《Node.js设计模式(第2版)》试读 & 送书活动
Posted 前端外刊评论
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Node.js设计模式(第2版)》试读 & 送书活动相关的知识,希望对你有一定的参考价值。
发点小福利,外刊君给大家带来《Node.js设计模式(第2版)》部分章节的试读。如果大家觉得不错,欢迎参加文末的活动,获得本书的纸质版!
第5章 流编程
流是Node.js最重要的组成和设计模式之一。社区流行这样一句格言“stream all the things!”,这就足以描述流在Node.js中扮演的重要角色。Dominic Tarr是一位著名的Node.js社区贡献者,他形容流是Node.js中最棒的想法,同时也是最容易让人产生误解的部分。有许多不同的原因使得Node.js中的流如此有吸引力,不仅因为在技术上表现出的良好性能和高效率,更多的是在于它的优雅,以及能完美融入Node.js的编程思想。
在本章中,你将学习以下这些内容:
为什么流在Node.js中如此重要
使用和创建流
流编程范式:展现流除了I/O操作以外在很多不同编程领域的优势
管道模式以及在不同使用场景中进行流的拼接
流的重要性
在例如Node.js这样以事件为基础的平台,处理I/O操作最高效的方法就是实时处理,尽快地接收处理输入内容,并经过程序的处理尽快地输出结果。
在这部分,我们将对Node.js的流以及流的功能进行一个最初始的介绍。请记住这只是一个概述,更多关于如何使用和组合流的分析将在本章后面部分被讲解到。
缓冲和流
到目前为止,你在本书中看到的几乎所有异步API都使用了缓冲模式。比如要完成一个输入操作,使用buffer让所有的源数据被存放到缓存当中,当整个数据源读取完毕后,会将缓存中的数据立即传递给回调函数处理。下图生动地展示了这个处理过程:
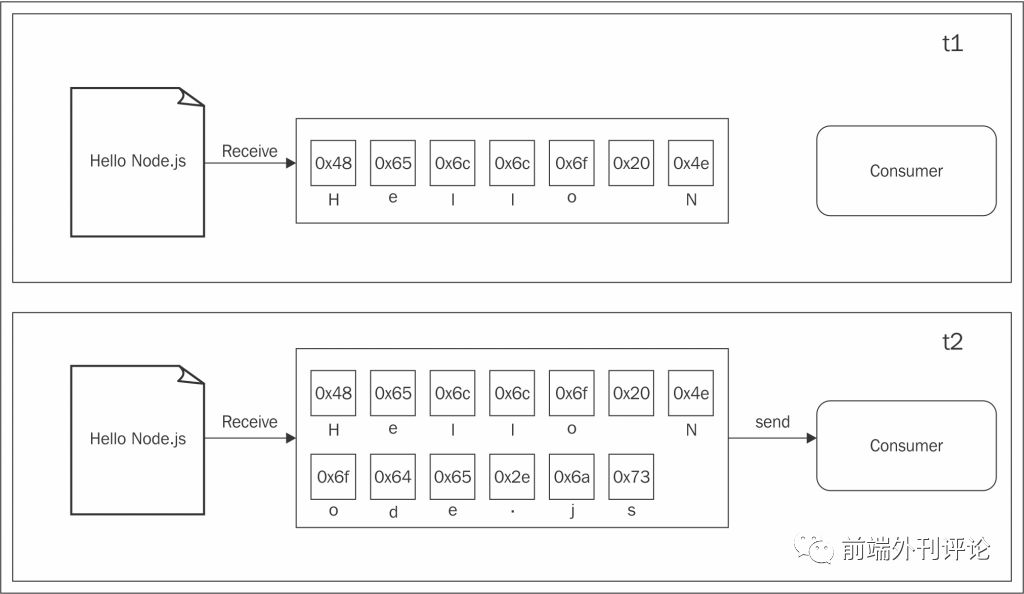
在上图中,我们可以看到在t1时刻,有些数据被读取到缓存中。在t2时刻,另一个数据块也就是最后一个数据块被接收到,完成了本次读取数据的过程并将整个缓存区的数据发送给处理程序。
不同的是,流允许你尽可能快地处理接收到的数据。下图很好地展示了这一过程:
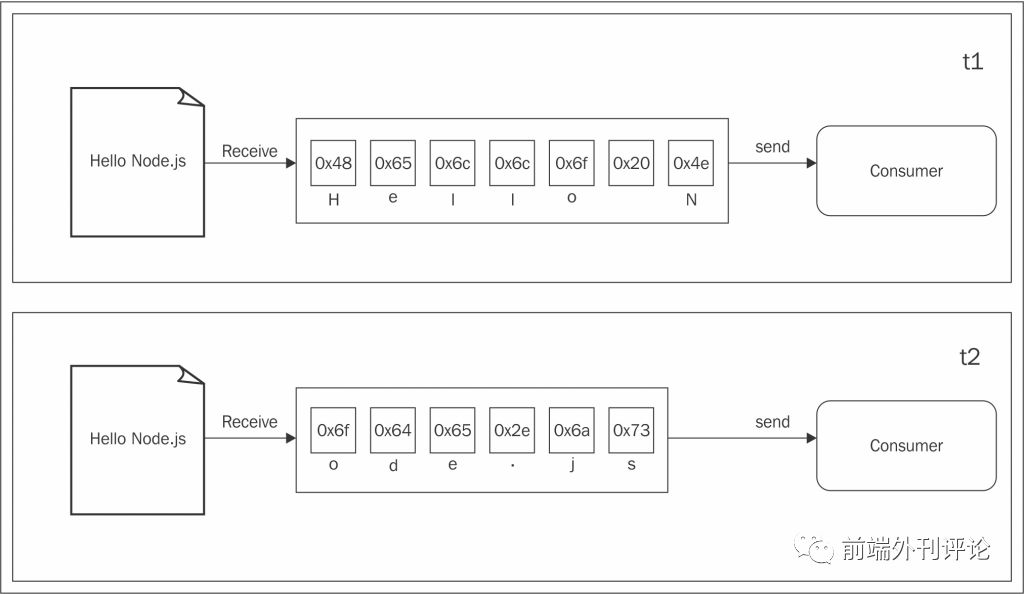
这一次,图表展示了如何从数据源读取每一个数据块,然后被立即提供给后续的处理流程,这时就可以立即处理读取到的数据而不需要等待所有的数据被先存放在缓存中。
但是这两种处理数据的方式到底有什么不一样?我们可以从两个主要的方面来总结:
空间效率
时间效率
除此之外,Node.js流有另外一个重要的优势:可组合性。现在让我们来看下这些属性是如何影响我们设计和编写程序的。
空间效率
首先,流可以帮助我们实现一些无法通过缓存数据并一次性处理来实现的功能。例如,考虑这样一种情况,我们需要读取一个很大的文件,比方说有几百M甚至几百G的大小。很明显,读取整个文件内容,然后从缓存中一次性返回的方式并不好。设想一下如果我们的程序同时读取很多这样的大文件,很容易导致内存溢出。除此之外,V8中的缓存区最大不能超过0x3FFFFFFF字节(略小于1G)。所以我们根本无法去完全耗尽物理内存。
通过缓存实现Gzip
来举个具体的例子,让我们考虑实现一个简单的命令行接口(CLI)应用程序,它使用Gzip格式来压缩一个文件。在Node.js中使用缓存API,程序代码会是这样的(为了代码简洁,省略了错误的处理):
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.readFile(file, (err, buffer) => {
zlib.gzip(buffer, (err, buffer) => {
fs.writeFile(file + '.gz', buffer, err => {
console.log('File successfully compressed');
});
});
});
现在,我们可以将上述代码保存到gzip.js文件中并使用以下命令来执行:
node gzip <path to file>
如果我们选择一个足够大的文件,比如大于1GB,我们会得到预想的错误,提示我们尝试读取的文件大小超过了缓存允许的最大值,比如下面的输出:
RangeError: File size is greater than possible Buffer:0x3FFFFFFF bytes
这正是我们能预想到的错误,说明我们使用了错误的方法。
通过流实现Gzip
修改我们的Gzip程序使其能够处理大文件的方法就是使用流。让我们来看下具体怎么实现,修改下我们刚刚创建的文件内容:
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(file + '.gz'))
.on('finish', () => console.log('File successfully compressed'));
你也许会问,就这么简单?是的,正如我们之前说的,流的神奇也在于它提供的接口和可组合性,能使代码更加整洁和优雅。接下来我们会了解更多的细节,但现在你需要知道的是,我们的程序可以顺利的处理任何大小的文件,同时内存的使用率能够保持恒定。你可以自己尝试一下(但同时你需要知道压缩一个大文件会耗费很长的时间)。
时间效率
现在让我们来考虑这样的情况,一个应用程序压缩一个文件并将其上传到远程的HTTP服务器,接着服务器会解压缩这个文件并将文件保存到文件系统中。如果你在客户端使用缓存的方式去实现,只有在整个文件被读取并压缩之后才会开始执行上传操作。也就是说,服务器端只有接受到所有的数据之后才能开始解压缩文件。使用流来实现这个功能应该是一个更好的方案。在客户端,一旦从文件系统读取到数据块,流允许你立即进行压缩和发送这些数据块,而同时,服务器上你也可以立即解压缩从远程收到的每个数据块。让我们创建一个这样的应用程序来具体说明,先从服务端开始吧。
让我们创建一个gzipReceive.js文件,代码如下:
const http = require('http');
const fs = require('fs');
const zlib = require('zlib');
const server = http.createServer((req, res) => {
const filename = req.headers.filename;
console.log('File request received: ' + filename);
req
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(filename))
.on('finish', () => {
res.writeHead(201, {'Content-Type': 'text/plain'});
res.end('That's it\n');
console.log(`File saved: ${filename}`);
});
server.listen(3000, () => console.log('Listening'));
使用Node.js的流,服务器能够迅速处理从网络上接受到的数据块,解压缩并且保存到文件。
创建一个gzipSend.js的文件作为我们应用程序的客户端模块,代码如下:
const fs = require('fs');
const zlib = require('zlib');
const http = require('http');
const path = require('path');
const file = process.argv[2];
const server = process.argv[3];
const options = {
hostname: server,
port: 3000,
path: '/',
method: 'PUT',
headers: {
filename: path.basename(file),
'Content-Type': 'application/octet-stream',
'Content-Encoding': 'gzip'
}
};
const req = http.request(options, res => {
console.log('Server response: ' + res.statusCode);
});
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(req)
.on('finish', () => {
console.log('File successfully sent');
});
