也谈分库分表在实际应用的实践
Posted 技术琐话
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了也谈分库分表在实际应用的实践相关的知识,希望对你有一定的参考价值。
作者介绍:张克欣,目前供职于招商银行信用卡中心,负责app营销平台的研发,曾经在易迅、腾讯、京东工作过,多年电商平台相关经验。
长久以来,自己一直是一个在技术和管理之间寻找平衡并不断摸爬滚打的人,自认为在易迅、腾讯、京东、招行的经历中,还是汲取了一些营养,大部分时间都是在获取和实践。 自我也深知贡献的重要性,但由于各种各样的原因和借口(简称懒癌),付诸指尖的并不多,就连之前答应右总文章也一直未能成行。 且自以为还算是个有追求之人,答应的事情势必要做到,否则终日惴惴不安,不能入睡。
约定共同语言: 个人不大喜欢去套用一些让人听不懂的专业名词,即使是在专业领域,相同的名词,不同人的理解也不尽相同,如果遇到一个和你理解一致的人,得之吾幸;如果遇到一个理解不一致的人,大家讨论半天,不在一个频道,完全没意义。 比如在分库分表的做法中,最常见的两个套路叫垂直拆分和水平拆分,百度了一把,真的是各种理解都有。 鉴于此,我尽量不用这些名词,如果非得用,我会尽量在这里先把注释写清楚。
[分布式事务]:基于支持两阶段提交协议的数据库,提供的跨应用及数据库的解决数据一致性解决方案。
[幂等]:为了保证保证数据一致性,在跨服务或者服务内部进行数据交换时,通过交换唯一ID来保证数据一致的机制。
1. 背景
1.1. 业务背景
笔者当时接手的业务是一个存量的业务,每日业务数据在百万的规模,查询和写的操作都比较频繁,读写比大概在。。。存量数据在几亿规模,在互联网行业,这个规模不算很大,但是业务也面临着快速增长,预期业务规模将有几个数量级的增长。
1.2. 系统背景
原有系统是属于一个单体大应用,业务数据也基本处于单表存取的情况,数据一致性靠强事务来保证,仅靠一个单库、单体应用来承担这个规模,用事务保证数据强一致性,性能方面已经捉襟见肘,彼时,数据中间件还不够完善,对业务支撑也有限,好在消息系统还算比较完善。
拆分前:
2. 策略
2.1. 原则
策略选择上,我们基于以下原则:
a. 尽量保留现有数据结构,减少迁移成本。
b. 在现有数据结构下,可以通过数据冗余,拿空间换时间。
c. 进行数据隔离。
d. 所有变更对外部系统透明,攘外必先安内,自己的问题解决后,再推动外部升级和迁移,并且提供兼容的迁移方案。
2.2. 分库策略
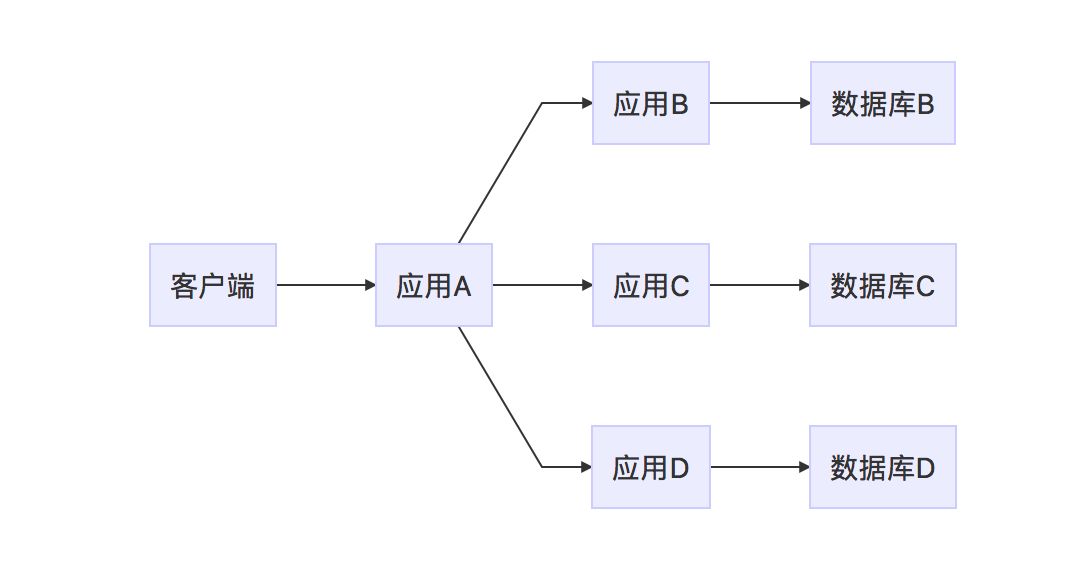
