ES的跨索引查询有多便利?对比下分库分表分片更直观
Posted 一诺大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES的跨索引查询有多便利?对比下分库分表分片更直观相关的知识,希望对你有一定的参考价值。
作者介绍
李猛(ynuosoft),Elastic-stack产品深度用户,ES认证工程师,2012年接触Elasticsearch,对Elastic-Stack开发、架构、运维等方面有深入体验,实践过多种Elasticsearch项目,最暴力的大数据分析应用,最复杂的业务系统应用;业余为企业提供Elastic-stack咨询培训以及调优实施。
Elasticsearch,中文名直译弹性搜索,不仅仅在单索引内部分片层面弹性搜索,更强的是在跨索引外围支持分片弹性搜索,同比其它分布式数据产品,此特性更鲜明,代表了Elastic集群架构设计的优越性。
本文将从以下几个方面展开探讨:
为什么需要跨索引查询?
跨索查询有哪些经典应用场景?
跨索引查询技术原理是怎样的?
跨索引查询有哪些注意事项?
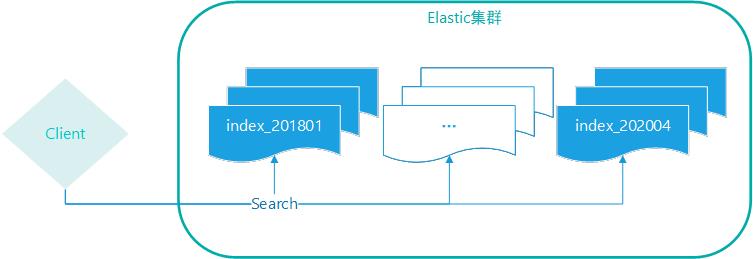
图示:跨索引示意图+多个索引查询效果图
Elasticsearch索引本身有一些指标限制,对于很多新手来说最容易忽视或者乱用。
Elastic索引数据量有大小限制;
单个分片数据容量官方建议不超过50GB,合理范围是20GB~40GB之间;
单个分片数据条数不超过约21亿条(2的32次方),此值一般很难达到,基本可以忽略,背后原理可以参考源码或者其它;
索引分片过多,分布式资源消耗越大,查询响应越慢。
基于以上限制,索引在创建之前就需要依据业务场景估算,设置合理的分片数,不能过多也不能过少。
在基于关系型数据库的应用场景中,数据量过大,一般会采用分库分表策略,查询数据时基于第三方中间件,限制多多;在基于NoSQL的应用场景中,如MongoDB,数据量过大,会采用数据产品本身提供的分片特性,查询数据时基于自身的路由机制。
无论是分库分表还是分片,它们只解决了一维数据的存储与查询,二维的不能,如电商订单系统场景,数据库采用多库多表拆分,一旦容量超过预期设计,需要二次拆分继续分库分表;MongoDB采用多分片拆分,一旦容量超过预计设计,需要继续扩展分片节点。
以上对于Elasticsearch可以不用这样,它提供了两个维度的拆分方式,第一维度采用多个索引命名拆分,第二维度采用索引多分片,对于查询来说,可以灵活匹配索引,一次指定一个索引,也可以一次指定多个索引。
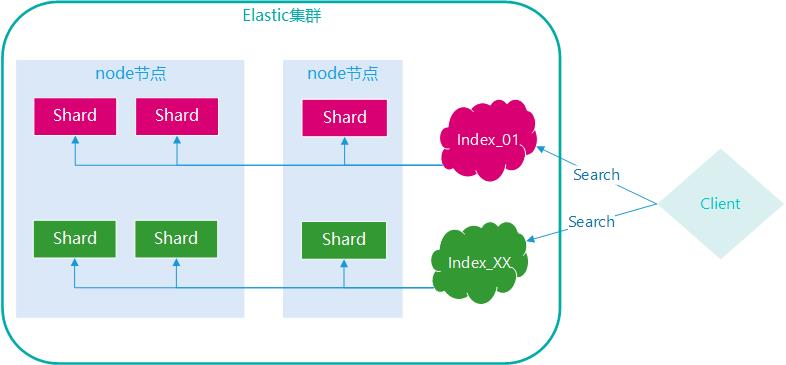
图示:ES查询示意图+多索引+多分片示意图
IT应用中,除去技术本身局限问题,多数的问题都是由于耦合造成的,“高内聚,低耦合”一直是我们IT从业者的座右铭。应用系统耦合,就成了单体应用,然后就延伸出微服务架构理念。同样数据耦合,我们也要基于一定维度的微服务化,或垂直或水平或混合垂直水平。