在上面的代码中,我们再一次使用流来从文件系统读取文件内容,并立即压缩发送每一个数据块。
现在,可以试运行一下我们的应用,先使用以下命令启动服务端:
node gzipReceive
node gzipSend <path to file> localhost
如果选择的文件足够大,我们就能更容易明白数据是怎样从客户端传递到服务端,但是到底为什么使用流会比使用缓存来处理发送数据更加高效呢?下图会给我们一些启示:
文件处理会经过以下一系列的步骤:
[客户端]从文件系统读取数据
[客户端]对数据进行压缩
[客户端]发送到服务端
[服务端]接受客户端发送的数据
[服务端]解压缩接收到的数据
[服务端]将数据写入磁盘
为了完成整个处理过程,我们必须像流水线一样按顺序完成以上所有的步骤。如上图所示,使用缓存,整个过程是完全顺序执行的。首先必须等待整个文件被读取之后才能进行数据压缩,然后必须等待文件读取完毕以及数据压缩完成之后才可以向服务端发送数据。相反,如果我们使用流,当读取到第一个数据块的时候,整条流水线就开始运行起来,而不需要等到整个文件内容被读取到。但是更加惊奇的是,当下一个数据块到达的时候,不需要等待之前的任务完成,相反,另一条流水线并行启动。之所以能这样是由于每个任务都是异步执行的,在Node.js中可以并行来处理。唯一的限制就是数据块到达每个阶段的顺序必须被保存(这一点Node.js的流模块已经帮我们实现了)。
从上图中我们可以看到,使用流的方式,整个处理流程花费了更少的时间,因为我们不需要等待所有的数据被读取之后再一次性地进行处理。
组合性
我们前面看到的代码已经大概展示了如何将流组合起来使用,这要归功于pipe()这个方法,允许我们将不同的处理单元连接起来,而每一个处理单元只实现单一的功能,这一点很符合Node.js的编程风格。这之所以可行是因为流提供了统一的处理接口,从API层面来看流都是互通的。唯一的前提就是管道中的下一个流必须支持上一个流输出的数据类型,有可能是二进制流,文本甚至对象,这些在后面的章节中都会讲到。
通过另一个例子来看下这一属性的应用,我们尝试在致歉构建的gzipReceive/gzipSend应用中添加一个加密层。
为了说明这一点,我们只需要简单更新下客户端程序,在管道中增加一个流;具体来说,添加crypto.createChipher()对现有的流进行处理。最终代码是这样的:
const crypto = require('crypto');
// ...
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(crypto.createCipher('aes192', 'a_shared_secret'))
.pipe(req)
.on('finish', () => console.log('File succesfully sent'));
同样的方式,我们修改一下服务端程序使数据在解压缩之前先进行解密:
const crypto = require('crypto');
// ...
const server = http.createServer((req, res) => {
// ...
req
.pipe(crypto.createDecipher('aes192', 'a_shared_secret'))
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(filename))
.on('finish', () => { /* ... */ });
});
只要很少的修改(事实上只是几行代码),就在我们的应用程序中增加了一个加密层;我们简单地将一个已有的转换流到嵌入到已经搭建的流管道中。用类似的方式,我们可以像玩乐高积木一样随意地添加和组合其他流。
显然,这种方法的主要优点是可重用性,但同时,从这个例子可以看出,流能使得代码更加清晰和模块化。正因为如此,流不仅仅可以用来处理纯I/O问题,也可以用来对代码进行简化和模块化处理。
......
送书,送书!
在留言区留言,获得点赞最多的前三位童鞋每人一本,尤其是第一位童鞋将会获得本书的外刊君签名版!(点赞数据以本文发出后24小时整为准)
以上是关于《Node.js设计模式(第2版)》试读 & 送书活动的主要内容,如果未能解决你的问题,请参考以下文章
SAP UI5 应用 manifest.json 文件里 Routes 数组元素的相对顺序,不可忽视的试读版