对于分库,我们基于业务按照业务领域进行了拆分,这个拆分不仅包括应用,也包括对应的数据库。具体业务不方便再次赘述,大致说说拆分的思路,基本是按照领域模型以及职责进行拆分,把相对独立,并且可以独立提供能力出来的部分拆出来,从数据库依赖转为服务依赖,粒度粗细看自己业务来定。这其中代价也是非常大的,也并非所有的业务都可以简单粗暴的这额直接来拆分。
领域的本质还是数据的拆分,是随着业务的复杂程度逐步沉淀下来的,比如电商系统的订单,在系统设计初期通常都只是一笔单子,包括支付、退换货状态甚至都在一起,随着业务的扩展,会把订单和售后单拆开,订单本身也会拆成订单和交易,订单本身也会拆成用户订单、后台订单、物流单、配送单、配送包裹等等,当然,这里写的都非常粗,写的是单,其实背后都是系统。总结下来有以下几个场景:
可以直接从数据库依赖转为服务依赖:功能相对独立的部分,可以直接拆分,从数据库的操作,转为服务依赖,原来只需要考虑数据库的异常,现在要考虑的是对于网络异常的处理,同时对于写场景要考虑幂等的处理。
部分数据交叉的场景: 体现在代码层面存在多个业务表之间存在关联操作的场景,这里用了操作,包括了读写,这种情况下,对于数据一致性的要求就比较高,同时也对业务处理流程有了较高的要求。
复杂的业务场景: 对于在业务逻辑上下文有太多数据依赖的场景,改造原有的逻辑代价非常大,风险也非常高,这种情况我们选择了重写,按照新的结构来重写这部分逻辑,并根据业务场景,选择一定的策略来进入不同的新旧流程,一方面解耦,另一方面能够比较方便做灰度验证。
跨库的数据一致性:
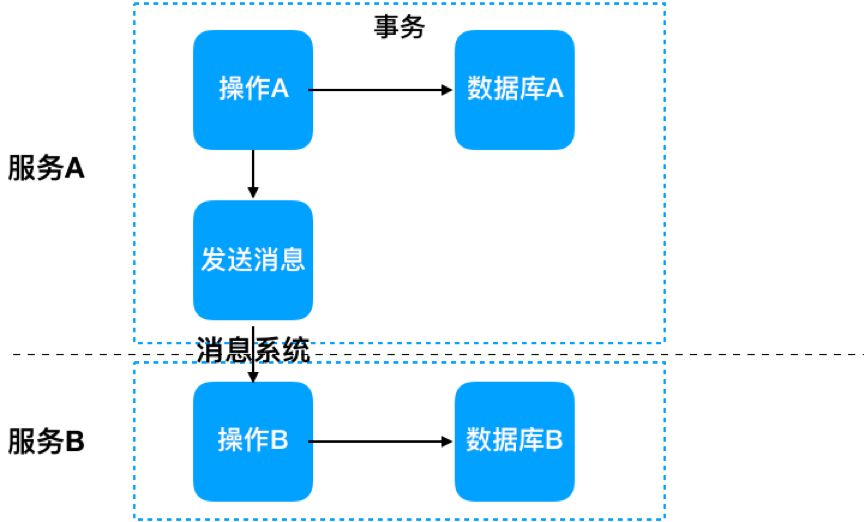
分布式事务:通常做法有分布式事务采用两阶段提交来保证,分布式事务如果有封装好的框架,对于开发使用来说,可能会简单很多,但是对于异常情况排查起来就会复杂很多,并且在我们的场景里,我们不仅是数据隔离,服务也做了拆分,分布式事务不太适合。
消息队列+幂等:基于服务的场景,我们觉得分布式事务不太适合我们,我们选择了比较土的方案,就是消息队列和幂等。我们把每一步的用户操作都做了详细分解,拆分出来每个上下文中最核心的操作,核心的操作同步处理,其余的都走消息,同时通过幂等来保证数据的一致性,其余写操作都基于事件广播,同时业务上下文中要处理好异步带来的副作用,无序性及延迟。
3. 分表策略
分表的策略就相对简单了,复杂的是迁移方案,在同一个业务领域,对于数据进行分表,无非就是分表规则,场景等。
3.1. 分表规则
