你需要了解的 Node.js 模块
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你需要了解的 Node.js 模块相关的知识,希望对你有一定的参考价值。
#点击图片报名参加武汉、长沙源创会#
OSC 协作翻译
原文:
Requiring modules in Node.js: Everything you need to know
链接:
https://medium.freecodecamp.com/requiring-modules-in-node-js-everything-you-need-to-know-e7fbd119be8#.vb4g1p532
翻译:Viyi, 边城, Tocy, BigEcho, snake_007, Tony, JKol
请输入标题 bcdef
Node 使用两个核心模块来管理模块依赖:
● require 模块,在全局范围可用——无需 require('require')。
● module 模块,在全局范围可用——无需 require('module')。
你可以将 require 模块视为命令,将 module 模块视为所有必需模块的组织者。
请输入标题 abcdefg
在 Node 中获取一个模块并不复杂。
const config = require('/path/to/file');
由 require 模块导出的主要对象是一个函数(如上例所用)。 当 Node 使用本地文件路径作为函数的唯一参数调用该 require() 函数时,Node 将执行以下步骤:
● 解析:找到文件的绝对路径。
● 加载:确定文件内容的类型.
● 封装:给文件其私有作用域。 这使得 require 和 module 对象两者都可以下载我们需要的每个文件。
● 评估:这是 VM 对加载的代码最后需要做的。
● 缓存:当我们再次需要这个文件时,不再重复所有的步骤。
在本文中,我将尝试用示例解释这些不同的阶段,以及它们是如何影响我们在 Node 中编写模块的方式的。
先在终端创建一个目录来保存所有示例:
mkdir ~/learn-node && cd ~/learn-node
本文之后所有命令都在 ~/learn-node 下运行。
解析本地路径
我现在向你介绍 module 对象。你可以在一个的 REPL(译者注:Read-Eval-Print-Loop,就是一般控制台干的事情)会话中很容易地看到它:
~/learn-node $ node
> module
Module {
id: '<repl>',
exports: {},
parent: undefined,
filename: null,
loaded: false,
children: [],
paths: [ ... ] }
每个模块对象都有一个 id 属性作为标识。这个 id 通常是文件的完整路径,不过在 REPL 会话中,它只是 <repl>。
Node 模块与文件系统有着一对一的关系。请求模块就是把文件内容加载到内存中。
不过,因为 Node 中有很多方法用于请求文件(比如,使用相对路径,或预定义的路径),在我们把文件内容加载到内存之前,我们需要找到文件的绝对位置。
现在请求 'find-me' 模块,但不指定路径:
require('find-me');
Node 会按顺序在 module.paths 指定的路径中去寻找 find-me.js。
~/learn-node $ node
> module.paths
[ '/Users/samer/learn-node/repl/node_modules',
'/Users/samer/learn-node/node_modules',
'/Users/samer/node_modules',
'/Users/node_modules',
'/node_modules',
'/Users/samer/.node_modules',
'/Users/samer/.node_libraries',
'/usr/local/Cellar/node/7.7.1/lib/node' ]
路径列表基本上会是从当前目录到根目录下的每一个 node_modules 目录。它也会包含一些不推荐使用的遗留目录。
如果 Node 在这些目录下仍然找不到 find-me.js,它会抛出 “cannot find module error.(不能找到模块)” 这个错误消息。
~/learn-node $ node
> require('find-me')
Error: Cannot find module 'find-me'
at Function.Module._resolveFilename (module.js:470:15)
at Function.Module._load (module.js:418:25)
at Module.require (module.js:498:17)
at require (internal/module.js:20:19)
at repl:1:1 at ContextifyScript.Script.runInThisContext (vm.js:23:33)
at REPLServer.defaultEval (repl.js:336:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:533:10)
现在创建一个局部的 node_modules 目录,放入一个 find-me.js,require('find-me') 就能找到它。
~/learn-node $ mkdir node_modules
~/learn-node $ echo "console.log('I am not lost');" > node_modules/find-me.js
~/learn-node $ node
> require('find-me');
I am not lost
{}
>
如果别的路径下存在另一个 find-me.js 文件,例如在 home 目录下存在 node_modules 目录,其中有一个不同的 find-me.js:
$ mkdir ~/node_modules
$ echo "console.log('I am the root of all problems');" > ~/node_modules/find-me.js
