数据结构与算法 神速Hash(下)
Posted 码农有道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法 神速Hash(下)相关的知识,希望对你有一定的参考价值。
在上文介绍了hash函数,并提到了冲突的问题,今天我们就聊聊Hash函数出现冲突的解决办法。
次日清晨,大臣们按时上朝,接着讨论昨日的话题
“昨日Hash函数的选择我们已经有了具体的方案了,那就只剩下冲突的解决问题了”,王大臣率先发话
“要解决冲突其实也不难,既然会有多个元素被Hash到同一个位置,而这个位置只能存储一个元素,那么我让这个位置可以存储多个元素不就可以了吗?”,何大臣说道
“哦,怎么个弄法?”王大臣问道
“用链表啊,让这个位置存储一个指针,指向一个链表,每来一个映射到该位置的元素,就放到该位置指针所指的链表中,这样所有相同位置的元素都放在这个链表中”,何大臣回答道,怕大家还不明白,接着又画了一个图
在存储的时候,如果多个元素被Hash到同一位置,那么就加入到该位置所指向的链表中,如果该位置没有元素,则为null(指向空)”,何大臣解释道
“那么在你的图中, 1 和 6 谁先存放进来呢?”,思维缜密的王大人问道
“这个当然是6了,因为这个插入链表的时候要采用‘头插’的方式,也就是插入链表的最前面(图中里数组最近的元素)”,何大人说道
"哦,这是为什么呢?",王大人追问道
“因为经常发生这样的事情:新加入的元素很可能被再次访问到,所以放到头的话,如果查找就不用再遍历链表了”,见多识广的何大人解释道
“这样解决冲突固然好,但是也有瓶颈啊”,寡言的李大臣又发言了
哦,什么瓶颈?”,何大人问道
“你看啊,假设咱们的Hash函数设计的非常好,能够将元素均匀Hash(散列)开来,但是当我们实际存入的值越来越多的时候,这个链表也势必越来越长,那当我们进行查找的时候,势必就会遍历链表,效率也就越来越慢”,李大臣回应道,顺便画了一个图
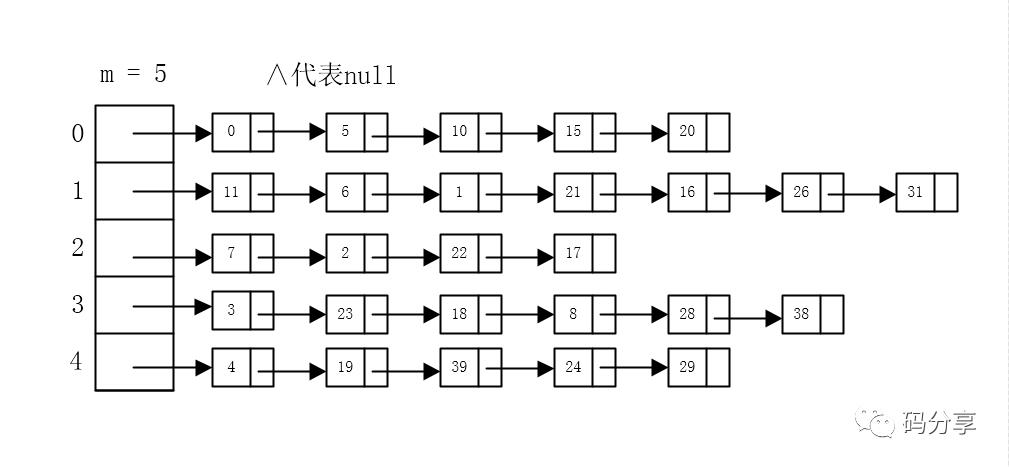
“这样的话,随着链表的不断增长,查询某一个元素的时间也就增加了,如果链表长度远远大于数组长度,不就和用链表存储一样了吗?”,李大臣说道
“恩恩,对,李大臣说的极是,李大臣有何高见?”,何大臣问道
“现在只能扩大数组的长度大约为原来的两倍,然后选取一个相关的新的Hash函数(比如之前使用 key % m,现在只改变一下m的值)将旧Hash表中所有的元素通过新的Hash函数计算出新的Hash值,并将其插入到新表中(仍然使用链表),这就叫rehash吧”,李大臣说完又画了一个图
