分库分表数据_ShardingDatasource
Posted 靖少技术杂谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分库分表数据_ShardingDatasource相关的知识,希望对你有一定的参考价值。
为何需要分库分表?
关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当单表的数据量达到一定量级别以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。此时就要考虑对其进行分库分表,分库分表的目的就在于减少数据库的负担,缩短查询时间,提高性能;进行分库分表最核心手段是基于数据进行切分的规则(切分规则:垂直切分,水平切分)
垂直切分
垂直切分常见有垂直分库和垂直分表两种。
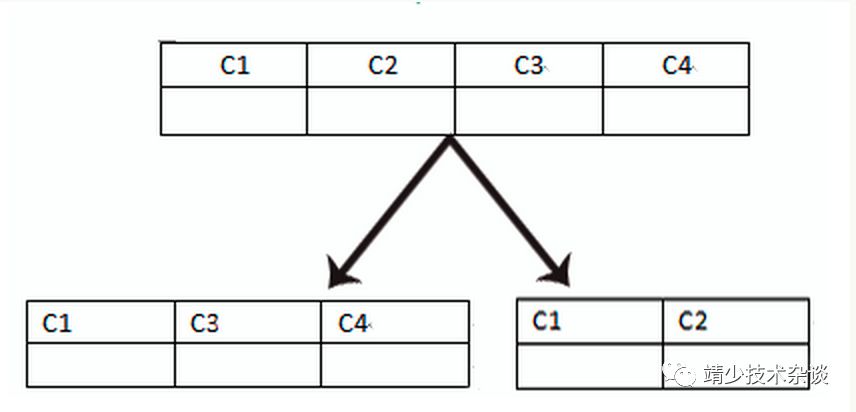
垂直分库就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。做法与大系统拆分为多个小系统类似,按业务分类进行独立划分。与"微服务治理"的做法相似,每个微服务使用单独的一个数据库。如图:
垂直分表是基于数据库中的"列"进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。在字段很多的情况下(例如一个大表有100多个字段),通过"大表拆小表",更便于开发与维护,也能避免跨页问题,mysql底层是通过数据页存储的,一条记录占用空间过大会导致跨页,造成额外的性能开销。另外数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
水平(横向)切分
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。
水平切分分为库内分表和分库分表,是根据表内数据内在的逻辑关系,将同一个表按不同的条件分散到多个数据库或多个表中,每个表中只包含一部分数据,从而使得单个表的数据量变小,达到分布式的效果。如图所示:
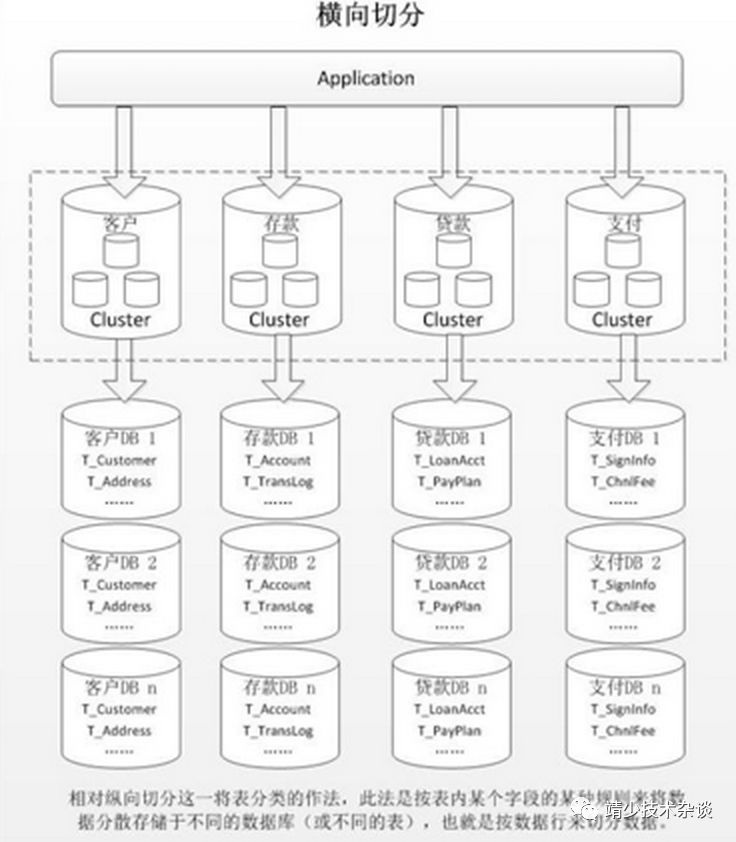
库内分表只解决了单一表数据量过大的问题,但没有将表分布到不同机器的库上,因此对于减轻MySQL数据库的压力来说,帮助不是很大,大家还是竞争同一个物理机的CPU、内存、网络IO,最好通过分库分表来解决。
ShardingDatasource 是什么?
