阿里云的 Node.js 稳定性实践
Posted 程序员成长指北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云的 Node.js 稳定性实践相关的知识,希望对你有一定的参考价值。
整理人:前端自习课
前言
如果你看过 2018 Node.js 的用户报告,你会发现 Node.js 的使用有了进一步的增长,同时也出现了一些新的趋势。

Node.js 的开发者更多的开始使用容器并积极的拥抱 Serverless
Node.js 越来越多的开始服务于企业开发
半数以上的 Node.js 应用都使用远端服务
前端开发者们开始越来越多的关心和参与到后端和全栈中去
可以看到越来越多的前端开发者们具备了全栈的能力,更多的核心应用开始基于 Node.js 开发,而其中,保障应用的稳定性是每一个开发者的“头等大事”。
稳定性是什么?一般来说,指的是应用持续提供可用服务的能力,一旦应用频繁不可用或出现故障无法及时恢复,对用户的使用体验都是巨大的伤害,甚至会造成很多更严重的后果。稳定性保障不仅仅是开发阶段的事情,它应该是贯穿应用的开发、测试、上线、监控等,覆盖整个 DevOps 生命周期的事情。
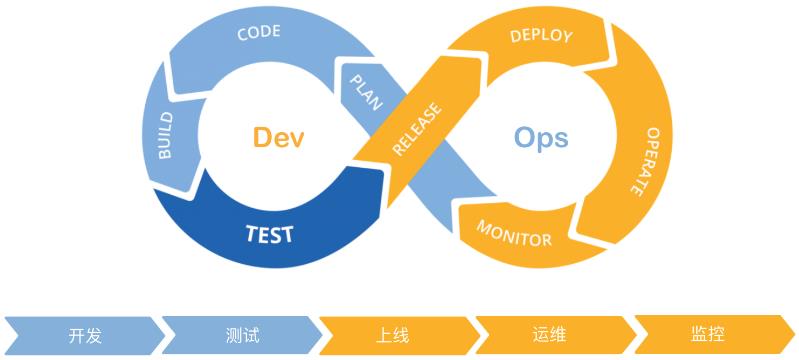
本身阿里云提供了丰富的产品和服务来支持整个 DevOps。
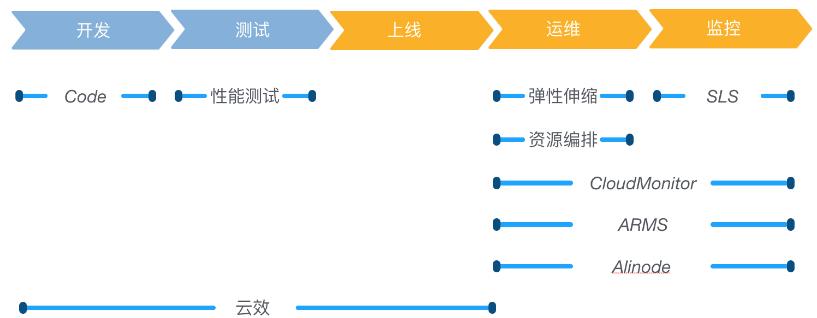
包括 Code 代码托管、PTS 性能测试、SLS 日志服务、云效 等等。
本文也将围绕整个 DevOps 生命周期,来介绍基于阿里云的 Node.js 稳定性保障的实践。
应用开发
稳定性的保障从应用开发阶段就已经开始了,这部分也是相关资料文章最多的,相信有追求的开发者都会关注并且已经应用和实践。
异常捕获和处理
应用运行过程中难免会有异常发生,再大神的程序员也不敢保证自己写的代码不出问题。其实出现异常不可怕,可怕的是异常没有捕获,进而引起应用进程 crash,导致应用不可用。
正常来说,捕获异常有一下几种方式:
try/catch
try/catch 是捕获异常的常用方式,可以帮助我们可控的捕获错误,但是 try/catch 无法捕获异步异常。
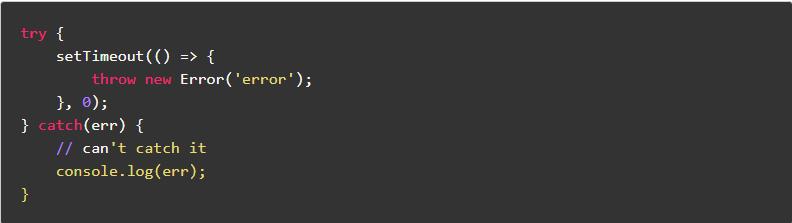
上面的异步异常使用 try/catch 是无法捕获的。捕获异步日常我们可以使用一下的方式。
异步异常




uncaughtException
当异常抛出未被捕获时,会触发 uncaughtException 事件。只要监听了 uncaughtException 事件并设置了回调,Node 进程就不会异常退出。

但是这时异常的上下文会丢失(respond 对象),无法给用户友好的返回。而且由于uncaughtException 事件发生后,会丢失当前环境的堆栈,可能导致 Node 不能正常进行内存回收,从而导致内存泄露。因此,使用 uncaughtException 的正确做法一般是,当 uncaughtException 发生时,记录详细的日志,然后结束进程,通过日志和报警来及时的定位和排查问题。