现在 learn-node 目录也包含 node_modules/find-me.js —— 在这个目录下 require('find-me'),那么 home 目录下的 find-me.js 根本不会被加载:
~/learn-node $ node
> require('find-me')
I am not lost
{}
>
如果删除了~/learn-node 目录下的的 node_modules 目录,再次尝试请求 find-me.js,就会使用 home 目录下 node_modules 目录中的 find-me.js 了:
~/learn-node $ rm -r node_modules/
~/learn-node $ node
> require('find-me')
I am the root of all problems
{}
>
请求一个目录
模块不一定是文件。我们也可以在 node_modules 目录下创建一个 find-me 目录,并在其中放一个 index.js 文件。同样的 require('find-me') 会使用这个目录下的 index.js 文件:
~/learn-node $ mkdir -p node_modules/find-me
~/learn-node $ echo "console.log('Found again.');" > node_modules/find-me/index.js
~/learn-node $ node
> require('find-me');
Found again.
{}
>
注意如果存在局部模块,home 下 node_modules 路径中的相应模块仍然会被忽略。
在请求一个目录的时候,默认会使用 index.js,不过我们可以通过 package.json 中的 main 选项来改变起始文件。比如,希望 require('find-me') 在 find-me 目录下去使用另一个文件,只需要在那个目录下添加 package.json 文件来完成这个事情:
~/learn-node $ echo "console.log('I rule');" > node_modules/find-me/start.js
~/learn-node $ echo '{ "name": "find-me-folder", "main": "start.js" }' > node_modules/find-me/package.json
~/learn-node $ node
> require('find-me');
I rule
{}
>
require.resolve
如果你只是想找到模块,并不想执行它,你可以使用 require.resolve 函数。除了不加载文件,它的行为与主函数 require 完全相同。如果文件不存在它会抛出错误,如果找到了指定的文件,它会返回完整路径。
> require.resolve('find-me');
'/Users/samer/learn-node/node_modules/find-me/start.js'
> require.resolve('not-there');
Error: Cannot find module 'not-there'
at Function.Module._resolveFilename (module.js:470:15)
at Function.resolve (internal/module.js:27:19)
at repl:1:9
at ContextifyScript.Script.runInThisContext (vm.js:23:33)
at REPLServer.defaultEval (repl.js:336:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:533:10)
at emitOne (events.js:101:20)
at REPLServer.emit (events.js:191:7)
>
这很有用,比如,检查一个可选的包是否安装并在它已安装的情况下使用它。
相对路径和绝对路径
除了在 node_modules 目录中查找模块之外,我们也可以把模块放置于任何位置,然后通过相对路径(./ 和 ../)请求,也可以通过以 / 开始的绝对路径请求。
比如,如果 find-me.js 是放在 lib 目录而不是 node_modules 目录下,可以这样请求:
require('./lib/find-me');
文件中的父子关系
创建 lib/util.js 文件并添加一行 console.log 代码来识别它。console.log 会输出模块自身的 module 对象:
~/learn-node $ mkdir lib
~/learn-node $ echo "console.log('In util', module);" > lib/util.js
在 index.js 文件中干同样的事情,稍后我们会通过 node 命令执行这个文件。让 index.js 文件请求 lib/util.js:
~/learn-node $ echo "console.log('In index', module); require('./lib/util');" > index.js
现在用 node 执行 index.js:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: false,
children: [],
paths: [ ... ] }
In util Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: {},
parent:
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: false,
children: [ [Circular] ],
paths: [...] },
filename: '/Users/samer/learn-node/lib/util.js',
loaded: false,
children: [],
paths: [...] }
