数据结构与算法外部排序
Posted 码农有道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法外部排序相关的知识,希望对你有一定的参考价值。
码农有道
当我们要排序的文件太大以至于内存无法一次性装下的时候,这时候我们可以使用外部排序,将数据在外部存储器和内存之间来回交换,以达到排序的目的
排序思想
一天晚上,一尘正在呆呆地看着星星,师傅突然坐在了他的旁边
慧能

一尘啊,天上的星星那么多,不妨你给他们按大小排个序吧
哦,这个怎么排?


一尘

慧能
具体到我们的编程,就是给你2G的数据在硬盘上,但是你只有256M的内存可以使用,怎么排这2G的数据呢?
这么小的内存,装不下数据啊,怎么排呢
一尘
慧能
还记得分而治之的思想吗?我们可以采用这种思想把它排好序
具体怎么做呢
一尘
首先我们可以将2G的数据分成8份,分别加载到内存中进行排序,在内存中的排序方法可以用内部排序如快排、希尔等
快速排序可看:
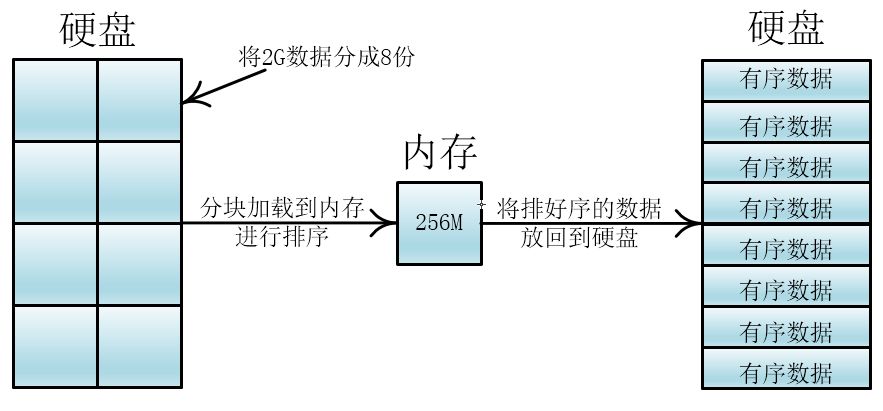
这些已经排好序的数据块我们称之为顺串
然后我们可以将两个顺串通过内存合并成一个顺串(长度为原来的两倍),经过四次合并就完成了
注意:合并操作几乎不需要内存,只需要读入两个元素,选择一个最大的(或最小的)输出,然后再读入,再选择

按照这个方法一直来回合并,一直合并到最终的一个顺串(有序),此时排序完成
慧能
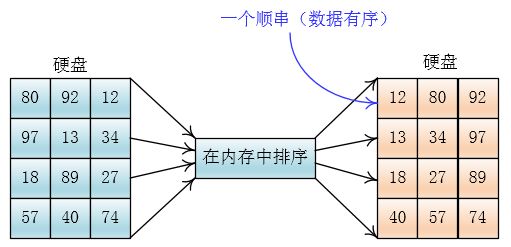
举个实际的例子吧
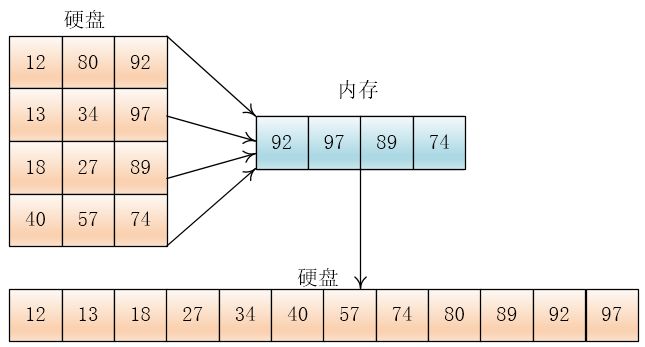
为了简化,设待排数据为:80,92,12,97,13,34,18,98,27,57,40,74,内存一次可以装三个数据