domain
为了弥补 try/catch、uncaughtException 的不足,Node 新增了一个 domain 模块,可以捕获异步异常并且不会丢失上下文。
听起来很完美,但是该模块目前是不稳定的(Stability: 0 - Deprecated)。同时其可能存在稳定性和内存泄露的问题,因此要谨慎使用。
虽然框架帮我们进行的兜底,但是依然需要我们针对自己的应用逻辑进行异常处理,给用户友好的异常提示。一般出现异常时,我们需要尽可能保证:
对出现异常的用户,进行友好的提示
不影响应用其他用户的正常使用
不影响应用进程的正常运行
详细的异常日志记录和报警机制,方便快速定位、解决问题
如果你使用的是 Egg,你可以使用 onerror 插件来做统一的处理。同时不建议将异常信息直接返回给用户,返回用户的应该是更语义化更友好的信息,而原始的错误堆栈和信息等,你可以通过日志进行记录,日志信息越详细越好,比如除了最基本的 name、message、stack 外,你还可以记录当前一些关键的参数以及当前调用链路的 traceId 等,这样的目的只有一个,就是可以快速定位到错误,以及错误发生的上下文。具体的链路监控下文会讲到。
强弱依赖
在设计应用架构时,重要的一步就是区分强弱依赖。强弱依赖的定义应该视对业务的影响程度而定,并不能单纯的认为会导致系统挂掉的依赖才是强依赖。尽量减少强依赖,因为强依赖意味着,一旦该强依赖出现问题,会导直接影响业务的进行。一个应用的依赖可能涉及到以下几个部分。
数据
应用的开发基本离不开数据的读写,这也导致我们的应用基本都是强依赖 DB 的,DB 一旦出现问题,那我们的应用可能就不可用了,因此我们可以通过 DB 上加一层缓存来增加一层保险,当数据更新的时候刷新对应的缓存,这样任何一层出现问题,都不会对应用带来灾难性后果。这里你需要额外注意数据同步的机制和一致性的保证,同时对于数据读取要设置合理的超时时间,比如读取缓存,如果 10ms 内没有响应就直接读取数据库,再有就是异常的处理,比如要保证读取缓存时出现异常不能影响 DB 的正常读取。
中间件
如果依赖了其他的中间件,也要考虑是否对某个中间件进行了强依赖,如果这个中间件故障了,会不会对我们的应用造成严重故障。
二方/三方系统
我们的应用或多或少都会依赖其他的二方或者三方系统,对我们依赖的这些系统的稳定性,我们尽量要做到心中有数,尽量不进行强依赖,如果出现异常,要做好详细的日志记录,快速定位出现问题的依赖方和出现问题的上下文,不然定位问题和复现问题可能就要花去你大部分时间了,同时提前做好处理方案,不要出现问题了就抓瞎了。当然如果我们依赖其他系统提供的数据,那依然可以使用缓存来加一层保障。
