Node.js 源站应用稳定性保障
Posted 前端大全
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Node.js 源站应用稳定性保障相关的知识,希望对你有一定的参考价值。
来源:淘宝前端团队(FED)- 基德
网址:http://taobaofed.org/blog/2016/01/05/dragonfly-stability/
源站与 CDN
源站是 CDN 技术中的一部分,是发布内容的原始站点。CDN 负责承载流量的部分称做缓存服务器,而缓存服务器自身不生产内容,需要从源站获取原始内容。Dragonfly 作为淘宝内容管理系统(CMS)的源站,渲染并为缓存服务器提供了所有的页面内容。
Dragonfly 使用 Node.js 开发,稳定性保障是一边实践探索、一边总结经验。现在来回顾,稳定性保障涉及了 Dragonfly 完整的开发运维的生命周期。因此本文依次从设计、实现、验收、运维四个环节展开。
系统设计
从设计入手,我们分别梳理了 Dragonfly 在淘宝 CMS 生态圈的拓扑图和源站内部流程的草图。
源站的外部环境比较简单。前面对接 CDN,实现流量承载和核心页面的容灾,稳定性很高。后面主要对接 Redis 缓存,用于获取页面的各种资源。(图中的 配置中心 和 FileSync,分别用于获取配置和共享模板片段,为弱依赖)
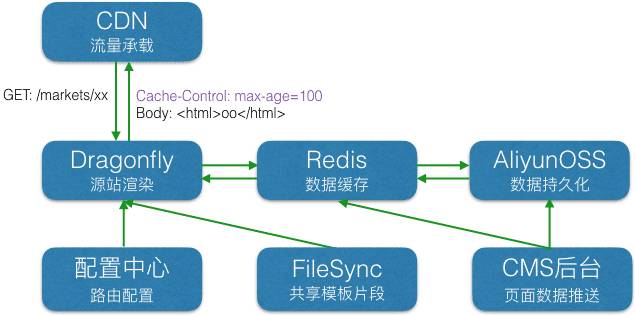
TMS 支持多终端页面的投放,因此 CDN 需要有识别终端的能力,Dragonfly 为此做了相关的处理。梳理前,源站的内部流程如下(Dragonfly 使用了 Koa.js,其中间件执行流程为回形针型——正序进,逆序出):
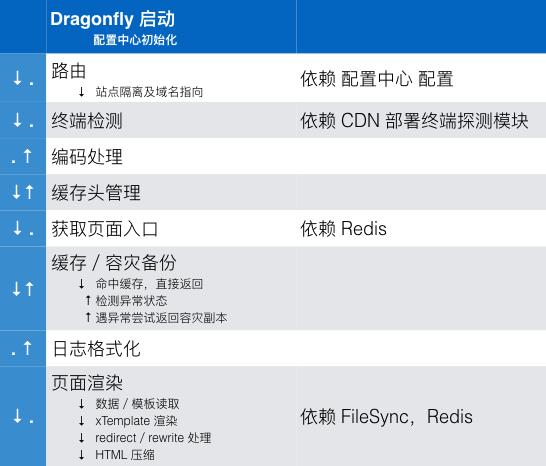
这里我们注意到:
没有输入过滤模块,为保证环境一致,用户 Query 需要统一丢掉。
获取页面入口模块依赖 Redis 这样欠稳定的系统,但是并没有纳入容灾备份的流程。
没有统一的异常处理模块,容灾模块只作异常检测,并为妥善处理异常。
为此我们先在设计上进行了如下调整:
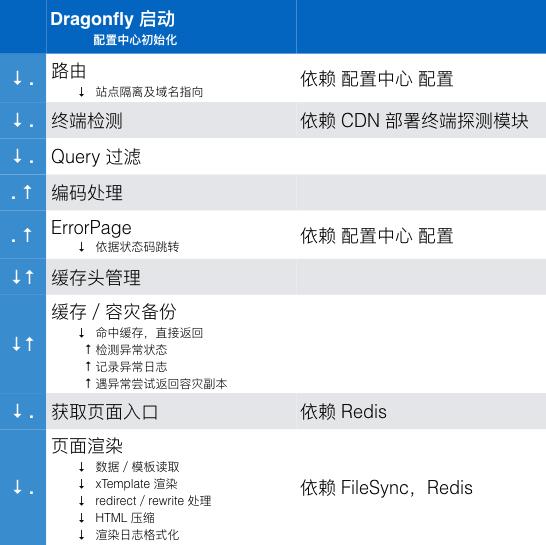
依据新的设计,我们确认了依赖不稳定系统的模块都能容灾模块覆盖。同时根据这张草图,我么确认了需要在实现、运维环节检查的内容:
确认外部依赖系统都有容错策略。
确认内部错误抛出都做了正确的日志记录,依据自身场景作恰当的容灾或其它异常处理。
确认监控脚本被正确的配置。
系统实现
依据系统设计环节的评审成果,我们开始评审系统实现部分。
外部依赖容灾保障
基本原则:
关键链路依赖的外部系统越少越好,外部依赖一定要有详细的容灾策略和预案。
依赖也包括第三方模块,应该使用最新稳定版本。过期版本易出现 BUG 无人解决、集成困难、性能差等问题。
Dragonfly 外部依赖的具体保障:
CDN/源站
CDN,根据自身特点有大量节点,依赖专业运维团队的维护,部分节点异常不影响可用性。
源站异常,CDN 使用过期的副本。
终端探测
终端探测模块使用 UA 进行判断。遇到未知设备,可能出现判断错误,因此系统提供了强制切换参数。
配置中心
配置中心即 Dragonfly 使用的配置推送系统。设计上,配置中心从服务端至客户端有多级容灾。
另外 Dragonfly 还在源码中做了一份本地容灾。
FileSync
文件同步系统 FileSync 维护了 CMS/应用 共用的前端代码片段。
