6策略--数据库分库分表策略
Posted 岁月里客栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了6策略--数据库分库分表策略相关的知识,希望对你有一定的参考价值。
我们知道每台机器无论配置多么好它都有自身的物理上限,所以当我们应用已经能触及或远远超出单台机器的某个上限的时候,我们惟有寻找别的机器的帮助或者继续升级的我们的硬件,但常见的方案还是通过添加更多的机器来共同承担压力。
我们还得考虑当我们的业务逻辑不断增长,我们的机器能不能通过线性增长就能满足需求?因此,使用数据库的分库分表,能够立竿见影的提升系统的性能,关于为什么要使用数据库的分库分表的其他原因这里不再赘述,主要讲具体的实现策略。请看下边章节。
二、分表实现策略
关键字:用户ID、表容量
对于大部分数据库的设计和业务的操作基本都与用户的ID相关,因此使用用户ID是最常用的分库的路由策略。用户的ID可以作为贯穿整个系统用的重要字段。因此,使用用户的ID我们不仅可以方便我们的查询,还可以将数据平均的分配到不同的数据库中。(当然,还可以根据类别等进行分表操作,分表的路由策略还有很多方式)
接着上述电商平台假设,订单表order存放用户的订单数据,sql脚本如下(只是为了演示,省略部分细节):
当数据比较大的时候,对数据进行分表操作,首先要确定需要将数据平均分配到多少张表中,也就是:表容量。
这里假设有100张表进行存储,则我们在进行存储数据的时候,首先对用户ID进行取模操作,根据 user_id%100 获取对应的表进行存储查询操作,示意图如下:
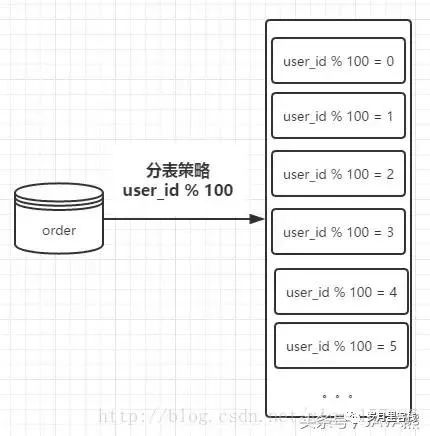
例如,user_id = 101 那么,我们在获取值的时候的操作,可以通过下边的sql语句:
select * from order_1 where user_id= 101
其中,order_1是根据 101%100 计算所得,表示分表之后的第一章order表。
注意:
在实际的开发中,如果你使用MyBatis做持久层的话,MyBatis已经提供了很好得支持数据库分表的功能,例如上述sql用MyBatis实现的话应该是:
接口定义:

xml配置映射文件:
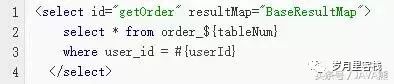
其中${tableNum} 含义是直接让参数加入到sql中,这是MyBatis支持的特性。
注意:
另外,在实际的开发中,我们的用户ID更多的可能是通过UUID生成的,这样的话,
我们可以首先将UUID进行hash获取到整数值,然后在进行取模操作。
三、分库实现策略
数据库分表能够解决单表数据量很大的时候数据查询的效率问题,但是无法给数据库的并发操作带来效率上的提高,因为分表的实质还是在一个数据库上进行的操作,很容易受数据库IO性能的限制。
因此,如何将数据库IO性能的问题平均分配出来,很显然将数据进行分库操作可以很好地解决单台数据库的性能问题。
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。
还是上例,将用户ID进行取模操作,这样的话获取到具体的某一个数据库,同样关键字有:
用户ID、库容量
路由的示意图如下:
上图中库容量为100。
同样,如果用户ID为UUID请先hash然后在进行取模。
四、分库与分表实现策略
上述的配置中,数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题。
有时候,我们需要同时考虑这两个问题,因此,我们既需要对单表进行分表操作,还需要进行分库操作,以便同时扩展系统的并发处理能力和提升单表的查询性能,就是我们使用到的分库分表。
分库分表的策略相对于前边两种复杂一些,一种常见的路由策略如下:
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
1、中间变量 = 262145%(256*1024)= 1;
2、库序号 = 取整(1/1024)= 0;
3、表序号 = 1%1024 = 1;
这样的话,对于user_id=262145,将被路由到第0个数据库的第1个表中。
示意图如下:
五、分库分表总结
关于分库分表策略的选择有很多种,上文中根据用户ID应该是比较简单的一种。其他方式比如使用号段进行分区或者直接使用hash进行路由等。有兴趣的可以自行查找学习。
关于上文中提到的,如果用户的ID是通过UUID的方式生成的话,我们需要单独的进行一次hash操作,然后在进行取模操作等,其实hash本身就是一种分库分表的策略,使用hash进行路由策略的时候,我们需要知道的是,也就是hash路由策略的优缺点,优点是:数据分布均匀;缺点是:数据迁移的时候麻烦,不能按照机器性能分摊数据。
上述的分库和分表操作,查询性能和并发能力都得到了提高,但是还有一些需要注意的就是,例如:原本跨表的事物变成了分布式事物;由于记录被切分到不同的数据库和不同的数据表中,难以进行多表关联查询,并且不能不指定路由字段对数据进行查询。分库分表之后,如果我们需要对系统进行进一步的扩阵容(路由策略变更),将变得非常不方便,需要我们重新进行数据迁移。
最后需要指出的是,分库分表目前有很多的中间件可供选择,最常见的有MyCat、sharding-sphere等。
以上是关于6策略--数据库分库分表策略的主要内容,如果未能解决你的问题,请参考以下文章