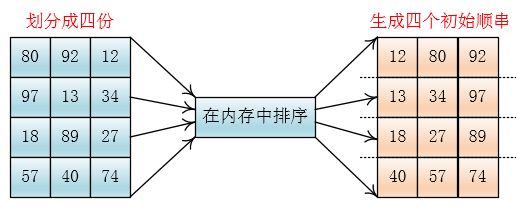
将数据分为四份

然后将每份读入内存,排序后写入硬盘
然后两两合并
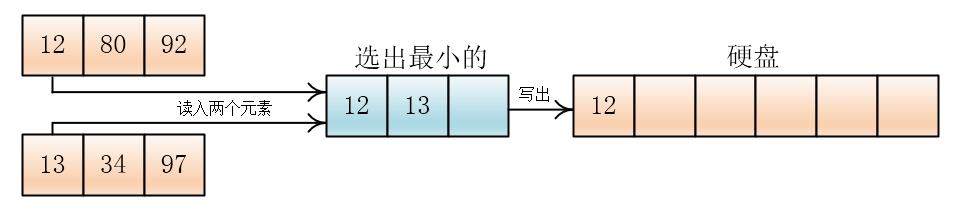
输出哪个元素,就在那个元素所在的顺串(或者叫组)再次读入元素
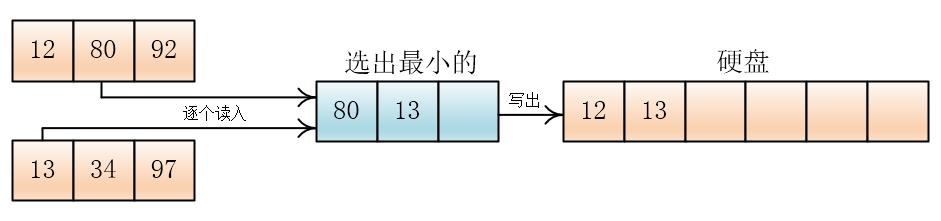
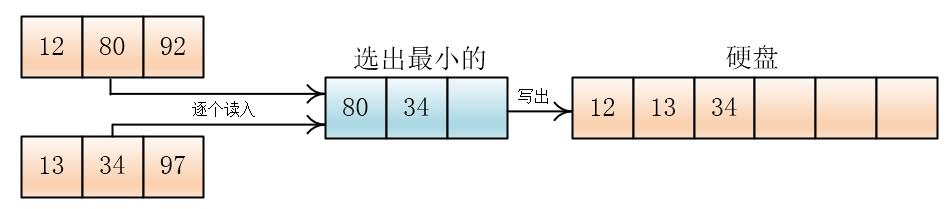
就这样,一直合并到两个顺串完,如果一个顺串先完,剩下另一个顺串,那么就将剩下的顺串直接拷贝到硬盘上
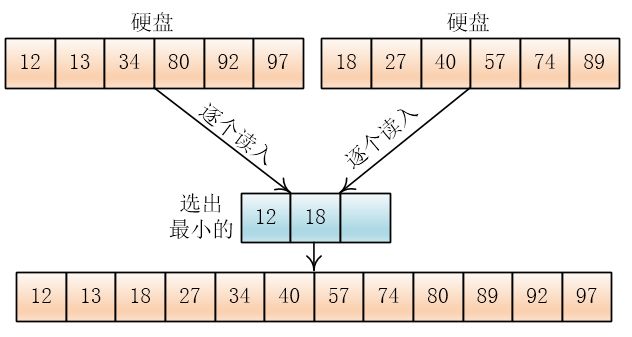
按照这个方法,把合并后的顺串继续合并,直到最终合并成一个总的顺串,排序结束
优化
我听说硬盘的读写速度比内存要慢的多,按照这种排序那岂不是很慢
一尘
慧能
好问题,一般我们会从两方面去优化
对同一个文件而言,采取这种排序方法所需读写外存(磁盘)的次数与归并趟数有关,很容易理解,归并趟数越多,内存和外存的交互次数就越多
假设初始时有 m 个顺串,每次对 k 个顺串进行归并,归并趟数就为:

比如我们的例子,刚开始的时候顺串(初始顺串)有 4 个(m=4),每次对 2 个顺串进行归并(k=2),那么归并趟数就为:
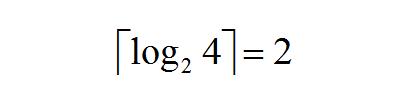
到此,我们优化的目标就很明确了:
① 增加归并的顺串数量 k
② 减少初始顺串的个数 m

