经典数据结构与算法--查找与排序
Posted 架构之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经典数据结构与算法--查找与排序相关的知识,希望对你有一定的参考价值。
1 线性查找
1.1 问题
线性查找,又称为顺序查找,是指在所有给定的值中从一端开始逐个检查每个元素是否为要查找的对象,直到找到为止的过程。
1.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:逐个查找要查找的对象
代码如下:
#include <stdio.h>
typedef char DataType;
int mySearch(DataType *ts, int n, const DataType d) {
for (int i = 0; i < n; i++)
if (ts[i] == d)
return i;
return -1;
}
上述代码中,以下代码:
int mySearch(DataType *ts, int n, const DataType d) {
是线性查找的函数头,它有三个形参,第一个形参是要查找的数组,第二个形参是数组中元素的个数,第三个形参是要查找的对象。
1.3 完整代码
本案例的完整代码如下所示:
#include <stdio.h>
typedef char DataType;
int mySearch(DataType *ts, int n, const DataType d) {
for (int i = 0; i < n; i++)
if (ts[i] == d)
return i;
return -1;
}
int main()
{
char cs[6] = {'*','A','B','C','D','E'};
printf("%d\n", mySearch(cs, 6, '*'));
printf("%d\n", mySearch(cs, 6, 'A'));
printf("%d\n", mySearch(cs, 6, 'D'));
printf("%d\n", mySearch(cs, 6, 'C'));
}
2 二分查找
2.1 问题
二分查找算法,又称折半搜索、二分搜索,是一种在有序数组中查找某一特定元素的搜索算法。
二分查找算法的查找过程是这样的。首先,要求待查找的数组是排好序的数组,我们假设数组是升序的,即从小到大排序。然后,将要查找的元素与数组的中间元素相对比,如果相等,则表示要查找的元素被找到了,并停止查找;如果要查找的元素小于数组的中间元素,则从数组中间元素开始到数组最后的元素都大于要查找的元素,也就不需要在其中查找了,只需要在数组中间元素到数组第一个元素之间查找;如果要查找的元素大于数组的中间元素,则从数组中间元素到数组第一个元素都小于要查找的元素,也就不需要在其中查找了,只需要在数组中间元素到数组最后的元素之间查找。
由此可见,二分查找算法在查找的过程中只需对比一次,就可以使待查找的对象个数减少一半。查找速度非常快,所以二分查找算法得到了广泛的应用。
2.2 方案
为了理解二分查找算法,我们先假设有一个长度为11的数组,数组内容如图-1所示:
图-1
图-1中的数组是排好序的数组,从小到大排序。数组左边的数字7为数组的第一个元素,数组右边的数字94为数组的最后一个元素。要查找的元素假设为22。查找过程如下:
首先,确定查找范围,因为是第一次在数组中查找,所以整个数组都是待查找的范围,这样将带查找范围的下界low定为数组的第一个元素7,上界high定为数组的最后一个元素94,那么在上下界中间的元素就是数组元素56,我们用mid表示。
然后,将要查找的元素22与中间的元素,即数组元素56,相对比。因为22小于56,所以从中间元素mid到数组的上界high之间的所有元素都大于22,由图-1可以看出,mid到high之间分别是56、66、79、84、88、94,它们都大于22。由此可知这些元素都可以排除在下次查找的范围内了。即一次对比,就可以使待查找的对象个数减少一半。
最后,确定新的待查找范围,如图-2所示:

图-2
新的查找范围的下界low定为数组的第一个元素7,上界high定为数组的元素40,因为在上一次查找的过程中,数组元素56、66、79、84、88、94均已被排除在查找范围之外了。由上下界可以得到中间元素的数组元素为18,用mid表示。
然后,将要查找的元素22与中间的元素,即数组元素18,相对比。因为22大于18,所以从中间元素mid到数组的下界low之间的所有元素都小于22,由图-2可以看出,low到mid之间分别是7、12、18,它们都小于22。由此可知这些元素也都可以排除在下次查找的范围内了。
这样,再确定新的查找范围,如图-3所示:
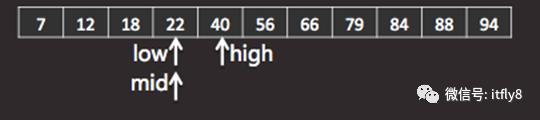
图-3
新的查找范围的下界low定为数组元素22,上界high定为数组的元素40,因为在上一次查找的过程中,数组元素7、12、18均已被排除在查找范围之外了。由于上下界之间只有2个元素,所以中间元素的数组元素为22,用mid表示。
然后,将要查找的元素22与中间的元素,即数组元素22,相对比。因为相等,所以在数组中找到了要查找的元素。程序结束。
2.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:定义上下界
1)定义一个变量L,用于代表下界。
2)定义一个变量R,用于代表上界。
代码如下:
int mySearch(DataType *ts, int n, const DataType d) {
int L = 0;
int R = n - 1;
}
步骤二:确定中间点
1)定义一个变量M,用于代表中间点。
2)将中间点元素与要查找的元素对比,如果相等,则表示找到了要查找的元素,程序退出。
代码如下:
int mySearch(DataType *ts, int n, const DataType d) {
int L = 0;
int R = n - 1;
int M = (L + R)/2;
if (ts[M] == d) return M;
}
步骤三:重新确定查找范围
如果中间点元素小于要查找的元素,则将下界L更改为M+1,否则将上界R更改为M-1。
代码如下:
int mySearch(DataType *ts, int n, const DataType d) {
int L = 0;
int R = n - 1;
int M = (L + R)/2;
if (ts[M] == d) return M;
if (ts[M] < d)
L = M+1;
else
R = M - 1;
return -1;
}
步骤四:按新范围重新查找
如果,一次未找到,则需要设置循环反复查找,直到找到或待查找范围内的元素个数为0。
代码如下:
int mySearch(DataType *ts, int n, const DataType d) {
int L = 0;
int R = n - 1;
while (L <= R) {
int M = (L + R)/2;
if (ts[M] == d) return M;
if (ts[M] < d)
L = M+1;
else
R = M - 1;
}
return -1;
}
上述代码中,以下代码:
while (L <= R) {
中的L<=R这个循环条件为真时,表示待查找范围内的数组元素个数至少为1。当这个循环条件为假时,则表示待查找范围内的数组元素个数已经为0,即没有可查找的对象了。
2.4 完整代码
本案例的完整代码如下所示:
typedef char DataType;
int mySearch(DataType *ts, int n, const DataType d) {
int L = 0;
int R = n - 1;
while (L <= R) {
int M = (L + R)/2;
if (ts[M] == d) return M;
if (ts[M] < d)
L = M+1;
else
R = M - 1;
}
return -1;
}
int main()
{
char cs[6] = {'*','A','B','C','D','E'};
printf("%d\n", mySearch(cs, 6, '*'));
printf("%d\n", mySearch(cs, 6, 'A'));
printf("%d\n", mySearch(cs, 6, 'D'));
printf("%d\n", mySearch(cs, 6, 'C'));
}
3 冒泡排序
3.1 问题
冒泡排序是一种著名的排序方法。
冒泡排序的过程是这样的,首先,将待排序的数组中的第一个元素与第二个元素相对比,如果这两个元素的大小顺序不是我们要求的顺序,则将它们交换过来。然后,将待排序的数组中的第二个元素与第三个元素相对比,如果这两个元素的大小顺序也不是我们要求的顺序,则也将它们交换过来。下一步,是对比第三个元素与第四个元素,直至倒数第二个元素与最后一个元素相对比。这样一趟对比下来,小的数据元素会一点一点的往前放,而大的数据元素会一点一点的往后放。反复多趟的这样对比,直到所有数据都排好序为止。
3.2 方案
为了理解冒泡排序算法,我们先假设有一个长度为10的数组,数组内容如图-4所示:

图-4
图-4中的数组元素为无序状态,现需要将数组内的元素排序成从小到大的升序状态。可以先进行第一趟比较。首先比较第1个和第2个数,也就是数组第一个元素3和数组第二个元素2,将小数放前,大数放后。交换后如图-5所示:

图-5
然后,将图-5中的第2个和第3个数,也就是数组第二个元素3和数组第三个元素4,进行对比,由于3小于4,所以不进行交换。接着将图-5中的第3个和第4个数对比后发现也不需要交换。这样依次进行对比,直到图-5中的第7个和第8个数,也就是数组第七个元素9和数组第八个元素1,对比时,需要将它们交换过来,如图-6所示:

图-6
继续第一趟比较,图-6中的第8个和第9个数,也就是数组第八个元素9和数组第九个元素6,对比时,需要将它们交换过来,如图-7所示:

图-7
第一趟最后比较,图-7中的第9个和第10个数,也就是数组第九个元素9和数组第十个元素0,对比时,需要将它们交换过来,如图-8所示:

图-8
至此,第一趟比较结束,我们会发现数组中的最大值通过不断的位置交换,移到了数组最后一个元素的位置。但其它元素仍然是无序状态。所以需要进行第二趟比较,只是此次比较的范围应刨除数组的最后一个元素。当第二趟比较结束时,倒数第二大的数组元素值会被放置到数组的倒数第二个位置,如图-9所示:

图-9
第二趟比较结束后,依次进行后面的比较,直到数组内的元素按照升序排好为止。整个排序过程如图-10所示:
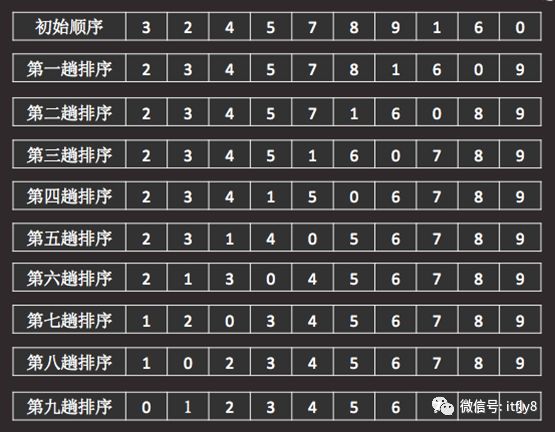
图-10
由图-10可以看出,实现冒泡排序算法时,需要使用嵌套的两个循环来实现:外层循环用于控制排序的趟次,里层循环用于控制每趟排序中的两两交换。
3.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:第一趟比较
设置循环,将待排序数组中的数组元素两两进行比较,如果有不符合要求的顺序的,进行交换。
代码如下所示:
void bubble(DataType* a, int n) {
for (int j = 0; j < n - i - 1; j++) {
if (a[j] > a[j + 1]) {
DataType t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
flag = false;
}
}
}
步骤二:多趟比较,直至排好序
设置外层循环,进行多趟比较。
代码如下所示:
void bubble(DataType* a, int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (a[j] > a[j + 1]) {
DataType t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
flag = false;
}
}
}
}
步骤三:设置标志,提高效率
代码如下所示:
void bubble(DataType* a, int n) {
for (int i = 0; i < n - 1; i++) {
bool flag = true;
for (int j = 0; j < n - i - 1; j++) {
if (a[j] > a[j + 1]) {
DataType t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
flag = false;
}
}
if (flag) break;
}
}
上述代码中,以下代码:
bool flag = true;
定义一个布尔型变量,初始化为真,为真代表数组已经排好序了。
上述代码中,以下代码:
for (int j = 0; j < n - i - 1; j++) {
if (a[j] > a[j + 1]) {
DataType t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
flag = false;
}
}
是进行某趟比较,在该趟比较过程中,如果数组中所有元素两两比较均为假,则就不需要进行交换,而此时flag=false;语句也就不会执行。因此循环退出时,flag为真,即数组已经排好序了。
上述代码中,以下代码:
if (flag) break;
表示如果flag为真,即数组已经排好序,则停止排序。
3.4 完整代码
本案例的完整代码如下所示:
typedef int DataType;
void bubble(DataType* a, int n) {
for (int i = 0; i < n - 1; i++) {
bool flag = true;
for (int j = 0; j < n - i - 1; j++) {
if (a[j] > a[j + 1]) {
DataType t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
flag = false;
}
}
if (flag) break;
}
}
void print(DataType* a, int n) {
for (int i = 0; i < n; i++)
printf("%d ", a[i]);
printf("\n");
}
int main() {
int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0};
bubble(a, 10);
print(a, 10);
return 0;
}
4 插入排序
插入排序算法是一种简单直观的排序算法。
插入排序的过程是这样的,首先,将待排序的数组分成两部分,一部分是已经排好序的部分,另一部分是未排好序的部分。在开始排序前,已排好序的部分只有一个数组元素,即数组的第一个元素;未排好序的部分是数组中除第一个元素外的其它所有元素。然后,将未排好序部分中的第一个数组元素,插入到已排序部分当中适当的位置,以保证已排序部分仍然是保持排序状态。此时,已排序部分就变成两个数组元素,而未排序部分的数组元素同时少了一个。依次类推,逐个从未排好序的部分拿出一个元素,插入到已排序部分当中适当的位置,直至数组按顺序排好为止。
4.1 方案
为了理解插入排序算法,我们先假设有一个长度为10的数组,数组内容如图-17所示:

图-11
图-17中的数组元素为无序状态,现需要将数组内的元素排序成从小到大的升序状态。首先将数组中的所有元素分成两个部分,一部分已排好序的部分,另一部分是未排好序的部分,在开始时,已排好序的部分只有一个数组元素,剩余的数组元素为未排好序的部分,如图-18所示:
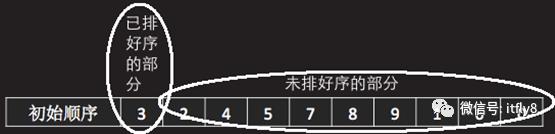
图-12
将未排好序部分的一个元素取出,插入到已排好序部分的适当位置,如图-18中,将数组元素2从未排好序部分取出,与已排好序的部分的数组元素3对比,因为2小于3,所以将2插入到3的前面,如图-19所示:
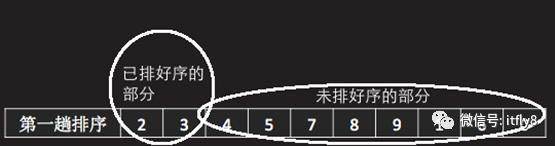
图-13
此时,已排好序的部分变成了2个元素,而未排好序的部分少了一个元素,然后,再将未排好序部分的一个元素取出,插入到已排好序部分的适当位置,如图-19中,将数组元素4从未排好序部分取出,与已排好序的部分的数组元素3对比,因为4大于3,所以直接将4划入已排好序的部分,如图-20所示:
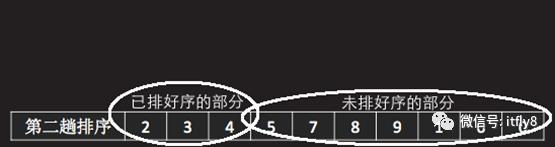
图-14
此时,已排好序的部分变成了3个元素,而未排好序的部分又少了一个元素,依次类推,逐个将未排好序的部分的元素插入到已排序的部分,直至整个数组都排好序为止。整个排序过程如图-21所示:
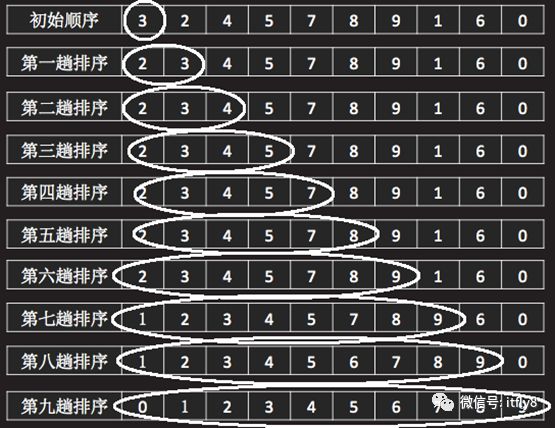
图-15
4.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:将未排序部分的第一个元素插入到已排序部分
首先,定义临时变量,用于保存未排序部分的第一个元素
然后,设置循环,将未排序部分的第一个元素插入到已排序部分。
代码如下所示:
void insert(DataType *a, int n) {
int i = 1;
//把选择的元素放在临时变量中
DataType t = a[i];
int j = 0;
for (j = i; j > 0 && a[j - 1] > t; j--) {
a[j] = a[j - 1];
}
a[j] = t;
}
上述代码中,以下代码:
for (j = i; j > 0 && a[j - 1] > t; j--) {
a[j] = a[j - 1];
}
a[j] = t;
是将未排序部分的第一个元素t插入到已排序部分的适当位置a[j]。
步骤二:将所有未排序部分的元素插入到已排序部分
设置循环,逐个将未排序部分元素取出来,插入到已排序部分。
代码如下所示:
void insert(DataType *a, int n) {
for (int i = 1; i < n; i++) {
//把选择的元素放在临时变量中
DataType t = a[i];
int j = 0;
for (j = i; j > 0 && a[j - 1] > t; j--) {
a[j] = a[j - 1];
}
a[j] = t;
}
}
4.3 完整代码
本案例的完整代码如下所示:
typedef int DataType;
void insert(DataType *a, int n) {
for (int i = 1; i < n; i++) {
//把选择的元素放在临时变量中
DataType t = a[i];
int j = 0;
for (j = i; j > 0 && a[j - 1] > t; j--) {
a[j] = a[j - 1];
}
a[j] = t;
}
}
void print(DataType* a, int n) {
for (int i = 0; i < n; i++)
printf("%d ", a[i]);
printf("\n");
}
int main() {
int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0};
insert(a, 10);
print(a, 10);
return 0;
}
5 选择排序
5.1 问题
选择排序是一种简单直观的排序方法。
选择排序的过程是这样的,首先,在待排序的数组中找到一个最小的数组元素,将该最小数组元素与数组的第一个元素进行交换,这样交换之后,数组的第一个元素就变成了数组元素中的最小值。然后,再在待排序数组的剩余元素中找到一个最小的数组元素,将该最小数组元素与数组的第二个元素进行交换,这样交换之后,数组的第二个元素就变成了数组元素中的第二小的值。依次类推,直至数组按顺序排好为止。
5.2 方案
为了理解选择排序算法,我们先假设有一个长度为10的数组,数组内容如图-11所示:

图-16
图-11中的数组元素为无序状态,现需要将数组内的元素排序成从小到大的升序状态。首先在数组的所有元素中找到一个最小的元素,如图-12所示:

图-17
将该元素与数组的第一个元素进行交换,如图-13所示:

图-18
这样交换之后,数组的第一个元素就变成了数组元素中的最小值。然后,再在除第一个元素外的其它数组元素中,寻找最小的数组元素,如图-14所示:

图-19
将这个第二小的数组元素与数组的第二个位置的元素进行交换,如图-15所示:

图-20
这样交换之后,数组的第二个元素就变成了数组元素中的第二小的值。依次类推,再在剩余的数组元素中找最小值,与数组第三个位置的元素进行交换,直至数组排好序为止。整个排序过程如图-16所示:
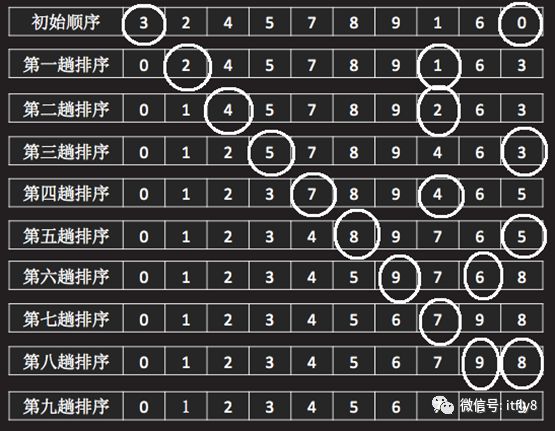
图-21
由图-16可以看出,实现选择排序算法时,需要使用嵌套的两个循环来实现:外层循环用于控制排序的趟次,里层循环用于寻找指定范围内的最小值。
5.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:寻找数组中指定范围内的最小元素
首先,定义一个变量,用于存放最小元素在数组中的下标。
然后,设置循环,遍历数组找出最小元素。
代码如下所示:
void selects(DataType *a, int n) {
int i = 0;
int k = i; //这里认为k就是最小元素的下标
for (int j = i + 1; j < n; j++) {
if (a[j] < a[k]) {
k = j;
}
}
}
步骤二:将最小元素与数组第一个位置的元素交换
代码如下所示:
void selects(DataType *a, int n) {
int i = 0;
int k = i; //这里认为k就是最小
for (int j = i + 1; j < n; j++) {
if (a[j] < a[k]) {
k = j;
}
}
if (k != i) {
swap(a[k], a[i]);
}
}
上述代码中,以下代码:
if (k != i) {
是判断最小元素的下标是否就是数组第一个位置元素的下标,如果是则不需要再进行交换。
步骤三:将数组剩余元素排序
设置外层循环,依次寻找最小元素并进行交换。
代码如下所示:
void selects(DataType *a, int n) {
for (int i = 0; i < n - 1; i++) {
int k = i; //这里认为k就是最小
for (int j = i + 1; j < n; j++) {
if (a[j] < a[k]) {
k = j;
}
}
if (k != i) {
swap(a[k], a[i]);
}
}
}
5.4 完整代码
本案例的完整代码如下所示:
typedef int DataType;
void selects(DataType *a, int n) {