ShardingDatasource是一个增强版本的datsource,扩展jdbc协议,不侵入任何业务代码,配置灵活(使用了spring spi 机制),无须其它依赖以及额外部署,性能损耗0.001%(损耗在sql 解析)。主要功能如下:
支持分库,分表,分库分表
支持读写分离,一主多从模式
兼容各种ORM框架,无需改动任何代码;兼容各种关系型数据库
分库分表的分片策略灵活,可支持=,BETWEEN,IN等多维度分片,也可支持多分片键共用。
SQL解析功能完善,支持聚合,分组,排序,Limit,OR等查询,SQL解析使用Druid解析器,是目前性能最高的SQL解析器。
支持spring 自定义标签,标签简单且灵活
支持数据库慢查询监控报警,日志可查询
分库分表策略可扩展性强,可定制化,标签化配置
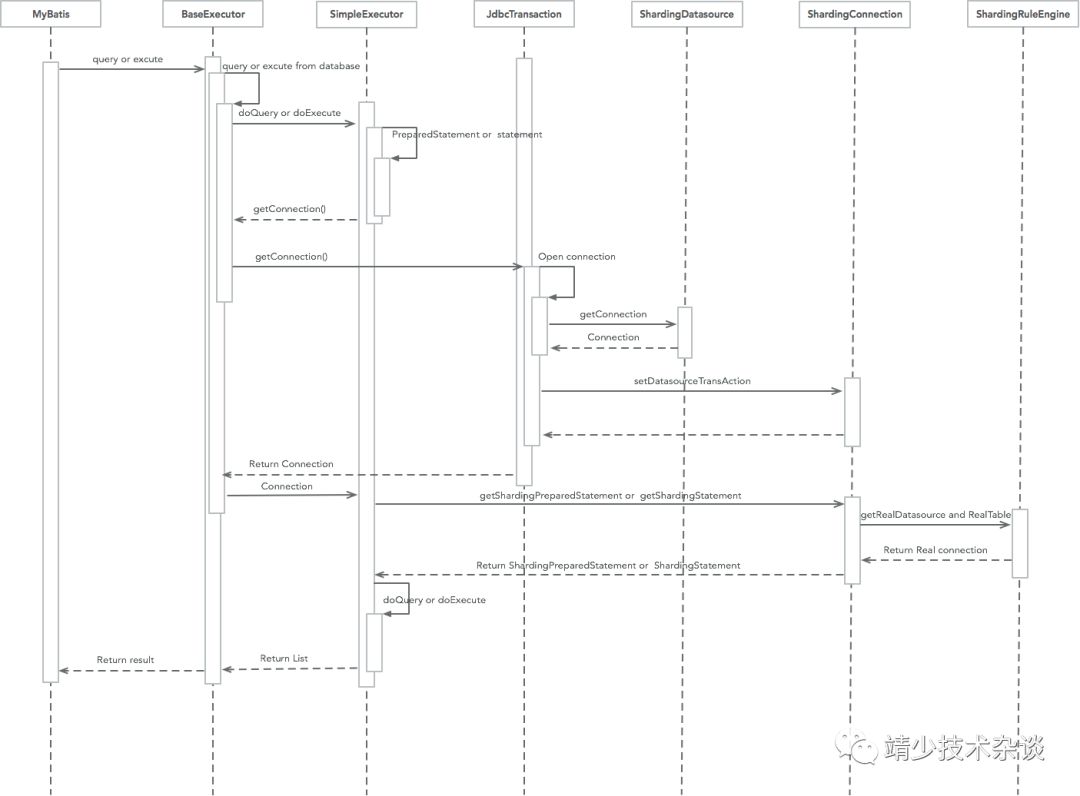
ShardingDatasource 时序图(Mybatis 的例子)
典型分库分表策略
数据范围切分
按照时间区间或ID区间来切分。例如:按日期将不同月甚至是日的数据分散到不同的库中;将userId为1~9999的记录分到第一个库,10000~20000的分到第二个库,以此类推。某种意义上,某些系统中使用的"冷热数据分离",将一些使用较少的历史数据迁移到其他库中,业务功能上只提供热点数据的查询,也是类似的实践。
这样的优点在于:
单表大小可控
天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
缺点:
热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
取模切分
一般采用hash取模mod的切分方式,例如:将 Customer 表根据 cusno 字段切分到4个库中,余数为0的放到第一个库,余数为1的放到第二个库,以此类推。这样同一个用户的数据会分散到同一个库中,如果查询条件带有cusno字段,则可明确定位到相应库去查询。
优点:
数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈
缺点:
后期分片集群扩容时,需要迁移旧的数据(使用一致性hash算法能较好的避免这个问题)
容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带cusno时,将会导致无法定位数据库,从而需要同时向4个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
ShardingDatasource 核心解析器代码
package com.alibaba.druid.sharding.sql;
import java.util.List;
import com.alibaba.druid.sql.ast.SQLStatement;
import com.alibaba.druid.sql.visitor.SQLASTVisitor;
public interface ShardingVisitor extends SQLASTVisitor {
public static final String ATTR_DB = "sharding.db";
public static final String ATTR_PARTITION = "sharding.partition";
public static final String ATTR_TABLE_SOURCE = "sharding.tableSource";
public static final String ATTR_ALIAS = "sharding.alias";
public static final String ATTR_TABLES = "sharding.tables";
List<SQLStatement> getResult();
}
package com.alibaba.druid.sharding.sql;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.alibaba.druid.sharding.ShardingRuntimeException;
import com.alibaba.druid.sharding.config.MappingRule;
import com.alibaba.druid.sharding.config.RouteConfig;
import com.alibaba.druid.sharding.config.TablePartition;
import com.alibaba.druid.sql.ast.SQLExpr;
import com.alibaba.druid.sql.ast.SQLObject;
import com.alibaba.druid.sql.ast.SQLStatement;
import com.alibaba.druid.sql.ast.expr.SQLBinaryOpExpr;
import com.alibaba.druid.sql.ast.expr.SQLIdentifierExpr;
import com.alibaba.druid.sql.ast.expr.SQLLiteralExpr;
import com.alibaba.druid.sql.ast.expr.SQLPropertyExpr;
import com.alibaba.druid.sql.ast.expr.SQLVariantRefExpr;
import com.alibaba.druid.sql.ast.statement.SQLDeleteStatement;
import com.alibaba.druid.sql.ast.statement.SQLExprTableSource;
import com.alibaba.druid.sql.ast.statement.SQLJoinTableSource;
import com.alibaba.druid.sql.ast.statement.SQLSelectQueryBlock;
import com.alibaba.druid.sql.ast.statement.SQLSelectStatement;
import com.alibaba.druid.sql.ast.statement.SQLTableSource;
import com.alibaba.druid.sql.ast.statement.SQLUpdateStatement;