多路归并

之前是两两一合并,使得归并顺串的数量为 2(这叫2路归并), 我们可以多归并几个,这样我们就可以减少归并的趟数了,从而减少外存的读写次数
以刚才的例子来看,这次我们假设内存大小可以容纳四个元素,我们一次对4个顺串进行归并(4路归并)
这样只需要一次合并就可以了,外存读写次数为24(12读+12写),比之前的48少了一半,于此同时我们也可以看到需要更大的内存了,内存之中选出最大值也会更耗时,所以要权衡选 k
在内存之中选最大(或最小)值时,可以选择一个元素与其他元素一个一个比,然后更新最值,但是效率会比较低,一般采取败者树来选择,在此就不展开说了,有兴趣的可以查阅相关资料
置换选择
对于顺串的构造,也就是第一次生成初顺串的时候,我们采取的办法是将划分好的每一份文件读入内存,排好序,然后输出到硬盘上形成初始顺串。
这样做的弊端就是你初始顺串的个数和你将文件划分好的份数是一样的
有没有一种生成更长的顺串,使得初始顺串的个数变的更少一些呢?答案是用置换选择排序
置换选择排序的大体思路就是读入一块数据到内存,将这些数据建立小根堆,然后输出最小值,再读入下一个元素
对堆排不了解的可看:
如果这个元素比刚才写出的元素大(或等于),那么就将其加入到最小堆中,重新调整堆,否则,则交换堆顶与堆底元素,然后将它放入堆底,暂不处理
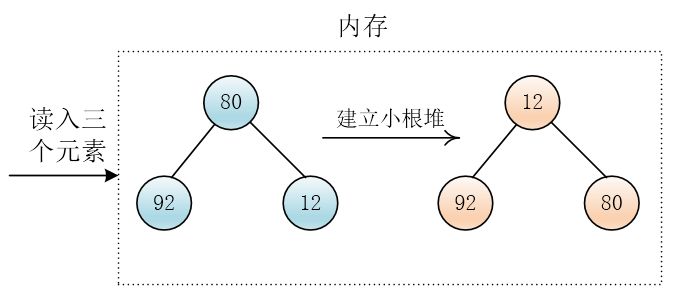
可能有点抽象,看一个例子,还是之前的数据

