数据结构与算法——树(二叉二叉搜索树)
Posted 我没有三颗心脏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法——树(二叉二叉搜索树)相关的知识,希望对你有一定的参考价值。
前言:题图无关,现在开始来学习学习树相关的知识
前序文章:
数据结构与算法(1)——数组与链表(https://www.jianshu.com/p/7b93b3570875)
数据结构与算法(2)——栈和队列(https://www.jianshu.com/p/5087c751cb42)
树
什么是树
树是一种类似于链表的数据结构,不过链表的结点是以线性方式简单地指向其后继结点,而树的一个结点可以指向许多个结点;数是一种典型的非线性结构;树结构是以表达具有层次特性的图结构的一种方法;
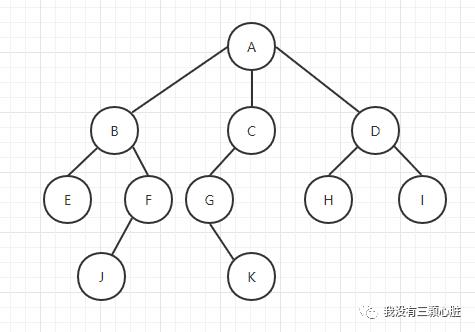
相关术语
根节点:根节点是一个没有双亲结点的结点,一棵树中最多有一个根节点(如上图的结点A就是根节点);
边:边表示从双亲结点到孩子结点的链接(如上图中所有的链接);
叶子结点:没有孩子结点的结点叫作叶子结点(如E、J、K、H和I);
兄弟结点:拥有相同双亲结点的所有孩子结点叫作兄弟结点(B、C、D是A的兄弟结点,E、F是B的兄弟结点);
祖先结点:如果存在一条从根节点到结点q的路径,其结点p出现在这条路径上,那么就可以吧结点p叫作结点q的祖先结点,结点q也叫做p的子孙结点(例如,A、C和G是K的祖先结点);
结点的大小:结点的大小是指子孙的个数,包括其自身。(子树C的大小为3);
树的层:位于相同深度的所有结点的集合叫作树的层(B、C和D具有相同的层,上图的结构有0/1/2/3四个层);
结点的深度:是指从根节点到该节点的路径长度(G点的深度为2,A—C—G);
结点的高度:是指从该节点到最深节点的路径长度,树的高度是指从根节点到书中最深结点的路径长度,只含有根节点的树的高度为0。(B的高度为2,B—F—J);
树的高度:是树中所有结点高度的最大值,树的深度是树中所有结点深度的最大值,对于同一棵树,其深度和高度是相同的,但是对于各个结点,其深度和高度不一定相同;
二叉树
如果一棵树中的每个结点有0,1或者2个孩子结点,那么这棵树就称为二叉树;空树也是一颗有效的二叉树,一颗二叉树可以看做是由根节点和两棵不相交的子树(分别称为左子树和右子树)组成,如下图所示。
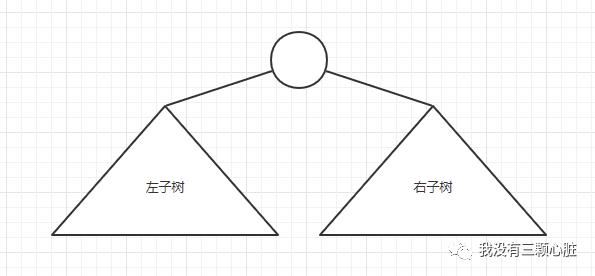
二叉树的类型
严格二叉树:二叉树中的每个节点要么有两个孩子结点,要么没有孩子结点
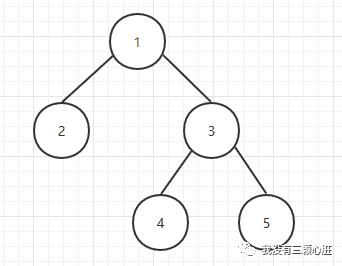
满二叉树:二叉树中的每个结点恰好有两个孩子结点且所有叶子结点都在同一层
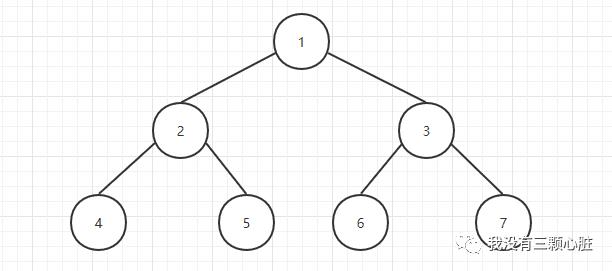
完全二叉树:在定义完全二叉树之前,假定二叉树的高度为h;对于完全二叉树,如果将所有结点从根节点开始从左至右,从上至下,依次编号(假定根节点的编号为1),那么僵得到从1~n(n为结点总数)的完整序列,在遍历过程中对于空指针也赋予编号,如果所有伽椰子结点的深度为h或h-1,且在结点编号序列中没有漏掉任何数字,那么这样的二叉树叫作完全二叉树。
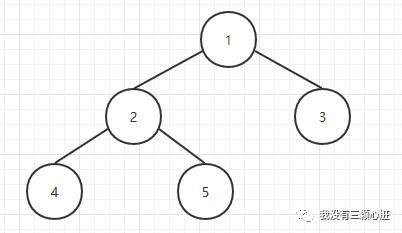
二叉树的应用
编译器中的表达式树;
用于数据压缩算法中的赫夫曼编码树;
支持在集合中查找、插入和删除,其平均时间复杂度为O(lognn)的二叉搜索树(BST);
优先队列(PQ),它支持以对数时间(最坏情况下)对集合中的最小(或最大)数据元素进行搜索和删除;
二叉树的遍历
访问树中所有结点的过程叫作树的遍历,在遍历过程中,每个结点只能被处理一次,尽管其有可能被访问多次;根据结点处理顺序的不同,。可以定义不同的遍历方法,遍历分类可以根据当前节点被处理的顺序来划分:
前序遍历
在前序遍历中,每个结点都是在它的子树遍历之前进行处理,这是最容易理解的便利方法,然而,尽管每个结点在其子树之前进行了处理,但在向下移动的过程仍然需要保留一些信息,以上图为例,首先访问结点1,随后遍历其左子树,最后遍历其右子树,因此当左子树遍历完后,必须要返回到其右子树来继续遍历;为了能够在左子树遍历完成后移动到右子树,必须保留根节点的信息,能够实现该信息存储的抽象数据类型显而易见是栈,由于它是LIFO的结构,所以它可以以逆序来汇过去该信息并返回到右子树;
前序遍历可以如下定义:
访问根节点;
按前序遍历方式遍历左子树;
按前序遍历方式遍历右子树;
利用前序遍历方法上图所示的树的输出序列为:1 2 4 5 3 6 7
void preOrder(BinaryTreeNode root) {
if (null != root) {