import com.alibaba.druid.sql.dialect.mysql.ast.statement.MySqlDeleteStatement;
import com.alibaba.druid.sql.dialect.mysql.ast.statement.MySqlInsertStatement;
import com.alibaba.druid.sql.dialect.mysql.ast.statement.MySqlSelectQueryBlock;
import com.alibaba.druid.sql.dialect.mysql.ast.statement.MySqlUpdateStatement;
import com.alibaba.druid.sql.dialect.mysql.visitor.MySqlASTVisitorAdapter;
import com.alibaba.druid.sql.visitor.SQLEvalVisitorUtils;
import com.alibaba.druid.util.JdbcConstants;
public class MySqlShardingVisitor extends MySqlASTVisitorAdapter implements ShardingVisitor {
private final RouteConfig routeConfig;
private final List<Object> parameters;
private List<SQLStatement> result = new ArrayList<SQLStatement>(2);
private SQLStatement input = null;
public MySqlShardingVisitor(RouteConfig routeConfig, List<Object> parameters){
this.routeConfig = routeConfig;
this.parameters = parameters;
}
public MySqlShardingVisitor(RouteConfig routeConfig, Object... parameters){
this(routeConfig, Arrays.asList(parameters));
}
@Override
public List<SQLStatement> getResult() {
return result;
}
public RouteConfig getRouteConfig() {
return routeConfig;
}
public List<Object> getParameters() {
return parameters;
}
@Override
public boolean visit(SQLSelectStatement x) {
input = x;
return true;
}
@Override
public boolean visit(MySqlDeleteStatement x) {
input = x;
if (x.getFrom() != null) {
x.getFrom().setParent(x);
x.getFrom().accept(this);
}
if (x.getTableSource() != null) {
x.getTableSource().setParent(x);
x.getTableSource().accept(this);
}
if (x.getWhere() != null) {
x.getWhere().setParent(x);
x.getWhere().accept(this);
}
result.add(x);
return false;
}
@Override
public boolean visit(MySqlUpdateStatement x) {
input = x;
if (x.getTableSource() != null) {
x.getTableSource().setParent(x);
x.getTableSource().accept(this);
}
if (x.getWhere() != null) {
x.getWhere().setParent(x);
x.getWhere().accept(this);
}
result.add(x);
return false;
}
@Override
public boolean visit(MySqlInsertStatement x) {
input = x;
String table = x.getTableName().getSimpleName();
MappingRule mappingRule = routeConfig.getMappingRule(table);
if (mappingRule == null) {
result.add(x);
return false;
}
if (x.getValues() == null) {
throw new ShardingRuntimeException("sharding rule violation, insert's values clause is null");
}
String column = mappingRule.getColumn();
int columnIndex = -1;
for (int i = 0; i < x.getColumns().size(); ++i) {
SQLExpr columnExpr = x.getColumns().get(i);
if (columnExpr instanceof SQLIdentifierExpr) {
String columnName = ((SQLIdentifierExpr) columnExpr).getName();
if (column.equalsIgnoreCase(columnName)) {
columnIndex = i;
break;
}
}
}
if (columnIndex == -1) {
throw new ShardingRuntimeException("sharding rule violation, columns not set : " + column);
}
SQLExpr valueExpr = x.getValues().getValues().get(columnIndex);
Object value = SQLEvalVisitorUtils.eval(null, valueExpr, parameters);