其中有可能你的应用面临突发流量时,需要对一些下游弱依赖进行降级,以保证当前系统以及下游的正常运行使用。需要明确的是依赖可以降级,但是功能不能降级,举个例子,实现一个商品收藏夹的页面功能,每个商品上会有一个加购按钮,如果商品是否可以加购的查询依赖于二方系统,那你就需要考虑面临突发流量时对该依赖进行降级,错误的降级方式是直接不展示这个加购按钮,这种方式降级了依赖同时降级了功能。比较好的处理方式是,全部商品都展示加购按钮,当用户点击加购时,才去请求二方系统,检查是否可以加购。通过牺牲一点用户的体验来保证整个系统的稳定性。
多进程
我们知道 javascript 单线程运行的,换句话说一个 Node.js 进程只能运行在一个 CPU 上,因此无法享受到多核运算的好处。Node.js 针对这个问题提供了 Cluster 模块,可以在服务器上同时启动多个进程,每个进程里都跑的是同一份源代码,并且可以同时监听一个端口。当然作为一个对外服务的应用来说,要考虑的东西还有很多,比如异常如何处理,进程间如何共享资源,进程间如何调度等等。如果你使用的是 Egg/Midway,这些问题框架已经帮你解决掉了。对于 Egg 来说,你可以详细参考:多进程模型和进程间通讯。这里不再赘述。
单元/功能测试
单元/功能测试的重要性毋容置疑,为代码质量提供持续性的保障,同时可以增强你修改、发布代码的信心。单元测试用于测试最小功能单元,比如单个方法。而针对 Node 开发的 Web 应用,我们可以直接针对接口进行功能测试,如果针对函数方法写单元测试的话,成本有点高,而接口的功能测试基本可以覆盖 Router、Controller、Model 整条链路了,覆盖不到的函数逻辑再对其单独编写单元测试用例,这样成本会小很多,而且达到的测试覆盖率并没有折扣。
如果你使用了 Egg/Midway 等框架,框架本身对单元测试能力已经帮你进行了集成,你只需要按照约定编写用例并使用即可,可以参考 Egg 单元测试。
持续集成
有了单元/功能测试以后,下一步就需要考虑持续集成了。阿里云提供了 CodePipline 以及云效 帮助你进行快速可靠的持续集成与交付
流程规范
开发、测试、发布过程中的流程规范也是保障稳定性的重要一环,可以有效避免一些人为的疏忽。比如应用写了测试用例,但是在用例没通过的情况下发布上线等等。因此配置一套自动化的流程规范十分有必要,阿里云的云效提供了完整的项目管理、持续集成的能力,在上面可以完成日常开发、测试、发布的流程。详细的操作可以参考其帮助文档。这里补充一些流程上的实践。
CodeReview

CodeReview 十分重要,它可以及时发现一些比较明显的代码、逻辑问题,同时可以保证多人合作的代码理解和维护。但是如果没有一个流程规范和卡口,CodeReview 是很难自发坚持下去的。
CodeReview 可以分为提交前(pre-commit)和提交后(post-commit)两种。本身就是字面意思,pre-commit 既必须通过 CodeReview 才可以提交代码,而 post-commit 既先提交代码,然后发起 CodeReview。相比起来,pre-commit 流程更加合理,因为 post-commit 不阻碍代码提交变更、发布的流程,既即使没有 reivew 通过,依然可以提交变更并发布。而 post-commit 相对于 pre-commit 来说会更容易实施。