System.out.println(root.getData());
preOrder(root.getLeft());
preOrder(root.getRight());
}
}
中序遍历
在中序遍历中,根节点的访问在两棵子树的遍历中间完成,中序遍历如下定义:
按中序遍历方式遍历左子树;
访问根节点;
按中序遍历方式遍历右子树;
基于中序遍历,上图所示树的中序遍历输出顺序为:4 2 5 1 6 3 7
void inOrder(BinaryTreeNode root) {
if (null != root) {
inOrder(root.getLeft());
System.out.println(root.getData());
inOrder(root.getRight());
}
}
后序遍历
在后续遍历中,根节点的访问是在其两棵子树都遍历完成后进行的,后续遍历如下定义:
按后序遍历左子树;
按后序遍历右子树;
访问根节点;
对上图所示的二叉树,后续遍历产生的输出序列为:4 5 2 6 7 3 1
void postOrder(BinaryTreeNode root) {
if (null != root) {
postOrder(root.getLeft());
postOrder(root.getRight());
System.out.println(root.getData());
}
}
层次遍历
层次遍历的定义如下:
访问根节点;
在访问第l层时,将l+1层的节点按顺序保存在队列中;
进入下一层并访问该层的所有结点;
重复上述操作直至所有层都访问完;
对于上图所示的二叉树,层次遍历产生的输出序列为:1 2 3 4 5 6 7
void levelOrder(BinaryTreeNode root) {
BinaryTreeNode temp;
LoopQueue Q = new LoopQueue();
if (null == root) {
return;
}
Q.enqueue(root);
while (!Q.isEmpty()) {
temp = Q.dequeue();
// 处理当前节点
System.out.println(temp.getData());
if (temp.getLeft()) {
Q.enqueue(temp.getLeft());
}
if (temp.getRight()) {
Q.enqueue(temp.getRight());
}
}
// 删除队列中的所有数据
Q.deletequeue();
}
二叉搜索树
在二叉搜索树中,所有左子树结点的元素小于根节点的数据,所有右子树结点的元素大于根节点数据,注意,树中的每个结点都应满足这个性质;
实现自己的二叉搜索树
其中包含了常用的一些方法,包括几种遍历方法还有查询、删除等,仅供参考:
public class BST<E extends Comparable<E>> {
private class Node{
public E e;
public Node left, right;
public Node(E e){
this.e = e;
left = null;
right = null;
}
}
private Node root;
private int size;
public BST(){
root = null;
size = 0;
}
public int size(){
return size;
}
public boolean isEmpty(){
return size == 0;
}
// 向二分搜索树中添加新的元素e
public void add(E e){
root = add(root, e);
}
// 向以node为根的二分搜索树中插入元素e,递归算法
// 返回插入新节点后二分搜索树的根
private Node add(Node node, E e){
if(node == null){
size ++;
return new Node(e);
}
if(e.compareTo(node.e) < 0)
node.left = add(node.left, e);
else if(e.compareTo(node.e) > 0)
node.right = add(node.right, e);
return node;
}
// 看二分搜索树中是否包含元素e
public boolean contains(E e){
return contains(root, e);
}
// 看以node为根的二分搜索树中是否包含元素e, 递归算法
private boolean contains(Node node, E e){
if(node == null)
return false;