for (int i = 0; i < n - 1; i++) {
int k = i; //这里认为k就是最小
for (int j = i + 1; j < n; j++) {
if (a[j] < a[k]) {
k = j;
}
}
if (k != i) {
swap(a[k], a[i]);
}
}
}
void print(DataType* a, int n) {
for (int i = 0; i < n; i++)
printf("%d ", a[i]);
printf("\n");
}
int main() {
int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0};
selects(a, 10);
print(a, 10);
return 0;
}
6 快速排序
6.1 问题
快速排序算法是一种基于交换的排序,系统地交换反序的记录的偶对,直到不再有这样一来的偶对为止。它是对冒泡排序的一种改进。
快速排序的过程是这样的。首先,将待排序的数组从前向后和从后向前各取出一个元素进行对比交换,从而将待排序的数组分成两个部分,前一部分的所有元素都小于后一部分的所有元素,但前后两部分内部仍然是无序的状态。然后再将前一部分的所有元素从前向后和从后向前各取出一个元素进行对比交换,从而将前一部分的所有元素再分成两个部分,这两部分的前一部分的所有元素都小于后一部分的所有元素,依次类推,直到被分割的部分只有一个元素为止。下一步,再将后一部分的所有元素从前向后和从后向前各取出一个元素进行对比交换并分成两个部分。这样分到最后,数组将排好序。
6.2 方案
为了理解快速排序算法,我们先假设有一个长度为10的数组,数组内容如图-22所示:

图-22
图-22中的数组元素为无序状态,现需要将数组内的元素排序成从小到大的升序状态。首先将数组中的第一个元素3与最后一个元素0进行比较,因为3大于0,所以将它们两个进行交换,如图-23所示:

图-23
然后,将数组的第二个元素2与数组的最后一个元素3进行比较,因为2小于3,所以再那数组的第三个元素4与数组的最后一个元素3进行比较,因为4大于3,所以将它们两个进行交换,如图-24所示:

图-24
下一步,将数组的第三个元素3与数组的倒数第二个元素6进行比较,因为3小于6,所以再那数组的第三个元素3与数组的倒数第三个元素1进行比较,因为3大于1,所以将它们两个进行交换,如图-25所示:

图-25
下一步,将数组的第四个元素5与数组的倒数第三个元素3进行比较,因为5大于3,所以将它们两个进行交换,如图-26所示:

图-26
下一步,将数组的第四个元素3与数组的倒数第四个元素9进行比较,因为3小于9,所以再那数组的第四个元素3与数组的倒数第五个元素8进行比较,还因为3小于8,所以再那数组的第四个元素3与数组的倒数第六个元素7进行比较,再因为3小于7,不进行交换,至此将数组分成了两个部分,如图-27所示:

图-27
前一部分的所有元素均小于后一部分的所有元素。最后,先将前一部分按上述方法再分,再将后一部分再分,直到每一部分只有一个元素,无需排序为止。因为前一部分总是比后一部分小,所以当排序停止时,数组就已经排好序了。
6.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:终止分组条件
当只有一个元素时,停止排序。
代码如下:
void qsorts(DataType *a, int n) {
if(n <= 1) return;
}
上述代码中,形参变量n得到的是数组元素个数 ,当n小于等于1时,使函数返回。
步骤二:将数组分成两部分
首先,定义一个变量L,用于存储数组的上界
然后,再定义一个变量R,用于存储数组的下界。
最后,设置循环将数组分成两部分
代码如下:
void qsorts(DataType *a, int n) {
if(n <= 1) return;
int L = 0;
int R = n - 1;
while (L < R) {
//一次分组
while (L < R && a[L] <= a[R]) R--;
DataType t = a[L];
a[L] = a[R];
a[R] = t;
while (L < R && a[L] <= a[R]) L++;
t = a[L];
a[L] = a[R];
a[R] = t;
}
}
上述代码中,以下代码:
while (L < R && a[L] <= a[R]) R--;
DataType t = a[L];
a[L] = a[R];
a[R] = t;
是从后向前寻找不符合顺序的元素,找到后,将其进行交换。
上述代码中,以下代码:
while (L < R && a[L] <= a[R]) L++;
t = a[L];
a[L] = a[R];
a[R] = t;
是从前向后寻找不符合顺序的元素,找到后,将其进行交换。
步骤三:递归分组
将分好的前后两部分用递归的方法再分。
代码如下:
void qsorts(DataType *a, int n) {
if(n <= 1) return;
int L = 0;
int R = n - 1;
while (L < R) {
//一次分组
while (L < R && a[L] <= a[R]) R--;
DataType t = a[L];
a[L] = a[R];
a[R] = t;
while (L < R && a[L] <= a[R]) L++;
t = a[L];
a[L] = a[R];
a[R] = t;
}
//继续左边分组
qsorts(a, L);
//继续右边分组
qsorts(a + L + 1, n - L - 1);
}
6.4 完整代码
本案例的完整代码如下所示:
typedef int DataType;
void qsorts(DataType *a, int n) {
if(n <= 1) return;
int L = 0;
int R = n - 1;
while (L < R) {
//一次分组
while (L < R && a[L] <= a[R]) R--;
DataType t = a[L];
a[L] = a[R];
a[R] = t;
while (L < R && a[L] <= a[R]) L++;
t = a[L];
a[L] = a[R];
a[R] = t;
}
//继续左边分组
qsorts(a, L);
//继续右边分组
qsorts(a + L + 1, n - L - 1);
}
void print(DataType* a, int n) {
for (int i = 0; i < n; i++)
printf("%d ", a[i]);
printf("\n");
}
int main() {
int a[10] = {3, 2, 4, 5, 7, 8, 9, 1, 6, 0};
qsorts(a, 10);
print(a, 10);
return 0;
}
7 归并排序
7.1 问题
归并排序是将两个已经排好序的序列合并成一个序列的操作。
归并排序的过程是这样的。首先,将待排序的数组中的元素从中间分为前后两部分。然后再将前一部分继续分成两部份,后一部分也继续分成两部分,依次类推,直到单个元素为止。最后两两按序合并,直到整个数组合并成一个有序数组为止。
7.2 方案
为了理解归并排序算法,我们先假设有一个长度为8的数组,数组内容如图-28所示:

图-28
现需要将数组内的元素先分成前后两部分,如图-29所示:
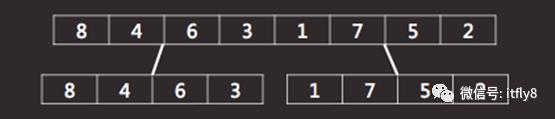
图-29
然后,将前后两部分继续分解,直至单个元素为止,如图-30所示:
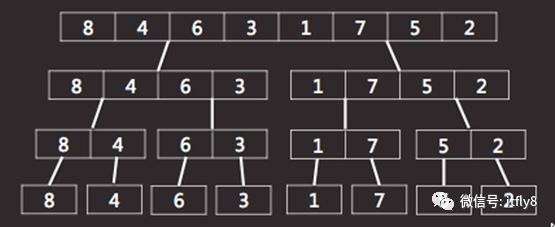
图-30
下一步,重新两两合并,在合并的过程中注意先进行了排序,如图-31所示:
图-31
下一步,继续合并,直至整个数组排好序为止,如图-32所示:
图-32
7.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:将数组分成前后两部分
使用递归方法,将数组先分成前后两部分,然后再将前一部分分解,最后将后一部分分解。
代码如下:
//内部使用递归
void MergeSort(int sourceArr[],int startIndex,int endIndex)
{
int midIndex;
if(startIndex<endIndex)
{
midIndex=(startIndex+endIndex)/2;
MergeSort(sourceArr,startIndex,midIndex);
MergeSort(sourceArr,midIndex+1,endIndex);
}
}
上述代码中,以下代码:
midIndex=(startIndex+endIndex)/2;
是确定将数组分成前后两部分的中间点。
步骤二:将前后两部分重新按序合并
代码如下:
#include<stdlib.h>
#include<stdio.h>
#define SIZE 8
void Merge(int sourceArr[],int startIndex,int midIndex,int endIndex)
{
int start = startIndex;
int i,j,k;
int tempArr[SIZE];
for(i=midIndex+1,j=startIndex;startIndex<=midIndex&&i<=endIndex;j++)
if(sourceArr[startIndex]<=sourceArr[i])
tempArr[j]=sourceArr[startIndex++];
else
tempArr[j]=sourceArr[i++];
if(startIndex<=midIndex)
for(k=0;k<=midIndex-startIndex;k++)
tempArr[j+k]=sourceArr[startIndex+k];
if(i<=endIndex)
for(k=0;k<=endIndex-i;k++)
tempArr[j+k]=sourceArr[i+k];
for(i=start;i<=endIndex;i++)
sourceArr[i]=tempArr[i];
}
//内部使用递归
void MergeSort(int sourceArr[],int startIndex,int endIndex)
{
int midIndex;
if(startIndex<endIndex)
{
midIndex=(startIndex+endIndex)/2;
MergeSort(sourceArr,startIndex,midIndex);
MergeSort(sourceArr,midIndex+1,endIndex);
Merge(sourceArr,startIndex,midIndex,endIndex);
}
}
上述代码中,以下代码:
int tempArr[SIZE];
是定义一个临时数组,用于合并过程中排序时使用。
上述代码中,以下代码:
for(i=midIndex+1,j=startIndex;startIndex<=midIndex&&i<=endIndex;j++)
if(sourceArr[startIndex]<=sourceArr[i])
tempArr[j]=sourceArr[startIndex++];
else
tempArr[j]=sourceArr[i++];
是先挑选前后两部分中小的数组元素放入临时数组。
上述代码中,以下代码:
if(startIndex<=midIndex)
for(k=0;k<=midIndex-startIndex;k++)
tempArr[j+k]=sourceArr[startIndex+k];
是将前一部分中剩余的元素放入临时数组。
上述代码中,以下代码:
if(i<=endIndex)
for(k=0;k<=endIndex-i;k++)
tempArr[j+k]=sourceArr[i+k];
是将后一部分中剩余的元素放入临时数组。
上述代码中,以下代码:
for(i=start;i<=endIndex;i++)
sourceArr[i]=tempArr[i];
是将临时数组内的内容放回到待排序数组中。
7.4 完整代码
本案例的完整代码如下所示:
#include<stdlib.h>
#include<stdio.h>
#define SIZE 8
void Merge(int sourceArr[],int startIndex,int midIndex,int endIndex)
{
int start = startIndex;
int i,j,k;
int tempArr[SIZE];
for(i=midIndex+1,j=startIndex;startIndex<=midIndex&&i<=endIndex;j++)
if(sourceArr[startIndex]<=sourceArr[i])
tempArr[j]=sourceArr[startIndex++];
else
tempArr[j]=sourceArr[i++];
if(startIndex<=midIndex)
for(k=0;k<=midIndex-startIndex;k++)
tempArr[j+k]=sourceArr[startIndex+k];
if(i<=endIndex)
for(k=0;k<=endIndex-i;k++)
tempArr[j+k]=sourceArr[i+k];
for(i=start;i<=endIndex;i++)
sourceArr[i]=tempArr[i];
}
//内部使用递归
void MergeSort(int sourceArr[],int startIndex,int endIndex)
{
int midIndex;
if(startIndex<endIndex)
{
midIndex=(startIndex+endIndex)/2;
MergeSort(sourceArr,startIndex,midIndex);
MergeSort(sourceArr,midIndex+1,endIndex);
Merge(sourceArr,startIndex,midIndex,endIndex);
}
}
//调用
int main(int argc,char * argv[])
{
int a[SIZE] = {8,4,6,3,1,7,5,2};
MergeSort(a,0,SIZE-1);
for(int i=0;i<SIZE;i++)
printf("%d ",a[i]);
printf("\n");
return 0;
}
以上是关于经典数据结构与算法--查找与排序的主要内容,如果未能解决你的问题,请参考以下文章