分表规则很简单,我们根据自己的业务场景,按照人的纬度hash取模的方式来进行分表,这里大家经常会遇到的问题是,将来还需要再继续分的时候怎么办,我们的策略是,目前的分表充分考虑未来的容量,尽量不给将来二次分表的机会;即使不得不做,我们可以采用通用的2分法来做,2分法可以保证在采用新的分表策略时,需要迁移的规模是2分之一;除此之外,还有一种方式,就是数据冷热分级,需要分析用户的行为把用户数据分为冷热数据,冷数据归档起来提供单独处理。有同学可能会问,为什么不优先选择冷热,然后再做分表,个人觉得各有千秋,且看本文第四部分讨论。
3.2. 场景
3.2.1. 读写
读写我们封装了统一的中间层来负责分表规则,这里我们并没有去做SQL解析,来统一处理,原因有二:
从中间层不支持复杂的SQL操作,避免因为开发水平参差不齐导致一些耗时操作上线,有人可能会觉得这个是过程管理问题,我还是觉得技术上的保障会更靠谱一些。如果某个场景真的有这个需要,拉出来讨论清楚再说。
能够给开发者在开发时做到一定程度的提醒,这里的数据是分表处理的,需要特别注意。
3.2.2. 表关联
表关联确实是个问题,我们的场景是尽量规避表关联,尽量通过数据冗余,空间换时间来做。 如果不得不做,基于场景讨论。
3.2.3. 跨分表查询
这个是杜绝的,针对分表的所有操作,都需要带着分表主键,如果确实有场景需要进行聚合操作,则根据场景进行异步数据合并,然后操作合并后的数据,而非直接操作原始分表数据。
拆分后
3. 迁移方案
终于到迁移方案了,迁移方案有很多种,有粗暴的,有温柔的,还有无感的(这些词不要想歪了)。
3.1. 停机
这个很简单,高效,停机,旧数据按照分库、分表规则直接导入到新表中就行,迁移过程中的细节就不说了,无非就是数据备份、数据准备、数据操作、数据验证、业务恢复。
优点:简单直接
缺点:需要停机,业务影响大,恢复时间依赖数据迁移进度。
3.2. 无感迁移
无感大家都很喜欢,也是我们喜欢和选择的,为了能够在基础能力扩充和业务无感上寻找一个平衡,我们花了不少代价,总结下来就是双写、并行、验证、回写、追数据、切换,这几个环节并非严格按照次序,需要根据业务场景及对数据的操作来进行细分:
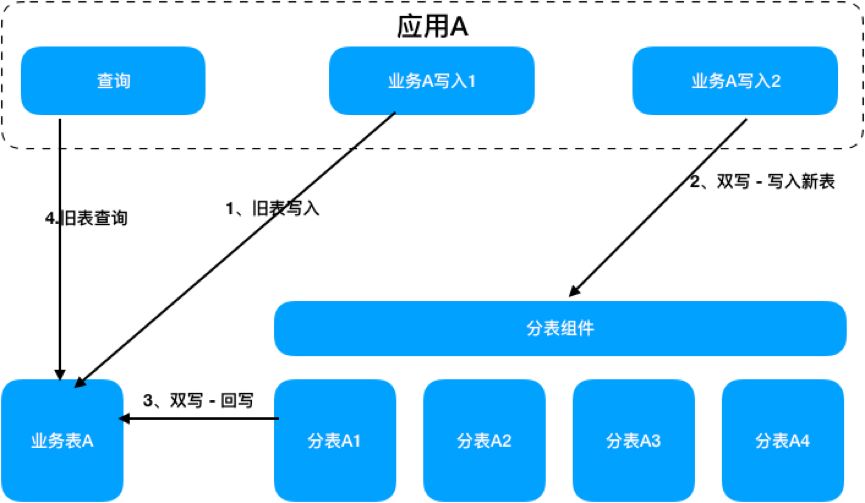
3.2.1. 双写
针对分库的数据,新旧库各写一份,数据操作依然用旧库。 对于分表,采用的是业务隔离,按照一定的条件旧写旧,新写新,新的数据回写到旧表,数据读取依然用旧表。
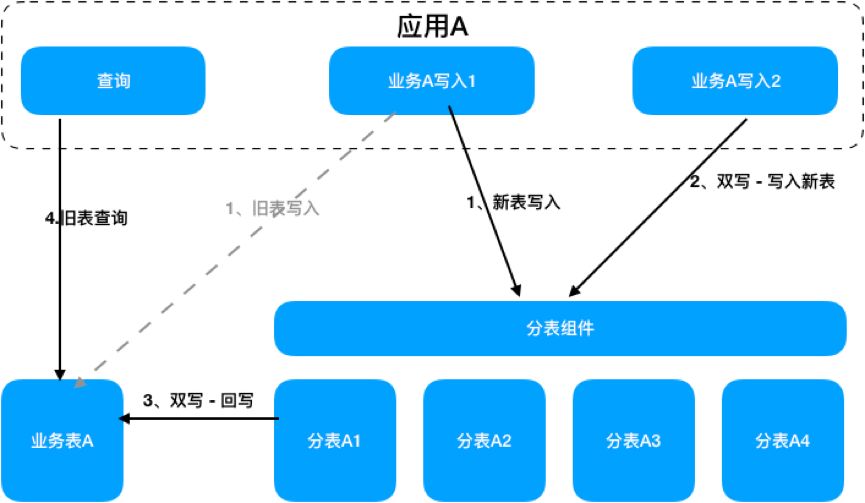
3.2.2. 并行
并行一段时间,保证有足够的时间片内的数据,这个时间根据不同业务的数据热度以及迁移代价来定,太短稳定性有风险,太长有数据压力。