if(e.compareTo(node.e) == 0)
return true;
else if(e.compareTo(node.e) < 0)
return contains(node.left, e);
else // e.compareTo(node.e) > 0
return contains(node.right, e);
}
// 二分搜索树的前序遍历
public void preOrder(){
preOrder(root);
}
// 前序遍历以node为根的二分搜索树, 递归算法
private void preOrder(Node node){
if(node == null)
return;
System.out.println(node.e);
preOrder(node.left);
preOrder(node.right);
}
// 二分搜索树的非递归前序遍历
public void preOrderNR(){
Stack<Node> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()){
Node cur = stack.pop();
System.out.println(cur.e);
if(cur.right != null)
stack.push(cur.right);
if(cur.left != null)
stack.push(cur.left);
}
}
// 二分搜索树的中序遍历
public void inOrder(){
inOrder(root);
}
// 中序遍历以node为根的二分搜索树, 递归算法
private void inOrder(Node node){
if(node == null)
return;
inOrder(node.left);
System.out.println(node.e);
inOrder(node.right);
}
// 二分搜索树的后序遍历
public void postOrder(){
postOrder(root);
}
// 后序遍历以node为根的二分搜索树, 递归算法
private void postOrder(Node node){
if(node == null)
return;
postOrder(node.left);
postOrder(node.right);
System.out.println(node.e);
}
// 二分搜索树的层序遍历
public void levelOrder(){
Queue<Node> q = new LinkedList<>();
q.add(root);
while(!q.isEmpty()){
Node cur = q.remove();
System.out.println(cur.e);
if(cur.left != null)
q.add(cur.left);
if(cur.right != null)
q.add(cur.right);
}
}
// 寻找二分搜索树的最小元素
public E minimum(){
if(size == 0)
throw new IllegalArgumentException("BST is empty!");
return minimum(root).e;
}
// 返回以node为根的二分搜索树的最小值所在的节点
private Node minimum(Node node){
if(node.left == null)
return node;
return minimum(node.left);
}
// 寻找二分搜索树的最大元素
public E maximum(){
if(size == 0)
throw new IllegalArgumentException("BST is empty");
return maximum(root).e;
}
// 返回以node为根的二分搜索树的最大值所在的节点
private Node maximum(Node node){
if(node.right == null)
return node;
return maximum(node.right);
}
// 从二分搜索树中删除最小值所在节点, 返回最小值
public E removeMin(){
E ret = minimum();
root = removeMin(root);
return ret;
}
// 删除掉以node为根的二分搜索树中的最小节点
// 返回删除节点后新的二分搜索树的根
private Node removeMin(Node node){
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