String partition = mappingRule.getPartition(value);
if (partition == null) {
throw new ShardingRuntimeException("sharding rule violation, partition not match, value : " + value);
}
TablePartition tablePartition = routeConfig.getPartition(table, partition);
x.setTableName(new SQLIdentifierExpr(tablePartition.getTable()));
if (tablePartition.getDatabase() != null) {
x.putAttribute(ATTR_DB, tablePartition.getDatabase());
}
result.add(x);
return false;
}
@Override
public boolean visit(MySqlSelectQueryBlock x) {
if (x.getFrom() != null) {
x.getFrom().setParent(x);
x.getFrom().accept(this);
}
if (x.getWhere() != null) {
x.getWhere().setParent(x);
x.getWhere().accept(this);
}
return false;
}
@Override
public boolean visit(SQLJoinTableSource x) {
x.getLeft().setParent(x);
x.getRight().setParent(x);
if (x.getCondition() != null) {
x.getCondition().setParent(x);
}
return true;
}
@Override
public boolean visit(SQLExprTableSource x) {
Map<String, SQLTableSource> aliasMap = getAliasMap(x);
if (aliasMap != null) {
if (x.getAlias() != null) {
aliasMap.put(x.getAlias(), x);
}
if (x.getExpr() instanceof SQLIdentifierExpr) {
String tableName = ((SQLIdentifierExpr) x.getExpr()).getName();
aliasMap.put(tableName, x);
}
}
return false;
}
@Override
public boolean visit(SQLBinaryOpExpr x) {
x.getLeft().setParent(x);
x.getRight().setParent(x);
x.getLeft().accept(this);
x.getRight().accept(this);
String column = null;
if ((column = getColumn(x.getLeft())) != null && isValue(x.getRight())) {
boolean isMappingColumn = false;
SQLTableSource tableSource = getBinaryOpExprLeftOrRightTableSource(x.getLeft());
MappingRule mappingRule = getMappingRule(tableSource);
if (mappingRule != null) {
if (mappingRule.getColumn().equalsIgnoreCase(column)) {
isMappingColumn = true;
}
}
if (isMappingColumn) {
Object value = SQLEvalVisitorUtils.eval(JdbcConstants.MYSQL, x.getRight(), parameters);
String partitionName = null;
switch (x.getOperator()) {
case Equality:
partitionName = mappingRule.getPartition(value);
break;
default:
throw new ShardingRuntimeException("not support operator " + x.getOperator());
}
if (partitionName == null) {
throw new ShardingRuntimeException("sharding rule violation, partition not match, value : " + value);
}
TablePartition tablePartition = routeConfig.getPartition(mappingRule.getTable(), partitionName);
if (tableSource.getAttribute(ATTR_PARTITION) == null) {
((SQLExprTableSource) tableSource).setExpr(new SQLIdentifierExpr(tablePartition.getTable()));
tableSource.putAttribute(ATTR_PARTITION, tablePartition);
if (tablePartition.getDatabase() != null && input != null) {
input.putAttribute(ATTR_DB, tablePartition.getDatabase());
}
} else if (tableSource.getAttribute(ATTR_PARTITION) != tablePartition) {
throw new ShardingRuntimeException("sharding rule violation, multi-partition matched, value : "
+ value);
}
}
}
return false;