注意到现在的列表中主模块 index (id: '.') 是 lib/util 模块的父模块。不过 lib/util 模块并未作为 index 的子模块列出来。不过那里有个 [Circular] 值因为那里存在循环引用。如果 Node 打印 lib/util 模块对象,它就会陷入一个无限循环。因此这里用 [Circular] 代替了 lib/util 引用。
现在更重要的问题是,如果 lib/util 模块又请求了 index 模块,会发生什么事情?这就是我们需要了解的循环依赖,Node 允许这种情况存在。
在理解它之前,我们先来搞明白 module 对象中的另外一些概念。
exports、module.exports 以及同步加载模块
exports 是每个模块都有的一个特殊对象。如果你观察仔细,会发现上面示例中每次打印的模块对象中都存在一个 exports 属性,到目前为止它只是个空对象。我们可以给这个特殊的 exports 对象任意添加属性。例如,我们为 index.js 和 lib/util.js 导出 id 属性:
// Add the following line at the top of lib/util.js
exports.id = 'lib/util';
// Add the following line at the top of index.js
exports.id = 'index';
现在执行 index.js,我们会看到这些属性受到 module 对象管理:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: { id: 'index' },
loaded: false,
... }
In util Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: { id: 'lib/util' },
parent:
Module {
id: '.',
exports: { id: 'index' },
loaded: false,
... },
loaded: false,
... }
上面的输出中我去掉了一些属性,这样看起来比较简洁,不过请注意 exports 对象已经包含了我们在每个模块中定义的属性。你可以在 exports 对象中任意添加属性,也可以直接把 exports 整个替换成另一个对象。比如,可以把 exports 对象变成一个函数,我们会这样做:
// Add the following line in index.js before the console.log
module.exports = function() {};
现在运行 index.js,你会看到 exports 对象是一个函数:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: [Function],
loaded: false,
... }
注意,我没有通过 exports = function() {} 来将 exports 对象改变为函数。这样做是不行的,因为模块中的 exports 变量只是 module.exports 的引用,它用于管理导出属性。如果我们重新给 exports 变量赋值,就会丢失对 module.exports 的引用,实际会产生一个新的变量,而不是改变了 module.exports。
每个模块中的 module.exports 对象就是通过 require 函数请求那个模块返回的。比如,把 index.js 中的 require('./lib/util') 改为:
const UTIL = require('./lib/util');
console.log('UTIL:', UTIL);
这段代码会输出 lib/util 导出到 UTIL 常量中的属性。现在运行 index.js,输出如下:
UTIL: { id: 'lib/util' }
再来谈谈每个模块的 loaded 属性。到目前为止,每次我们打印一个模块对象的时候,都会看到这个对象的 loaded 属性值为 false。
module 模块使用 loaded 属性来跟踪哪些模块是加载过的(true值),以及哪些模块还在加载中(false 值)。比如我们可以通过调用 setImmediate 来打印 modules 对象,在下一事件循环中看看完成加载的 index.js 模块:
// In index.js
setImmediate(() => {
console.log('The index.js module object is now loaded!', module)
});
输出是这样的:
The index.js module object is now loaded! Module {
id: '.',
exports: [Function],
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: true,
children:
[ Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: [Object],
parent: [Circular],
filename: '/Users/samer/learn-node/lib/util.js',
loaded: true,
children: [],
paths: [Object] } ],
paths:
[ '/Users/samer/learn-node/node_modules',
'/Users/samer/node_modules',
'/Users/node_modules',
'/node_modules' ] }
注意理解它是如何推迟 console.log,使其在 lib/util.js 和 index.js 加载完成之后再产生输出的。
Node 完成加载模块(并标记)之后 exports 对象就完成了。整个请求/加载某个模块的过程是同步的。因此我们可以在一个事件循环周期过后看到模块已经完成加载。
这也就是说,我们不能异步改变 exports 对象。比如在某个模块中干这样的事情:
fs.readFile('/etc/passwd', (err, data) => {
if (err) throw err;
exports.data = data; // Will not work.
