdh5.7.0/lib/*.jar | tr ' ' ',') \/home/hadoop/tplib/sparktrain-1.0.jar \hadoop000:9092 streamingtopic
运行:
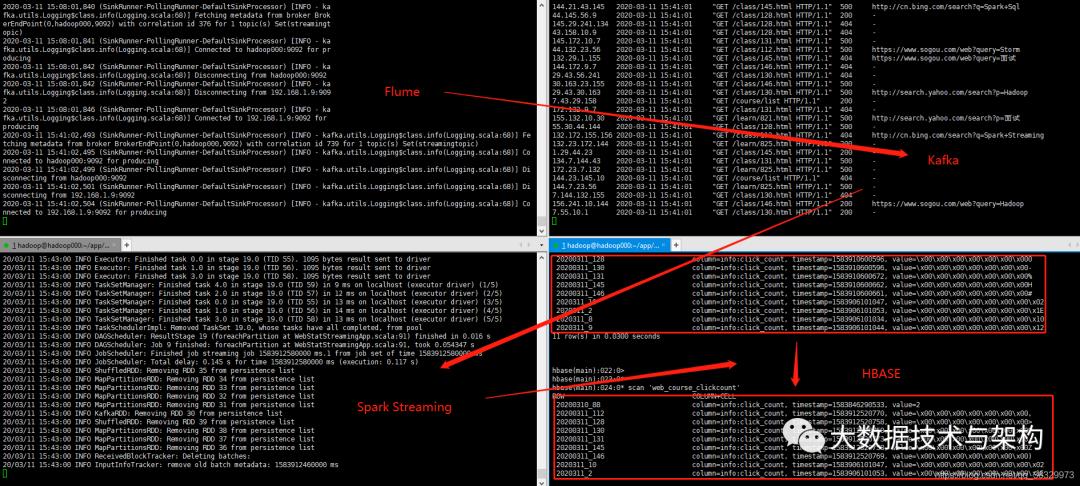
后台运行成功
6.Spring Boot开发
6.1 测试ECharts
新建一个Spring Boot项目,下载ECharts,利用其在线编译,获得echarts.min.js,放在resources/static/js下
pox.xml添加一个依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency>
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>test</title><!-- 引入 ECharts 文件 --><script ></script></head><body><!-- 为 ECharts 准备一个具备大小(宽高)的 DOM --><div id="main" style="width: 600px;height:400px;"></div><script type="text/javascript">// 基于准备好的dom,初始化echarts实例var myChart = echarts.init(document.getElementById('main'));// 指定图表的配置项和数据var option = {title: {text: 'ECharts 入门示例'},tooltip: {},legend: {data:['销量']},xAxis: {data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]},yAxis: {},series: [{name: '销量',type: 'bar',data: [5, 20, 36, 10, 10, 20]}]};// 使用刚指定的配置项和数据显示图表。myChart.setOption(option);</script></body></html>
package com.taipark.spark.web;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RestController;import org.springframework.web.servlet.ModelAndView;/*** 测试*/@RestControllerpublic class HelloBoot {@RequestMapping(value = "/hello",method = RequestMethod.GET)public String sayHello(){return "HelloWorld!";}@RequestMapping(value = "/first",method = RequestMethod.GET)public ModelAndView firstDemo(){return new ModelAndView("test");}}
测试一下:
成功
6.2 动态实现ECharts
添加repository:
<repositories><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository></repositories>
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.2.0-cdh5.7.0</version></dependency>
package com.taipark.spark.web.utils;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.client.*;import org.apache.hadoop.hbase.filter.Filter;import org.apache.hadoop.hbase.filter.PrefixFilter;import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;import java.util.HashMap;import java.util.Map;public class HBaseUtils {HBaseAdmin admin = null;Configuration configuration = null;//私有构造方法(单例模式)private HBaseUtils(){configuration = new Configuration();configuration.set("hbase.zookeeper.quorum","hadoop000:2181");configuration.set("hbase.rootdir","hdfs://hadoop000:8020/hbase");try {admin = new HBaseAdmin(configuration);} catch (IOException e) {e.printStackTrace();}}private static HBaseUtils instance = null;public static synchronized HBaseUtils getInstance(){if(instance == null){instance = new HBaseUtils();}return instance;}//根据表名获取HTable实例public HTable getTable(String tableName){HTable table = null;try {table = new HTable(configuration,tableName);} catch (IOException e) {e.printStackTrace();}return table;}/*** 根据表名和输入条件获取HBASE的记录数* @param tableName* @param dayCourse* @return*/public Map<String,Long> query(String tableName,String