3.2.3. 验证
针对并行期间的数据做新旧逻辑验证及数据验证。
3.2.4. 回写
针对分表数据,走消息系统回写到旧表中,保证用户能够及时看到数据。
3.2.5. 追数据
验证并并行一段时间以后,就可以针对旧数据进行迁移了,这个环节由于数据规模比较大,都是在数据库级别的批量操作。
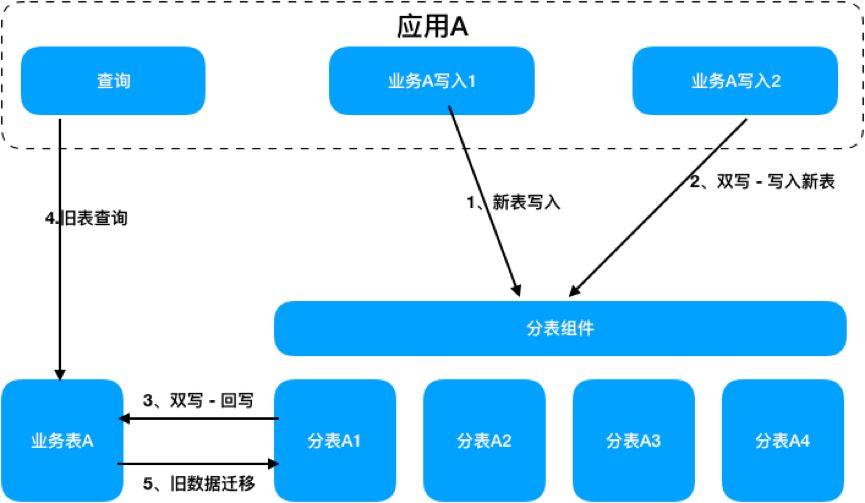
3.2.6. 切换
分库业务的切换,要注意数据的时效性,切换到新的服务,分散旧库的压力。 分表的切换会分的更细一些,按照读、写的纬度来切,优先切写到新表,通过数据回写保证能读到,然后切读到新表,最后再停回写。
4. 延伸
4.1. 选择问题
4.1.1. 消息与反查
这两个放在一起是不是有些奇怪,笔者是基于保证数据一致性的手段来考虑这件事情。 通常来说,反查更多用在同步调用上,而消息是异步场景下来用。 两者共同点在于,都需要用幂等机制来保证数据一致性。不同点在于反查时效更高,通常依赖调度,并且系统隔离性较差。 消息系统隔离性较好,但是存在消息无序性和较大延迟。
4.1.2. 幂等加异步与分布式事务
这两个放一起也是由于解决数据一致性的问题,两者各有千秋,我们选择了开发复杂一些,但是相对灵活一些的方案,针对大数据量、高并发的场景,分布式事务对于我们来说太重了。如果只是单纯的把数据库进行拆分,分布式事务可能更为适合。
4.1.3. 读写分离与分库分表
读写分离也是分摊系统压力和数据库压力的有效方式,两者不存在谁更好的问题,需要根据面对的业务场景及数据场景,分析数据的读写比作出选择,如果读写比非常高,那么无疑读写分离的效果是非常明显的。
4.1.4. 数据归档与分库分表
数据归档也是一种常用的策略,根据用户行为的分析业务场景和数据,来降低系统压力,选择依据是数据本身的冷热程度,如果数据冷热分布存在比较大的不均衡,那么归档无疑是比较优先的选择。
4.2. 代价问题
4.2.1. 数据时效
并行时间需要根据数据时效要求来做评估,时效要求比较长,那么并行期会比较长,这时建议考虑其它策略。
4.2.2. 流程影响
从直接操作数据库到依赖服务,从同步改为异步,这些对业务流程和数据流程都有非常大的影响,需要评估并做好处理。
4.2.3. 开发复杂度
方案选择直接影响就是开发复杂度,如果要做无感迁移,复杂度要多非常多,怎么平衡和选择才是关键。
4.3. 迁移升级
如果应用和外部系统有交互,那么还需要考虑灰度及兼容,以及推动外部迁移的部分,这些就是后话,不在此文之列。
技术琐话
以上是关于也谈分库分表在实际应用的实践的主要内容,如果未能解决你的问题,请参考以下文章