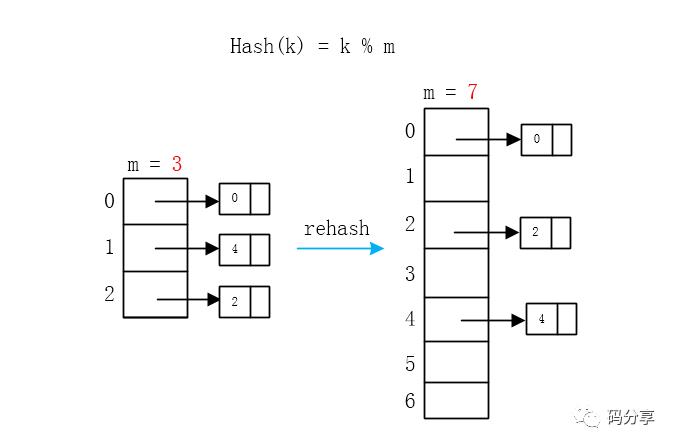
“这里的数组就扩大了近两倍,由于要大小要选素数,那就选原数组大小两倍后的第一个素数7,旧Hash表和新Hash表采用了不同的Hash函数,但相关,只是m的取值变了”李大臣解释道
哦,这样做确实是一种办法,但是问题随之而来,就是什么时候开始rehash”,何大臣说道
“我们可以定义这样一个变量 α = 所有元素个数/数组的大小,我们叫它装载因子吧,它代表着我们的Hash表(也就是数组)的装满程度,在这里也代表链表的平均长度
比如说,我们的数组大小为 5 ,我们给里面存入 3个元素,那么 α = 3/5 =0.6, 这个Hash表装满程度为60%,平均每条链有0.6个元素,当然 α 也可以等于和大于 1 ”,李大臣说道
“哦,引入这个装载因子有何用意?”,何大臣问道
“这个装载因子代表了Hash表的装满程度,这里也可以代表链表的平均长度,那么也就可以代表查询时的时间长短了
基于此,我们为了不让查询时间长,也就是查询性能低,我们可以设置一个临界 α 值,当随着存入元素导致 α 大于这个临界 α 值的时候
我们可以通过rehash来调整当前的 α 值,使之低于我们设定的 临界 α 值,从而使我们的查询性能保持在较好的范围之内”,李大臣答道
“比如说,我们设定 临界 α = 0.7,对于一个Hash表大小为5的Hash表而言,当存入存入第四个元素的时候,α 就超出了临界 α 值,我们可以将数组长度变为11进行rehash(因为11是原表两倍后的第一个素数),使得装载因子 α 小于 0.7”,李大臣举了一个例子并画了一个图
“通过rehash我们可以使得装载因子在一定范围内,那我们的查询性能也就得到了保证了”,李大臣说道
“哦,那这个 临界的 α 值应该选择多大呢?”何大臣追问道
“这个 临界 α 如果选的小了,那数组的空间利用率就会太低,就比如说数组大小为100,α = 0.01,那装满程度为1%,99%还没有被利用
如果 α 太大了,那冲突就会很多,比如说 数组大小为 5,α = 10, 那平均每条链有10个元素,装满程度为1000%,即使Hash函数设计的合理,基本上每次存放元素的时候就会冲突,所以鉴于两者之间我觉得 0.6 - 0.9 之间是一个不错的选择,不妨选0.75吧”,李大臣回答道
大家一致同意
推荐阅读:
专注服务器后台技术栈知识总结分享
欢迎关注交流共同进步
码农有道,为您提供通俗易懂的技术文章,让技术变的更简单!
以上是关于数据结构与算法 神速Hash(下)的主要内容,如果未能解决你的问题,请参考以下文章