condition) throws Exception{Map<String,Long> map = new HashMap<>();HTable table = getTable(tableName);String cf ="info";String qualifier = "click_count";Scan scan = new Scan();Filter filter = new PrefixFilter(Bytes.toBytes(condition));scan.setFilter(filter);ResultScanner rs = table.getScanner(scan);for(Result result:rs){String row = Bytes.toString(result.getRow());long clickCount = Bytes.toLong(result.getValue(cf.getBytes(), qualifier.getBytes()));map.put(row,clickCount);}return map;}public static void main(String[] args) throws Exception{Map<String, Long> map = HBaseUtils.getInstance().query("web_course_clickcount", "20200311");for(Map.Entry<String,Long> entry:map.entrySet()){System.out.println(entry.getKey() + ":" + entry.getValue());}}}
测试通过:
定义网页访问数量Bean:
package com.taipark.spark.web.domain;import org.springframework.stereotype.Component;/*** 网页访问数量实体类*/@Componentpublic class CourseClickCount {private String name;private long value;public String getName() {return name;}public void setName(String name) {this.name = name;}public long getValue() {return value;}public void setValue(long value) {this.value = value;}}
package com.taipark.spark.web.dao;import com.taipark.spark.web.domain.CourseClickCount;import com.taipark.spark.web.utils.HBaseUtils;import org.springframework.stereotype.Component;import java.util.ArrayList;import java.util.List;import java.util.Map;/*** 网页访问数量数据访问层*/@Componentpublic class CourseClickDAO {/*** 根据天查询* @param day* @return* @throws Exception*/public List<CourseClickCount> query(String day) throws Exception{List<CourseClickCount> list = new ArrayList<>();//去HBase表中根据day获取对应网页的访问量Map<String, Long> map = HBaseUtils.getInstance().query("web_course_clickcount", "20200311");for(Map.Entry<String,Long> entry:map.entrySet()){CourseClickCount model = new CourseClickCount();model.setName(entry.getKey());model.setValue(entry.getValue());list.add(model);}return list;}public static void main(String[] args) throws Exception{CourseClickDAO dao = new CourseClickDAO();List<CourseClickCount> list = dao.query( "20200311");for(CourseClickCount model:list){System.out.println(model.getName() + ":" + model.getValue());}}}
<dependency><groupId>net.sf.json-lib</groupId><artifactId>json-lib</artifactId><version>2.4</version><classifier>jdk15</classifier></dependency>
package com.taipark.spark.web.spark;import com.taipark.spark.web.dao.CourseClickDAO;import com.taipark.spark.web.domain.CourseClickCount;import net.sf.json.JSONArray;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.ResponseBody;import org.springframework.web.bind.annotation.RestController;import org.springframework.web.servlet.ModelAndView;import java.util.HashMap;import java.util.List;import java.util.Map;/*** web层*/@RestControllerpublic class