});
循环依赖模块
现在来回答关于 Node 循环依赖模块这个重要的问题:如果模块1需要模块2,模块2也需要模块1,会发生什么事情?
为了观察结果,我们在 lib/ 下创建两个文件,module1.js 和 module2.js,它们相互请求对象:
// lib/module1.js
exports.a = 1;
require('./module2');
exports.b = 2;
exports.c = 3;
// lib/module2.js
const Module1 = require('./module1');
console.log('Module1 is partially loaded here', Module1);
运行 module1.js 可以看到:
~/learn-node $ node lib/module1.js
Module1 is partially loaded here { a: 1 }
我们在 module1 完全加载前请求了 module2,而 module2 在未完全加载时又请求了 module1,那么,在那一时刻,能得到的是在循环依赖之前导出的属性。只有 a 属性打印出来了,因为 b 和 c 是在请求了module2 并打印了 module1 之后才导出的。
Node 让这件事变得简单。在加载某个模块的时候,它会创建 exports 对象。你可以在一个模块加载完成之前请求它,但只会得到部分导出的对象,它只包含到目前为止已经定义的项。
JSON 和 C/C++ addon
我们可以利用 require 函数在本地引入 JSON 文件和 C++ addon 文件。这么做不需要指定文件扩展名。
如果没有指定文件扩展名,Node 首先要处理 .js 文件。如果找不到 .js 文件,就会尝试寻找 .json 文件,如果发现为 JSON 文本文件,便将其解析为 .json 文件。 之后,它将尝试找到一个二进制 .node 文件。为了消除歧义,当需要使用 .js 文件以外的其他格式后缀时,你需要制定一个文件扩展名。
引入 JSON 文件在某些情况下是很有用的,例如,当你在该文件中需要管理的所有内容都是些静态配置值时,或者你需要定期从某个外部源读入值时。假设我们有以下 config.json 文件:
{
"host": "localhost",
"port": 8080
}
我们可以像这样直接请求:
const { host, port } = require('./config');
console.log(`Server will run at http://${host}:${port}`);
运行上面的代码,输出如下:
Server will run at http://localhost:8080
如果 Node 不能找到 .js 或 .json 文件,它会寻找 .node 文件,它会被认为是编译好的插件模块。
Node 文档中有一个插件文件示例,它是用 C++ 写的。它只是一个导出了 hello() 函数的简单模块,这个 hello 函数输出 "world"。
你可以使用 node-gyp 包来编译和构建 .cc 文件,生成 .addon 文件。只需要配置一个 binding.gyp 文件来告诉 node-gyp 做什么。
得到 addon.node (或其它在 binding.gyp 中指定的名称)文件后,你可以像请求其它模块一样请求它:
const addon = require('./addon');
console.log(addon.hello());
们可以在 require.extensions 中看到实际支持的三个扩展名:
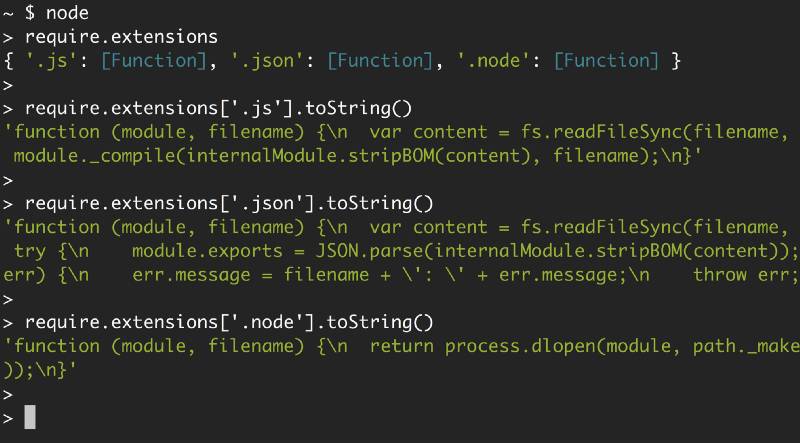
看看每个扩展名对应的函数,你就清楚 Node 在怎么使用它们。它使用 module._compile 处理 .js 文件,使用 JSON.parse 处理 .json 文件,以及使用 process.dlopen 处理 .node 文件。
在 Node 编写的所有代码将封装到函数中
有人经常误解 Node 的封装模块的用途。让我们通过 exports/module.exports 之间的关系来了解它。
我们可以使用 exports 对象导出属性,但是我们不能直接替换 exports 对象,因为它仅是对 module.exports 的引用
exports.id = 42; // This is ok.