举例某些业务场景,实时数据与历史数据存储和查询问题,假设日均数据量超过千万条,那么月度数量超过3亿条,年度也会超过36亿条。
若采用Elasticsearch存储,则可以按月/按季度/按年度 创建索引,这样实时数据的更新只会影响当前的索引,不影响历史的索引;查询时也一样,依据查询条件指定索引名称,按需要扫描查询,无需每次扫描所有的数据。这比基于传统的数据产品灵活很多。
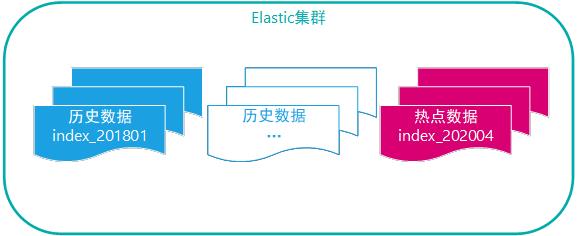
图示:实时数据与历史数据业务场景
Elasticsearch在大数据应用场景下很受欢迎,已经成为大数据平台对外提供结果查询的标配。大数据平台需要定期计算数据,将结果数据批量写入到Elasticsearch中,供业务系统查询,由于部分业务规则设定,Elasticsearch原来的索引数据要全部删除,并重新写入,这种操作很频繁。对于大数据平台每次全量计算,代价很大,对于Elasticsearch平台,超大索引数据频繁删除重建,代价也很大。
基于以上,采用多索引方式,如按照月份拆解,依据需要删除的月份索引数据。同样的问题,业务系统查询时,非常灵活指定需要的月份索引数据,这样保证了存储与查询的平衡。
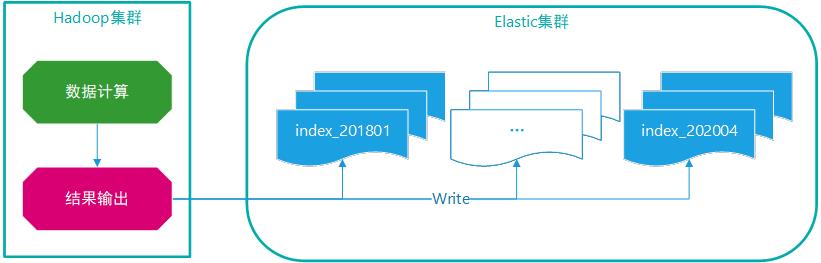
图示:大数据平台写数据到Elastic平台示意图
Elasticsearch应对这个日志场景非常擅长,诞生了著名的ELK组合,比如一个大中型的业务系统,每天日志量几十TB/几百TB很正常,可按天或者按小时或者更小粒度创建索引,通常查询日志只会查询最近时间的,过去很久的日志,偶然需要查询几次,甚至会删除。所以对于此场景,Elasticsearch的跨索引查询非常便利,程序编写也很简单。
Elasticsearch跨索引查询的方式可依据业务场景灵活选择,下面介绍几种:
明确指定多个索引名称,这种方式一般应用在非常精确的查询场景下,便于查询索引范围,性能平衡考虑,若索引不存在会出现错误,如下:index_01,index_02
GET /index_01,index_02/_search
{
"query" : {
"match": {
"test": "data"
}
}
}
不限定死索引名称,这种方式一般采用通配符,无需判断该索引是否存在,支持前匹配、后匹配,前后匹配,如下:index_* 匹配前缀一样的所有索引
GET /index_*/_search
{
"query" : {
"match": {
"test": "data"
}
}
}
索引名称通过计算表达式指定,类似正则表达式,也可以同时指定多个索引,如下:logstash-{now/d}表示当前日期
# 索引名称如:index-2024.03.22
# GET /<index-{now/d}>/_search
GET /%3Cindex-%7Bnow%2Fd%7D%3E/_search{