WebStatApp {private static Map<String,String> courses = new HashMap<>();static {courses.put("112","某些外国人对中国有多不了解?");courses.put("128","你认为有哪些失败的建筑?");courses.put("145","为什么人类想象不出四维空间?");courses.put("146","有什么一眼看上去很舒服的头像?");courses.put("131","男朋友心情不好时女朋友该怎么办?");courses.put("130","小白如何从零开始运营一个微信公众号?");courses.put("821","为什么有人不喜欢极简主义?");courses.put("825","有哪些书看完后会让人很后悔没有早看到?");}// @Autowired// CourseClickDAO courseClickDAO;// @RequestMapping(value = "/course_clickcount_dynamic",method = RequestMethod.GET)// public ModelAndView courseClickCount() throws Exception{// ModelAndView view = new ModelAndView("index");// List<CourseClickCount> list = courseClickDAO.query("20200311");//// for(CourseClickCount model:list){// model.setName(courses.get(model.getName().substring(9)));// }// JSONArray json = JSONArray.fromObject(list);//// view.addObject("data_json",json);//// return view;// }@AutowiredCourseClickDAO courseClickDAO;@RequestMapping(value = "/course_clickcount_dynamic",method = RequestMethod.POST)@ResponseBodypublic List<CourseClickCount> courseClickCount() throws Exception{ModelAndView view = new ModelAndView("index");List<CourseClickCount> list = courseClickDAO.query("20200311");for(CourseClickCount model:list){model.setName(courses.get(model.getName().substring(9)));}return list;}@RequestMapping(value = "/echarts",method = RequestMethod.GET)public ModelAndView echarts(){return new ModelAndView("echarts");}}
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>web_stat</title><!-- 引入 ECharts 文件 --><script ></script><script ></script></head><body><!-- 为 ECharts 准备一个具备大小(宽高)的 DOM --><div id="main" style="width: 960px;height:540px;position: absolute;top:50%;left:50%;margin-top: -200px;margin-left: -300px;"></div><script type="text/javascript">// 基于准备好的dom,初始化echarts实例var myChart = echarts.init(document.getElementById('main'));option = {title: {text: '某站点实时流处理访问量统计',subtext: '网页访问次数',left: 'center'},tooltip: {trigger: 'item',formatter: '{a} <br/>{b} : {c} ({d}%)'},legend: {orient: 'vertical',left: 'left'},series: [{name: '访问次数',type: 'pie',radius: '55%',center: ['50%', '60%'],data: (function () {var datas = [];$.ajax({type: "POST",url: "/taipark/course_clickcount_dynamic",dataType: "json",async: false,success: function (result) {for(var i=0;i<result.length;i++){datas.push({"value":result[i].value,"name":result[i].name})}}})return datas;})(),emphasis: {itemStyle: {shadowBlur: 10,shadowOffsetX: 0,shadowColor: 'rgba(0, 0, 0, 0.5)'}}}]};// 使用刚指定的配置项和数据显示图表。myChart.setOption(option);</script></body></html>
测试一下:
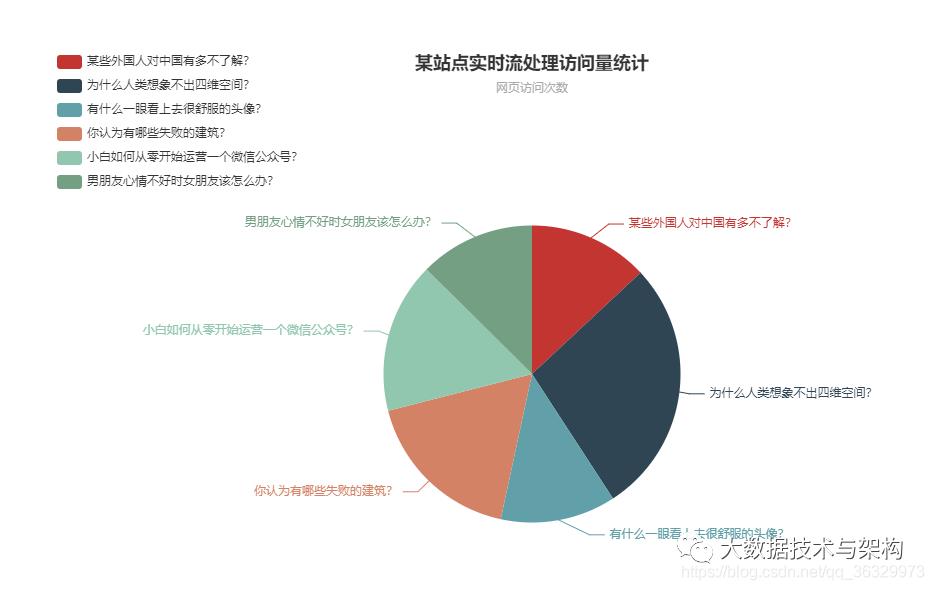
6.3 Spring的服务器部署
Maven打包并上传服务器
java -jar web-0.0.1.jar--end--
扫描下方二维码
添加好友,备注【 交流 】 可私聊交流,也可进资源丰富学习群
以上是关于大数据实战Flume+Kafka+Spark+Spring Boot 统计网页访问量项目的主要内容,如果未能解决你的问题,请参考以下文章