exports = { id: 42 }; // This will not work.
module.exports = { id: 42 }; // This is ok.
对于每个模块而言这个 exports 对象看似是全局的,这和将其定义为 module 对象的引用,那到底什么是 exports 对象呢?
在解释 Node 的封装过程之前,让我再问一个问题。
在浏览器中,当我们在脚本中如下所示地声明一个变量:
var answer = 42;
在定义 answer 变量的脚本之后,该变量将在所有脚本中全局可见。
这在 Node 中根本不是问题。我们在某个模块中定义的变量,其它模块是访问不到的。那么为什么 Node 中变量的作用域这么神奇?
答案很简单。在编译模块之前,Node 会把模块代码封装在一个函数中,我们可以通过 module 模块的 wrapper 属性看出来。
~ $ node
> require('module').wrapper
[ '(function (exports, require, module, __filename, __dirname) { ',
'\n});' ]
>
Node 不会直接执行你写在文件中的代码。它执行这个包装函数,你写的代码只是它的函数体。因此所有定义在模块中的顶层变量都受限于模块的作用域。
这个包装函数有5个参数:exports, require, module, __filename 和 __dirname。它们看起来像是全局的,但实际它们在每个模块内部。
所有这些参数都会在 Node 执行包装函数的时候获得值。exports 是 module.exports 的引用。require 和 module 都有特定的功能。
__filename/__dirname 变量包含了模块文件名及其所有目录的绝对路径。
如果你的脚本在第一行出现错误,你就会看到它是如何包装的:
~/learn-node $ echo "euaohseu" > bad.js
~/learn-node $ node bad.js
~/bad.js:1
(function (exports, require, module, __filename, __dirname) {
euaohseu
^
ReferenceError: euaohseu is not defined
注意上例中的第一行并非是真的错误引用,而是为了在错误报告中输出包装函数。
此外,既然每个模块都封装在函数中,我们可以通过 arguments 关键字来使用函数的参数:
~/learn-node $ echo "console.log(arguments)" > index.js
~/learn-node $ node index.js
{ '0': {},
'1':
{ [Function: require]
resolve: [Function: resolve],
main:
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/index.js',
loaded: false,
children: [],
paths: [Object] },
extensions: { ... },
cache: { '/Users/samer/index.js': [Object] } },
'2':
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/index.js',
loaded: false,
children: [],
paths: [ ... ] },
'3': '/Users/samer/index.js',
'4': '/Users/samer' }
第一个参数是 exports 对象,它一开始是空的。然后是 require/module 对象,它们与在执行的 index.js 文件的实例关联,并非全局变量。最后 2 个参数是文件的路径及其所在目录的路径。
包装函数的返回值是 module.exports。在包装函数的内部我们可以通过改变 module.exports 属性来改变 exports 对象,但不能直接对 exports 赋值,因为它只是一个引用。
这个事情大致像这样:
function (require, module, __filename, __dirname) {
let exports = module.exports; // Your Code...