推送后存在本地,遇异常可本地容灾、手工更新。
Redis
Redis 性能不错,但受网络影响,Dragonfly 实际使用时超时较多。我们做了大量测试,发现主要原因为 Redis 传输小数据较多,因此确保 TCP 连接做了 Keep-Alive、关闭 Nagle 算法、关闭 Delay ACK 优化后,性能得到了很大改善。
Redis 是数据缓存,Dragonfly 读取数据以 Redis 为主,另外使用了 Aliyun OSS 作为备份数据源。在 Redis 异常、超时时使用 Aliyun OSS。
Redis、Aliyun OSS 皆异常时页面将无法更新,源站启用本地容灾。
内部容错保障
基本原则有:
规范异常格式、抛出方式,进行统一处理是容灾保障的基础。
关键系统资源遇到瓶颈,要有降级策略。
Dragonfly 的具体处理方式:
上下文异常处理
发生后需要做日志记录,使用静态副本容灾。
未捕获的异常
写日志触发报警,重启 Worker 进程。
实时备份
每个页面请求,每 10s 生成一次静态容灾副本写入硬盘。
内存监控
渲染过程中会产生大量缓存、临时字符串,给垃圾回收带来了很大压力。
内存占用过高,无法及时回收时,需要强制重启 Worker 进行回收。
更多优化方案持续进行。
过载降级
压力过高时,Dragonfly 会收到 nginx 提供的 Over-Load 头,此时直接返回静态副本。
静态开关
与开发团队交流学到的手动降级方案。用于应付未知 BUG 导致的大批页面异常。
测试(验收)
系统设计时也要一并思考如何测试。优秀的设计应该是易于测试的。
单元测试
充分的单元测试是持续重构的保障。Dragonfly 的单元测试细节本文就不展开了,这里给出笔者的一些总结:
单元测试不拖累开发效率,反而是持续高效开发的保障。
测试覆盖可以验证代码和测试质量,帮助我们找到潜在的缺陷。
单元测试设计要充分,从程序的基本单元入手,需求变更时必须及时更新。
单元测试应保持独立性,每项测试不依赖其它测试,产生可覆盖、一致的结果。这里 Mock 是项很有用的技术。
功能测试
单元测试保障了每个模块的质量。对于整个系统而言,功能测试是确定是否实现用户需求的有效方法。
功能测试的实现与单元测试大同小异。要特别说明的是,对于容灾模块,除了功能测试,我们还做了线上演练。
性能测试
持续集成
既然测试是质量的保障,我们应该把测试自动化。选择一个成熟的持续集成方案吧。
日志与监控(维护)
日志
日志是用于监控和排查问题的。应以监控和问题排查者的角度记录。做到统一格式,按模块分类记录,集中管理。笔者理解的日志分类为:
诊断日志
例如源站会按 config/redis/xtemplate 具体分类记录。
统计日志
例如源站的 QPS/RT 等访问日志统计。
审计日志
例如用户操作日志。
日志是需要定时维护的,这里依据 Dragonfly 的日志维护经验给出总结:
无用日志必须清理。
设计日志时思考如何方便故障排查者。
排查故障后,应反思日志是否合理,并及时完善日志。
给一台线上机器实现详细 Debug 日志的开关,用于复杂问题的排查。
监控
有日志无监控等于没做,部分监控经验:
监控信息要便于快速解决问题。
监控要依据运维经验调整合理,误报过多容易导致麻痹。
总结
千里之堤,溃于蚁穴。系统稳定性需要持续的点滴积累,疏忽任何一个细微环节都可能给系统带来巨大的风险。但是依赖合理的规划、严格的验收标准、持续完善的监控,稳定性保障并不困难。
【今日微信公号推荐↓】
以上是关于Node.js 源站应用稳定性保障的主要内容,如果未能解决你的问题,请参考以下文章