且谈分库分表
Posted 半场摇摆人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了且谈分库分表相关的知识,希望对你有一定的参考价值。
干互联网的大多数应该都听过分库分表,但是我们有没有想过,什么时候需要分库分表呢,当数据达到什么体量的情况下我们需要进行大表拆分呢?阿里巴巴的《java开发手册》有写到,当单表数据量超过500万行或者2G的时候,就需要对单表进行分库分表设计了,这个是和数据库的配置以及机器硬件指标决定的。
当我们在做数据库设计的时候,我们可以事先预估下我们的数据体量,若是感觉在2-3年就能达到500万的情况下才需要事先做分库分表设计,否则无需分库分表。
那到底如何进行分库分表呢?
分库分表有两种比较常见方案:垂直拆分和水平拆分
垂直拆分
垂直拆分又可以分成垂直分表和垂直分库。所谓垂直分表就是指将某个表的列字段拆分到不同的表里。而垂直分库则是根据业务将不同的表分到不同的库中,例如商品相关的表放到商品库,订单相关的表放到订单库。
水平拆分
水平拆分也可以分成水平分表和水平分。之前我们说过,数据的行数超过500万行的时候就需要进行分库分表,水平分表是指将原先的单表分成n个子表,然后将数据均匀分布到这n个子表中。水平分库则指将原先单表数据分布到不同的数据库中。
一般,我们在服务化的时候,系统拆分成不同的中心,每个中心有自己独立的数据库。这一步就相当于进行了数据库的垂直拆分。而服务化之后各个中心的数据仍然会过大,这时候我们就需要进行水平拆分。所以我们接下来主要围绕着水平拆分去展开。
如何水平拆分
上面我们讲过,水平拆分是将原来的table数据分布到新的table1-tableN中,那如何进行数据分布呢?
具体方案:
按照数据的时间进行拆分,比如2018在table1,2019在table2,2020在table3。这样的分法会带来一个问题,就是数据分散不均匀,有可能去年的数据量特别大,结果去年还是在同一个表上面。
按照数据的范围进行拆分,例如id是0-10000的在一个表,10001-20000的在另一个表。这种方案仍然没有解决集中写入的问题
按照地理位置进行拆分,例如不同的省在不同的表中。这种方式没法解决数据分布不均匀
按照key的hash值进行拆分,也就取模拆分。以商品库为例,将商品id取模,分布到不同的库和表当中。此种方式既可以解决数据分布问题,也解决集中写入的问题。所以业界很多采用hash的方式
分库分表还需要考虑一个问题就是:主键id如何生成
在没有分库分表的时候,我们可以采用数据库自增id作为主键id。但是一旦涉及到分库分表,这种单表自增id就没办法保证全局唯一性。那有什么解决办法呢?
利用数据库集群并且设置步长
优点:解决了自增id的单点问题
缺点:固定了步长,如果想要扩容,就会比较麻烦
twitter snowflake算法
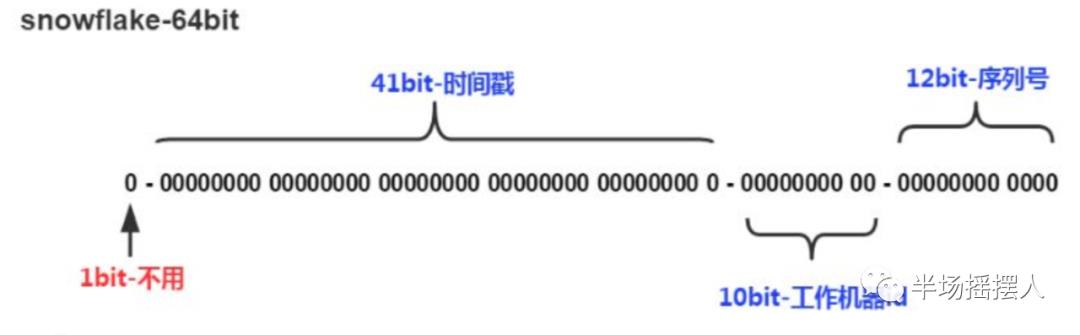
snowflake算法网上介绍的比较多,大致就是生成一个64位的二进制整数。
1位标识符:不使用
41位时间戳:存储当前时间和开始时间的差值
10位机器id:可以拆分成机房id+机器id
12位序列号:在同一时间戳,同一机器id的情况下,能够产生4096个不一样的id
uuid
本地生成随机id,但是这种方案生成的id较长,且有重复概率
讨论完方案之后,再来讨论下数据怎么迁移的问题
方案1:停机迁移法
这是大家很直观想到的方法,既然是要将老库的数据迁移到新库,那如何确保在迁移的过程中不出现访问出错呢,那就不让访问就好。比如晚上1点开始暂停服务,等到迁移完毕再开始服务。具体如下图所示:
停机迁移法会带来的问题就是服务有一段时间不可用,有没有更好的方法在保证服务的同时进行数据的迁移呢
方案二:数据库双写法
所谓数据库双写就是指在迁移过程中,服务产生的数据写两份,一份落到老的库中,一份落到新的库中。等到迁移程序将老库的数据迁移完毕,然后再交验完数据一致性之后,将写老库的程序删除,保留写新库的程序。如下图所示:
其中无论停机迁移还是双写迁移,都会用到中间件,这其实就是分库分表的中间件,像mycat、sharding-jdbc等。
数据库双写法具体步骤:
服务需要提供双写功能,写额外的程序,在写老库的同时将内容更新到新库
通过数据库迁移工具进行数据迁移
数据迁移工具完成迁移之后,校验新老库数据的一致性。同样可以通过一致性校验工具来判断
一致性校验完成之后,将双写程序切到只写新库,等稳定后删除双写程序,只写新库
以上是关于且谈分库分表的主要内容,如果未能解决你的问题,请参考以下文章