}
MappingRule getMappingRule(SQLTableSource tableSource) {
if (tableSource instanceof SQLExprTableSource) {
SQLExpr expr = ((SQLExprTableSource) tableSource).getExpr();
if (expr instanceof SQLIdentifierExpr) {
String table = ((SQLIdentifierExpr) expr).getName();
return routeConfig.getMappingRule(table);
}
}
return null;
}
static boolean isValue(SQLExpr x) {
return x instanceof SQLLiteralExpr || x instanceof SQLVariantRefExpr;
}
static String getColumn(SQLExpr x) {
if (x instanceof SQLPropertyExpr) {
return ((SQLPropertyExpr) x).getName();
}
if (x instanceof SQLIdentifierExpr) {
return ((SQLIdentifierExpr) x).getName();
}
return null;
}
static SQLTableSource getBinaryOpExprLeftOrRightTableSource(SQLExpr x) {
SQLTableSource tableSource = (SQLTableSource) x.getAttribute(ATTR_TABLE_SOURCE);
if (tableSource != null) {
return tableSource;
}
SQLTableSource defaltTableSource = getDefaultTableSource(x.getParent());
if (defaltTableSource instanceof SQLExprTableSource) {
SQLExpr expr = ((SQLExprTableSource) defaltTableSource).getExpr();
if (expr instanceof SQLIdentifierExpr) {
x.putAttribute(ATTR_TABLE_SOURCE, defaltTableSource);
return defaltTableSource;
}
}
return null;
}
@Override
public boolean visit(SQLPropertyExpr x) {
x.getOwner().setParent(x);
x.getOwner().accept(this);
return false;
}
@Override
public boolean visit(SQLIdentifierExpr x) {
SQLTableSource tableSource = getTableSource(x.getName(), x.getParent());
if (tableSource != null) {
x.putAttribute(ATTR_TABLE_SOURCE, tableSource);
}
return false;
}
public static SQLTableSource getTableSource(String name, SQLObject parent) {
Map<String, SQLTableSource> aliasMap = getAliasMap(parent);
if (aliasMap == null) {
return null;
}
SQLTableSource tableSource = aliasMap.get(name);
if (tableSource != null) {
return tableSource;
}
for (Map.Entry<String, SQLTableSource> entry : aliasMap.entrySet()) {
if (name.equalsIgnoreCase(entry.getKey())) {
return tableSource;
}
}
return null;
}
@SuppressWarnings("unchecked")
public static Map<String, SQLTableSource> getAliasMap(SQLObject x) {
if (x == null) {
return null;
}
if (x instanceof SQLSelectQueryBlock || x instanceof SQLDeleteStatement) {
Map<String, SQLTableSource> map = (Map<String, SQLTableSource>) x.getAttribute(ATTR_ALIAS);
if (map == null) {
map = new HashMap<String, SQLTableSource>();
x.putAttribute(ATTR_ALIAS, map);
}
return map;
}
return getAliasMap(x.getParent());
}
public static SQLTableSource getDefaultTableSource(SQLObject x) {
if (x == null) {
return null;
}
if (x instanceof SQLSelectQueryBlock) {
return ((SQLSelectQueryBlock) x).getFrom();
}
if (x instanceof SQLDeleteStatement) {
return ((SQLDeleteStatement) x).getTableSource();
}
if (x instanceof SQLUpdateStatement) {
return ((SQLUpdateStatement) x).getTableSource();
}
return getDefaultTableSource(x.getParent());
}
}
以上是关于分库分表数据_ShardingDatasource的主要内容,如果未能解决你的问题,请参考以下文章