我们读入三个数据在内存中,然后建立一个小根堆
然后写出最小值
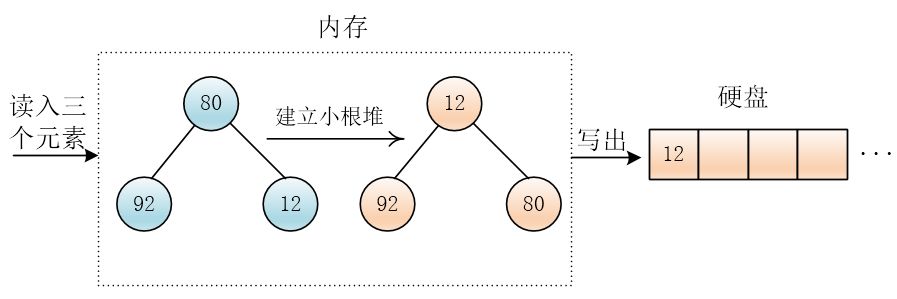
然后再读进来一个元素97,这个元素97大于刚输出的那个元素12,把 97 放到堆顶,调整堆,然后输出最小值80
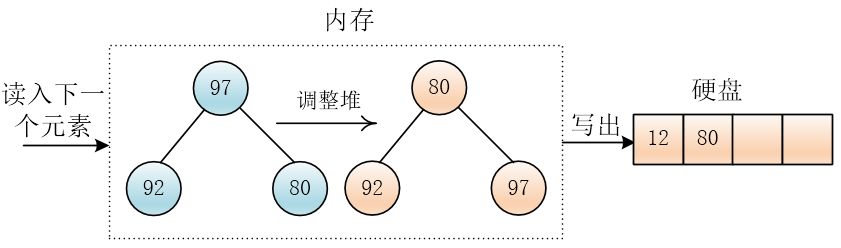
为什么这样做呢?因为如果读入的元素大于刚输出的元素,那么经过调整之后堆顶的元素也一定大于刚输出的元素(刚输出的是之前堆中最小的),这样的话输出的元素就按照有小到大的顺序排列,也就形成了一个顺串
继续读入13,此时13小于刚才输出的元素 80 ,则交换堆底元素97 和 堆顶元素 80,然后将13放入堆底(覆盖80),并且将 13 移出堆(堆大小减一)
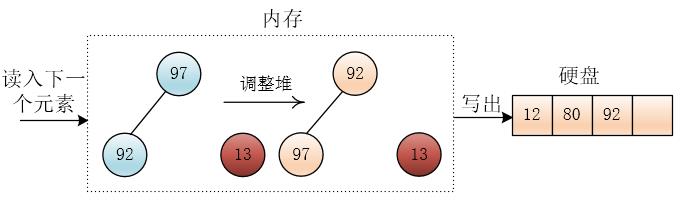
这个13则会进入下一个顺串的构造,这样做的目的也是保证输出的是一个顺串
如果13进入了小根堆,那么它小于刚输出的值(堆的最小值),则他一定是当前堆的最小值,那么就会输出它,而他比刚输出的值要小,破坏了顺串的规则
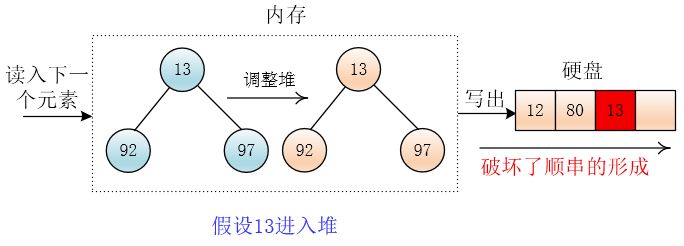
然后读入元素 34
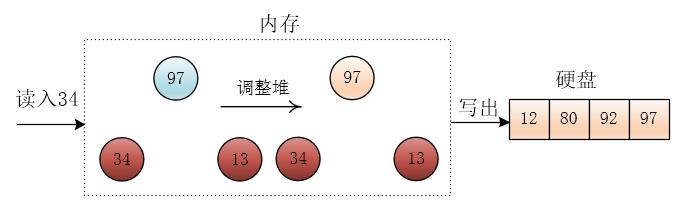
读入元素18,仍然小于刚输出的97,此时堆顶与堆底重叠,将18放入堆底(堆顶)
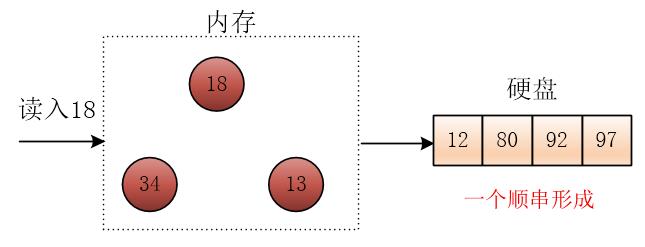
此时第一个顺串就形成了,然后将之前未进入堆的三个元素重新建立成小根堆,然后按照同样的方法继续进行
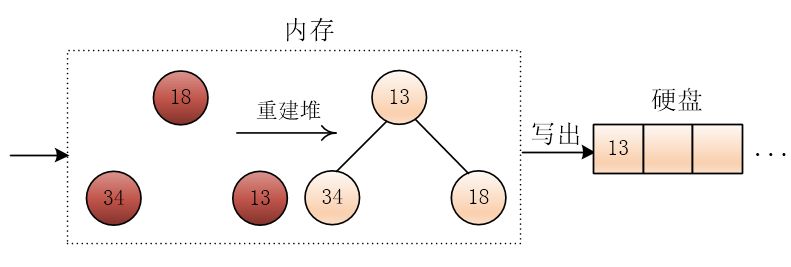
到最后,如果输入硬盘的数据读完了,只剩下一个小根堆,思路是一样的,一直选出最小值,输出
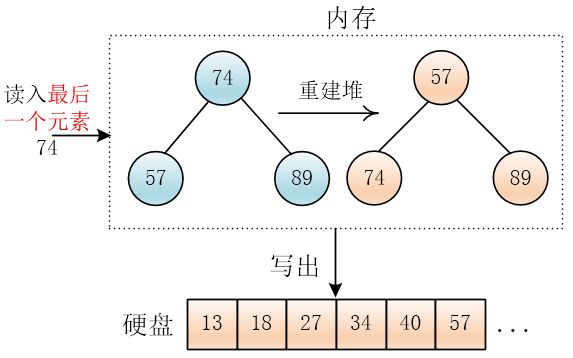
然后互换堆底与堆顶元素,再删除堆底元素,然后调整堆,输出最小值74
