Node.js第二天
Posted 摇摆哥哥 前端
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Node.js第二天相关的知识,希望对你有一定的参考价值。
一、路由。
路由就是解析前台传到后台的get或者post请求,并且解析所携带的参数。。
主要运用两个模块 url querytring 都是 node内置模块。。
二、运用server router index 做一个小例子
解释说明:
index.js 为入口文件
因为采用模块化开发 ,所以把 server 模块和 router模块封装起来 用exports暴露出去 用require引回来。
三、接收 get post 参数。。。
get var params = url.parse(req.url, true).query; 打印那些对象
post post方式 需要用到表单 或者 $.post
var body = "";
req.on('data', function (chunk) {
body += chunk;
});
body = querystring.parse(body);
四、Stream
1.
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出)。
Node.js,Stream 有四种流类型:
Readable - 可读操作。
Writable - 可写操作。
Duplex - 可读可写操作.
Transform - 操作被写入数据,然后读出结果。
所有的 Stream 对象都是 EventEmitter 的实例。常用的事件有:
data - 当有数据可读时触发。
end - 没有更多的数据可读时触发。
error - 在接收和写入过程中发生错误时触发。
finish - 所有数据已被写入到底层系统时触发。
2.从流中读取数据。
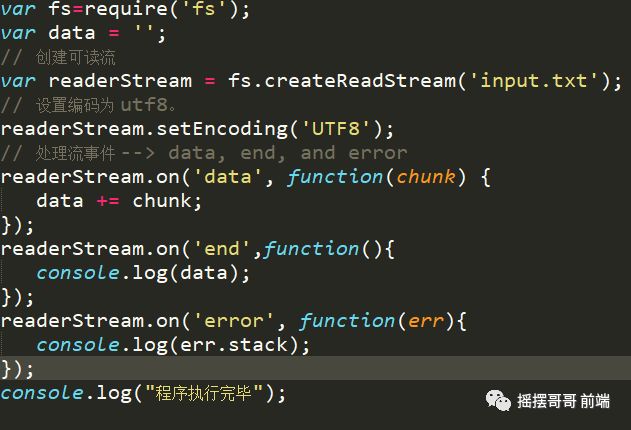

3.写入流 就是将文本写入文件
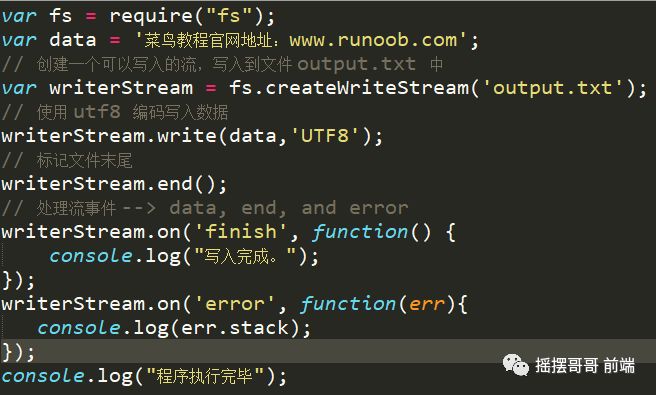
4.
管道流
管道提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。
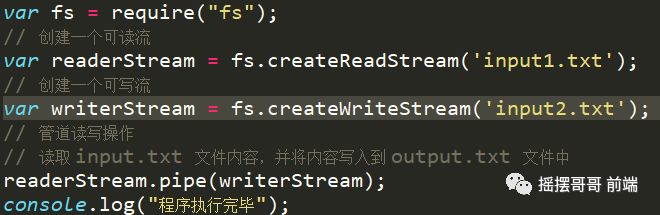
5.
链式流
链式是通过连接输出流到另外一个流并创建多个流操作链的机制。链式流一般用于管道操作。
接下来我们就是用管道和链式来压缩和解压文件。
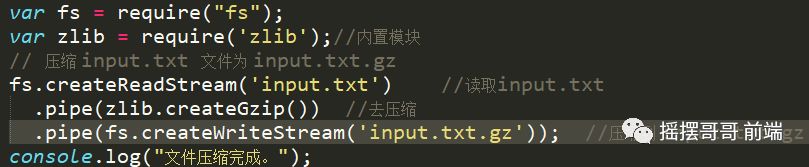
五、Buffer
javascript 语言自身只有字符串数据类型,没有二进制数据类型。
但在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。
Buffer 与字符编码
ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
ucs2 - utf16le 的别名。
base64 - Base64 编码。
latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式。
binary - latin1 的别名。
hex - 将每个字节编码为两个十六进制字符。
2.创建 Buffer 类
Buffer.alloc(size[, fill[, encoding]]): 返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满 0
Buffer.allocUnsafe(size): 返回一个指定大小的 Buffer 实例,但是它不会被初始化,所以它可能包含敏感的数据
Buffer.allocUnsafeSlow(size)
Buffer.from(array): 返回一个被 array 的值初始化的新的 Buffer 实例(传入的 array 的元素只能是数字,不然就会自动被 0 覆盖)
Buffer.from(arrayBuffer[, byteOffset[, length]]): 返回一个新建的与给定的 ArrayBuffer 共享同一内存的 Buffer。
Buffer.from(buffer): 复制传入的 Buffer 实例的数据,并返回一个新的 Buffer 实例
Buffer.from(string[, encoding]): 返回一个被 string 的值初始化的新的 Buffer 实例
3.
写入缓冲区
buf.write(string[, offset[, length]][, encoding])
string - 写入缓冲区的字符串。
offset - 缓冲区开始写入的索引值,默认为 0 。
length - 写入的字节数,默认为 buffer.length
encoding - 使用的编码。默认为 'utf8' 。
返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
4.
从缓冲区读取数据
buf.toString([encoding[, start[, end]]])
encoding - 使用的编码。默认为 'utf8' 。
start - 指定开始读取的索引位置,默认为 0。
end - 结束位置,默认为缓冲区的末尾。
解码缓冲区数据并使用指定的编码返回字符串。
5.将 Buffer 转换为 JSON 对象
buf.toJSON()
返回 JSON 对象。
6.缓冲区合并
Buffer.concat(list[, totalLength])
list - 用于合并的 Buffer 对象数组列表。
totalLength - 指定合并后Buffer对象的总长度。
7.缓冲区比较
buf.compare(otherBuffer);
otherBuffer - 与 buf 对象比较的另外一个 Buffer 对象。
8.拷贝缓冲区
buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])
targetBuffer - 要拷贝的 Buffer 对象。
targetStart - 数字, 可选, 默认: 0
sourceStart - 数字, 可选, 默认: 0
sourceEnd - 数字, 可选, 默认: buffer.length
没有返回值。
9.缓冲区裁剪
start - 数字, 可选, 默认: 0
end - 数字, 可选, 默认: buffer.length
返回一个新的缓冲区,它和旧缓冲区指向同一块内存,但是从索引 start 到 end 的位置剪切。
10.缓冲区长度
buf.length
以上是关于Node.js第二天的主要内容,如果未能解决你的问题,请参考以下文章