简单粗暴的分库分表设计方案
Posted 架构之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单粗暴的分库分表设计方案相关的知识,希望对你有一定的参考价值。
架构干货,关键时刻马上送达!
来源于:https://zhuanlan.zhihu.com/p/37438652
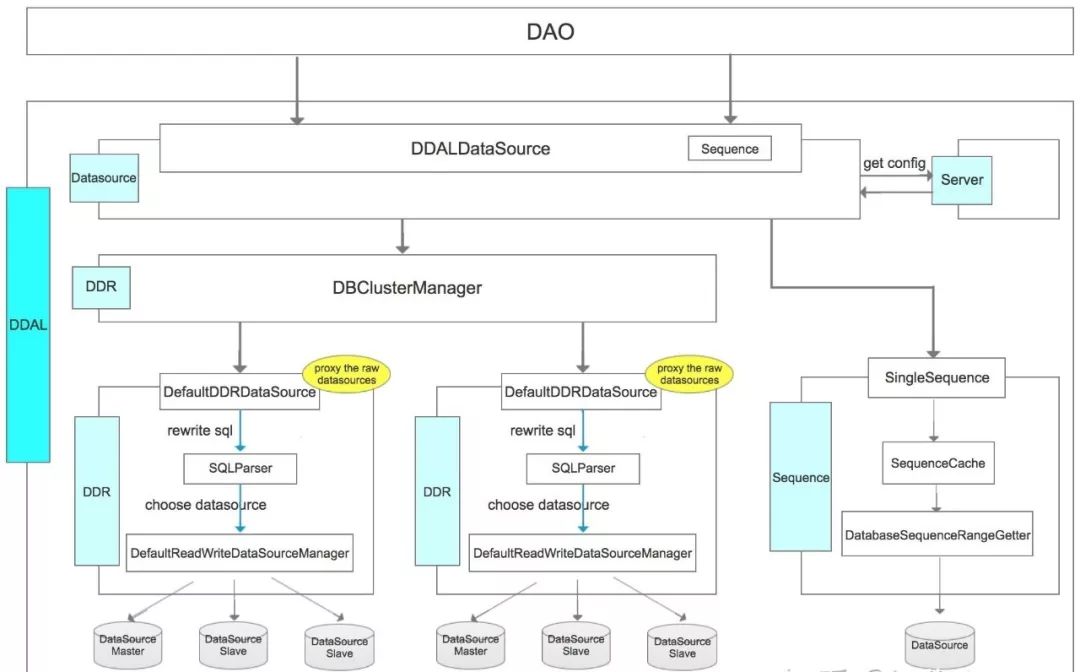
1.数据散列模式
数据散列模式主要是通过hash算法将数据随机写入(分库)分表中,用以提高数据库的负载能力,这种设计方案下分表字段通常需要被包含在分表中。
优点:可以解决有局部热点的数据的负载均衡,并整体提高数据库的负载能力。
缺点:
(1)需要在前期规划好分库和分表的数量,不能动态扩展;
(2)分页查询需要基于shard-key,限制业务的查询场景;
DDAL的实现:
<bean id="idRule" class="org.hellojavaer.ddal.ddr.shard.rule.SpelShardRouteRule">
<property name="scRouteRule" value="{scName}_{format('%02d', sdValue % 2)}"/>
<property name="tbRouteRule" value="{tbName}_{format('%04d', sdValue % 8)}"/>
</bean>
2.数据区段模式
数据区段模式是按照数据值的区间进行分库分表,比如1 - 100到写入0号表,101-200写入200号表,依次类推。
这种模式主要用于shard-key没有局部热点的数据,其中的一个业务场景为:日志表的按时间维度的切分。
优点:支持动态水平扩展
缺点:存在局部数据热点问题
DDAL实现:你可以使用DivideShardRouteRule来实现该功能,也可以使用SpelShardRouteRule(eg: 按进行日切的路由规则表达式'{tbName}_{dateFormat('yyyyMMdd', sdValue)')来实现该功能,两者之间的差别在于DivideShardRouteRule在处理sql的between-and操作时更加高效
3.数据隔离模式
数据隔离模式在实现上体现为只分库不分表同时分表字段shard-key不包含在分表中。在业务上体现为业务数据按schema进行隔离,分库元信息独立存储。
优点:
(1)数据隔离
(2)每次分库路由后,都只会落在一个数据库节点上,分库操作‘转换’为单库操作,因此所有单库操作可以被支持(包括复杂的分页查询)
缺点:定制化场景,单schema内可能出现容量和性能问题
DDAL实现:由于shard-key没有被包含在分表中,因此需要使用ShardRoute注解来引导分表路由,或者使用ShardRouteContext来引导分表路由,这两种的设置是等效的。
近期干货
资料:
干货:
干货:
干货:
干货:
以上是关于简单粗暴的分库分表设计方案的主要内容,如果未能解决你的问题,请参考以下文章