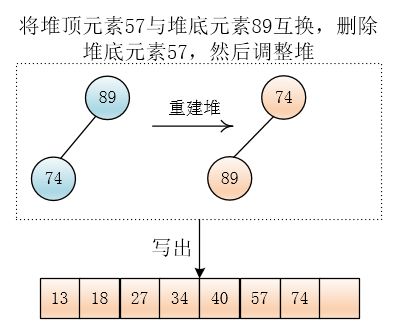
最后会生成另外一个顺串
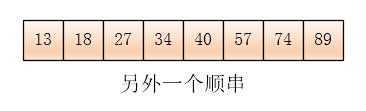
这样只生成了两个初始顺串,比之前划分成四份生成四个初始顺串少了些,这样归并趟数也就少了
那么这样做一定顺串长度一定会增大吗?
有一个定理:假定内存可以容纳 n 个元素,如果输入数据是随机分布的,那么替换选择排序可以产生平均长度为 2n 的顺串
至于为什么是 2n ,这里有一个扫雪机模型:
在一个下雪的日子,在一个圆形的跑道上有一个铲雪机在匀速地铲雪,下雪的速度也是匀速的,铲雪机的速度和下雪的速度刚好匹配,也就是说铲雪机从起始位置跑一圈后原来位置的雪的高度不变
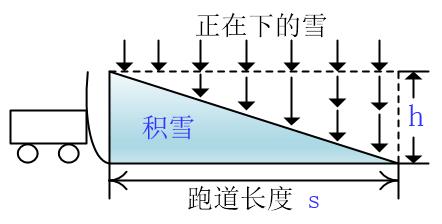
正如上图,跑了一圈后发现高度还是h,这时候就达到了一个动态平衡的状态,此时铲雪机前方的雪是一个斜坡
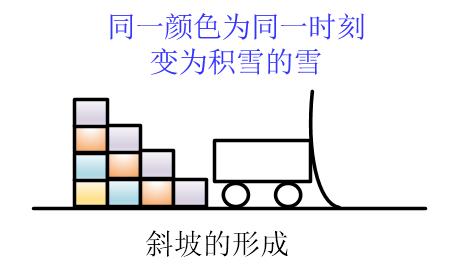
铲雪机不停地往前开,雪一直下,一部分落在了铲雪机上,一部分落在了铲雪机后面
此时铲雪机最前面的雪的高度一直都是h,因为前面有雪不断地落在斜坡上,所以铲雪机跑一圈铲的雪的总量为 s*h,很显然是原来路上积雪的两倍
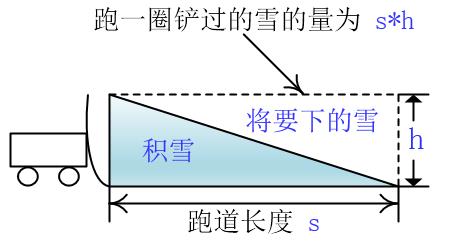
类比到我们的程序里,道路上的积雪就是我们内存中建的堆,需要我们输出最小值(清理),而不断下的雪就是新的输入,当输入随机的时候,大于等于刚输出值的元素被加入到堆中(落在铲车前被铲走),小于刚输出的元素被留下(落在铲车后面),产生的顺串的长度(铲的雪)就是内存中堆大小(道路上的积雪)的两倍了
哦,原来是这样做的,弟子不才,不能够触类旁通
一尘
师傅没有说话,只是看了看天空中的星星,随后说了句,今天说的它叫外部排序
推荐阅读:
专注服务器后台技术栈知识总结分享
欢迎关注交流共同进步
码农有道,为您提供通俗易懂的技术文章,让技术变的更简单!
以上是关于数据结构与算法外部排序的主要内容,如果未能解决你的问题,请参考以下文章