return rightNode;
}
node.left = removeMin(node.left);
return node;
}
// 从二分搜索树中删除最大值所在节点
public E removeMax(){
E ret = maximum();
root = removeMax(root);
return ret;
}
// 删除掉以node为根的二分搜索树中的最大节点
// 返回删除节点后新的二分搜索树的根
private Node removeMax(Node node){
if(node.right == null){
Node leftNode = node.left;
node.left = null;
size --;
return leftNode;
}
node.right = removeMax(node.right);
return node;
}
// 从二分搜索树中删除元素为e的节点
public void remove(E e){
root = remove(root, e);
}
// 删除掉以node为根的二分搜索树中值为e的节点, 递归算法
// 返回删除节点后新的二分搜索树的根
private Node remove(Node node, E e){
if( node == null )
return null;
if( e.compareTo(node.e) < 0 ){
node.left = remove(node.left , e);
return node;
}
else if(e.compareTo(node.e) > 0 ){
node.right = remove(node.right, e);
return node;
}
else{ // e.compareTo(node.e) == 0
// 待删除节点左子树为空的情况
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
return rightNode;
}
// 待删除节点右子树为空的情况
if(node.right == null){
Node leftNode = node.left;
node.left = null;
size --;
return leftNode;
}
// 待删除节点左右子树均不为空的情况
// 找到比待删除节点大的最小节点, 即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点的位置
Node successor = minimum(node.right);
successor.right = removeMin(node.right);
successor.left = node.left;
node.left = node.right = null;
return successor;
}
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
generateBSTString(root, 0, res);
return res.toString();
}
// 生成以node为根节点,深度为depth的描述二叉树的字符串
private void generateBSTString(Node node, int depth, StringBuilder res){
if(node == null){
res.append(generateDepthString(depth) + "null\n");
return;
}
res.append(generateDepthString(depth) + node.e +"\n");
generateBSTString(node.left, depth + 1, res);
generateBSTString(node.right, depth + 1, res);
}
private String generateDepthString(int depth){
StringBuilder res = new StringBuilder();
for(int i = 0 ; i < depth ; i ++)
res.append("--");
return res.toString();
}
}
简单总结
还是只是简单复习了一下树的相关知识吧,通过刷LeetCode题目还有参照着剑指Offer对二叉树、二叉搜索树仅仅这两种结构有了一个较深的认识,因为后续还会继续用到,所以这里简单复习一下也无所谓,不过看着题目倒是感觉这样的结构很容易考面试题啊,因为这些结构既重要考点又多…
以上是关于数据结构与算法——树(二叉二叉搜索树)的主要内容,如果未能解决你的问题,请参考以下文章