return module.exports;
}
如果我们直接改变 exports 对象,它就不再是 module.exports 的引用。javascript 在任何地方都是这样引用对象,并非只是在这个环境中。
require 对象
require 没什么特别,它主要是作为一个函数来使用,接受模块名称或路径作为参数,返回 module.exports 对象。如果我们想改变 require 对象的逻辑,也很容易。
比如,为了进行测试,我们想让每个 require 调用都被模拟为返回一个假对象来代替模块导出的对象。这个简单的调整就像这样:
require = function() {
return { mocked: true };
}
在上面重新对 require 赋值之后,调用 require('something') 就会返回模拟的对象。
require 对象也有自己的属性。我们已经看到了 resolve 属性,它也是一个函数,是 require 处理过程中解析路径的步骤。上面我们还看到了 require.extensions。
还有一个 require.main 可用于检查代码是通过请求来运行的还是直接运行的。
再来看个例子,定义在 print-in-frame.js 中的 printInFrame 函数:
// In print-in-frame.js
const printInFrame = (size, header) => {
console.log('*'.repeat(size));
console.log(header);
console.log('*'.repeat(size));
};
这个函数需要一个数值型的参数 size 和一个字符串型的参数 header,它会在打印一个由指定数量的星号生成的框架,并在其中打印 header。
我们希望通过两种方式来使用这个文件:
从命令行直接运行:
/learn-node $ node print-in-frame 8 Hello
在命令行传入 8 和 Hello 作为参数,它会打印出由 8 个星号组成的框架中的 "Hello"。
通过 require 来使用。假设所需要的模块会导出 printInFrame 函数,然后就可以这样做:
const print = require('./print-in-frame');
print(5, 'Hey');
它在由 5 个星号组成的框架中打印 "Hey"。
这是两种不同的使用方式。我们得想办法检测文件是独立运行的还是由其它脚本请求的。
这里用一个简单的 if 语句来解决:
if (require.main === module) {
// The file is being executed directly (not with require)
}
我们可以使用这个条件,以不同的方式调用 printInFrame 来满足需求:
// In print-in-frame.js
const printInFrame = (size, header) => {
console.log('*'.repeat(size));
console.log(header);
console.log('*'.repeat(size));
};
if (require.main === module) {
printInFrame(process.argv[2], process.argv[3]);
} else {
module.exports = printInFrame;
}
如果文件不是被请求的,我们使用 process.argv 来调用 printInFrame。否则,我们将 module.exports 修改为 printInFrame 引用。
所有模块都会被缓存
理解缓存很重要。我们用一个简单的示例来说明缓存。
假设有一个 ascii-art.js,可以打印炫酷的标头:

我们想每次请求这个文件的时候都能看到这些标头,那么如果我们请求这个文件两次,期望会看到两次标头输出。
require('./ascii-art') // 会显示标头。
require('./ascii-art') // 不会显示标头。
因为模块缓存,第二次请求不会显示标头。Node 会在第一次调用的时候缓存文件,所以第二次调用的时候就不会重新加载了。
我们可以在第一次请求之后通过打印 require.cache 来看缓存的内容。缓存注册表只是一个简单的对象,它的每个属性对应着每次请求的模块。那些属性值是每个模块中的 module 对象。只需要从 require.cache 里删除某个属性就可以使对应的缓存失效。如果这样做,Node 会再次加载模块并再加将它加入缓存。
不过在现在这个情况下,这样做并不是一个高效的解决办法。简单的办法是在 ascii-art.js 中把输出语句包装为一个函数,然后导出它。用这个办法,我们请求 ascii-art.js 文件的时候会得到一个函数,然后每次执行这个函数都可以看到输出:
require('./ascii-art')() // 会显示标头。
require('./ascii-art')() // 也会显示标头。

以上是关于你需要了解的 Node.js 模块的主要内容,如果未能解决你的问题,请参考以下文章
❤️一个聊天室案例带你了解Node.js+ws模块是如何实现websocket通信的
❤️一个聊天室案例带你了解Node.js+ws模块是如何实现websocket通信的!