"query" : {
"match": {
"test": "data"
}
}
}
Elasticsearch能够做到跨索引查询,离不开其架构设计以及相关实现原理。
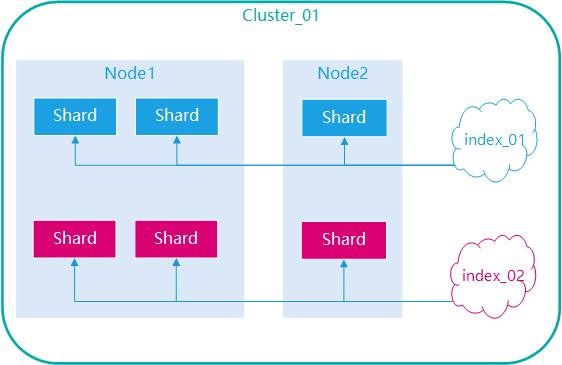
图示 :索引由分片组成
索引是一个虚拟的数据集合,索引由多个分片组成;
分片存储实际的数据;
索引分片数量不限制。
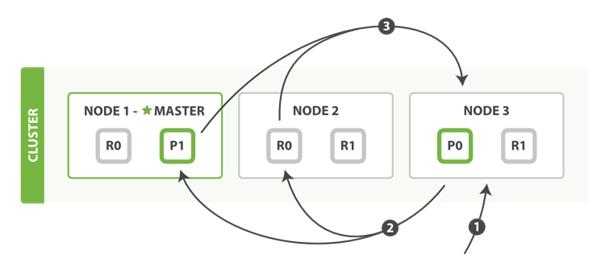
图示:索引查询阶段
图示:取回数据阶段
查询过程简单说来就是分发与合并:
查询分发,客户端发送请求到协调节点,协调节点分发查询请求到索引分片节点;
数据合并,索引分片节点将数据发送到协调节点,协调节点合并返回客户端。
所以说,Elasticsearch提供跨索引查询的能力,实际上与原来单索引查询时一样,本质上是跨多个分片查询,然后合并。
索引与分片等价的关系,1个索引20分片与4个索引每个索引5个分片理论上是等价的,鉴于索引分片的容量限制与性能平衡,在面对需要跨索引业务场景时,索引的数量与分片的数量尽量的少,既要保障索引热点数据的实时处理能力,也要平衡历史数据的查询性能。
鉴于Elastic查询过程,在跨多个索引查询时,协调节点承担了所有分片查询返回的数据合并,需要消耗很大资源,在应对高并发场景,建议部署独立的协调节点,将集群的数据节点与协调节点分离,以达到最佳的性能平衡。
Elasticsearch写入数据分布默认是基于索引主键_id的Hash值,此机制在数据分布上很均衡,但也没有什么规律,对于跨索引查询场景,若自定义指定路由键,可以在搜索时避开不需要的索引分片,有效减少分片查询的分片数量,达到更高的性能。
Elasticsearch由于其架构设计的弹性能力,小小的一个跨索引查询特性,就能给我们应用系统带来很多架构设计的便利,解决很多实际场景问题,这是其它数据产品目前还做不到的。Elasticsearch还有更厉害的跨多个集群跨多个版本,详情可继续关注笔者下一篇文章的探讨。
还是那句话,Elastic用得好,下班下得早。
《All in Cloud 时代,下一代云原生数据库技术与趋势》阿里巴巴集团副总裁/达摩院首席数据库科学家 李飞飞(飞刀)
《AI和云原生时代的数据库进化之路》腾讯数据库产品中心总经理 林晓斌(丁奇)
《ICBC的mysql探索之路》工商银行软件开发中心 魏亚东
《民生银行在SQL审核方面的探索和实践》民生银行资深数据库专家 李宁宁
《OceanBase分布式数据库在西安银行的落地和实践》蚂蚁金服P9资深专家/OceanBase核心负责人 蒋志勇
《金融行业MySQL高可用实践》爱可生技术总监 明溪源
以上是关于ES的跨索引查询有多便利?对比下分库分表分片更直观的主要内容,如果未能解决你的问题,请参考以下文章