聊五毛钱的分库分表
Posted 张二蛋又要扯蛋了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊五毛钱的分库分表相关的知识,希望对你有一定的参考价值。
分表是实际开发中比较常见的一种操作。通过分表可以降低单表容量,分散单表访问压力。
1、常见的分表策略
主要分为垂直拆分和水平拆分。
垂直拆分:换句话讲是大表拆小表,将大表中的一些不常用(含不经常改变)的字段或者内容很大的字段单独拆出到一张新表中。一般情况下,字段很多的时候适合使用垂直拆分,拆分之后比较容易维护。有点类似系统服务化中的垂直拆分。
水平拆分:根据某种策略对数据进行分片存储,将数据分片到数据库中不同的表中。
有库内分表和分库分表之说。
库内分表: 使用同一个数据库,仅将数据分散到多个表中。能解决单表数据量过大的问题,但不能分散数据库的压力,因为依旧使用同一个数据库实例,IO/CPU/网络等依旧存在竞争关系。 所以对缓解数据库压力而言,起效不大。
分库分表:将数据分片到不同的数据库实例上 ,能分散数据库压力,也能解决单表数据过大的问题。 同时,对于数据的扩展也有了更好的支持。 磁盘/CPU/网络等不够的时候,扩展数据库实例即可。
2、如何保证扩展性
水平分表是我们经常使用的一种分表方式,但业务发展往往可能会超出我们的预期,比如,原本预计10张表足够存储,但是业务发展迅猛导致10张表不太够了,怎么能尽量减少二次扩展表带来的成本呢?
一般情况下,我们在用取余或者hash的方式确认表的时候,使用范围来处理。 比如一张表我们用uid作为分表key值,假设计划分表10张,可以使用uid % 1000, 其中 0~99的值在第一张表,100~199在第二张表,以此类推。
这样,如果之后发现10张表不够的时候,可以在每张表的基础上在做一次分表, 这样,可以尽量减少因改变分表策略导致的数据迁移操作。
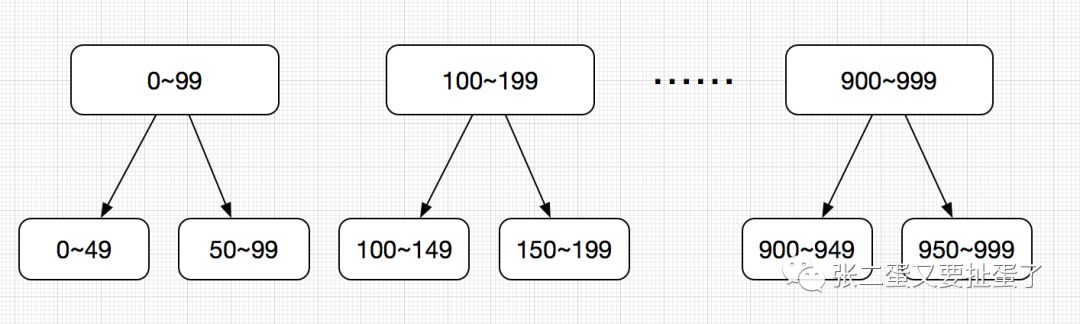
如上图,
需要数据迁移的是,每张原始表中的后半部分,前半部分是不需要迁移的。 减少了一半的数据迁移量。
3、分库分表之后,查询怎么做?
比较常见的一个场景,未分表前,我们可以根据表中的多个字段查询,但是分表之后可能查询字段并不是分表主键,所以就无法确认到是哪张表。举个例子:
假设我们有一张用户表t_user
表中的字段有 uid, username, mobile, age 这几个关键字段。 假设我们使用uid来作为分表条件。
uid作为查询条件,可以直接定位到表,所以相对较简单。
但并不是所有的查询都有uid,比如我想根据mobile查询用户的时候,就无法定位到是哪张表了。
当条件中没有分表字段的时候,该怎么查询?
a、查询的时候起N个线程(和分表数一致),每个线程分别查一张表,然后多个线程把数据结果做合并返回。
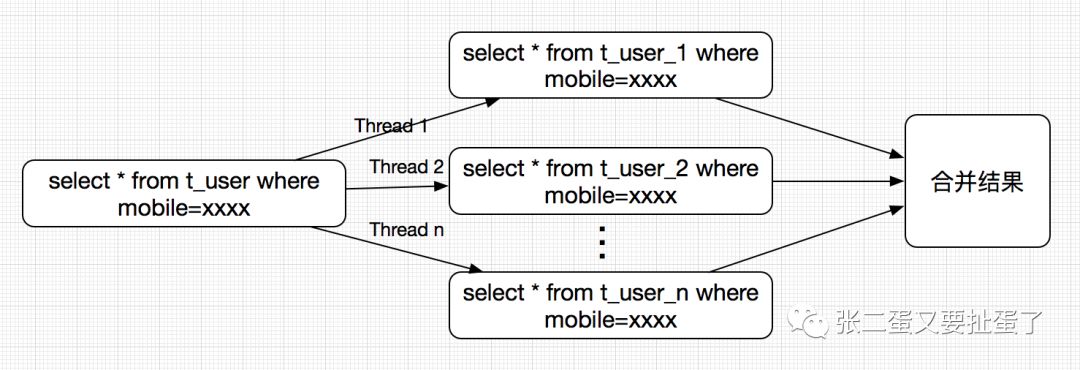
但这样很可能会存在无用查询的情况,比如有10张表,但mobile可能就只在一张表中,所以其余9个的查询都是无用查询。
b、建表的时候,建立冗余表,存储 mobile和uid的对应关系。 其余不存储。
这样使用空间换时间, 可以通过两次查询就可以查询到具体数据。但缺点是需要单独存储mobile和uid的关系,且查询字段较多的时候,就需要有多张冗余表
c、使用ES,Solr等索引工具对可能遇到的查询字段建立索引,查询到具体uid之后再到DB中查询。
这样同样是使用空间换时间,但可以使得查询相对容易些。缺点是需要单独维护一套索引。 在查询字段量较多及查询较多的时候,一般都会采用这种方案。
首页图拍摄自 北京百花山
以上是关于聊五毛钱的分库分表的主要内容,如果未能解决你的问题,请参考以下文章
分库分表 ---SpringBoot + ShardingSphere 实现分表