而对于 post-commit,如果其 review 的结果并不影响代码提交变更和发布,那如何做流程卡口呢?你可以使用云效自定义流水线,通过人工卡点的方式来保证流程。
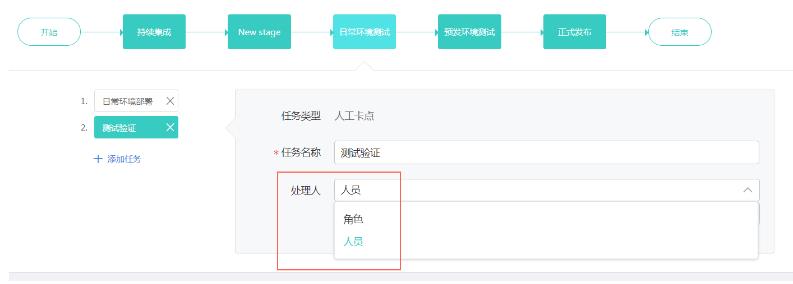
通过人工卡点,来增加流程卡口,后续云效也会上线 CodeReivew 功能,敬请期待。
如果你觉得配置 pre-commit 过于麻烦,而 post-commit 流程上过于滞后的话,也可以采用依靠约定的折中方案,使用 Git 的 PR 功能。我们不从部署分支上进行开发,而是基于部署分支继续检出开发分支,开发完成需要提交部署时,提交 PR,指定给需要 review 的同学,通过后会将开发分支合并到部署分支。当然这种方式依赖流程规范的约定,无法进行强制的卡口。
增加测试卡点
前文讲过,我们需要为应用实现单元/功能测试,那如何保证应用部署发布前一定通过了单元/功能测试呢?我们可以在云效的流程中增加测试卡点,来保证我们编写的测试用例通过后,当前部署分支才可进行发布,通过云效的自动化测试卡口保障持续交付质量。
首先我们需要新建一个测试任务,在 [云效的测试服务]中选择“单元测试”。
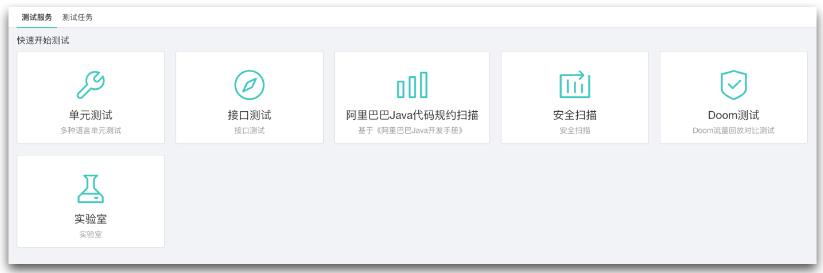
将创建的测试任务和流水线关联,作为持续集成交付的测试卡口。每次集成交付,都会运行测试任务,同时保证测试结果达到红线要求,否则流水线运行失败。
性能测试
应用在发布前以及上线后周期性的,都需要做性能测试,一方面让我们对应用的吞吐心里有数,另一方面保证长时间运行的稳定,毕竟有些问题可能是运行很多次才可能出现的,比如 OOM 等。阿里云提供了方便的性能测试产品:PTS。
PTS 支持构建串行、并行的构建你的压测场景,并且支持并发和 TPS 模式来控制你的压测流量,最后,PTS 还提供了丰富的监控和压测报告,实时监控和报告中包括但不局限于各 API 的并发、TPS、响应时间和采样的日志,请求和响应时间还有不同的细分数据,和阿里云生态内的云监控、ARMS监控无缝集成。
创建压测场景
首先你需要对压测进行计划,需要明确场景,对流量进行预估,设定目标值,否则压测毫无意义,你完全无法明确当前系统是否可以稳定的支撑你的业务场景。其次需要对各种系统预案进行摸高压测,明确各个预案下能支持的压力上限,以此来保证在合适的情况下可以执行对应的预案并可以达到预期效果。
详细的创建压测场景的步骤,可以参考 PTS 帮助文档。一般来说,我们可以创建两个场景,分别用来回归测试和容量评估,回归测试的场景,可以设置固定的并发数量,周期性的持续压测,来暴露一些长时间运行可能的潜在问题、而容量评估场景,需要设置自动增长的方式,用来寻找系统的压力上限。
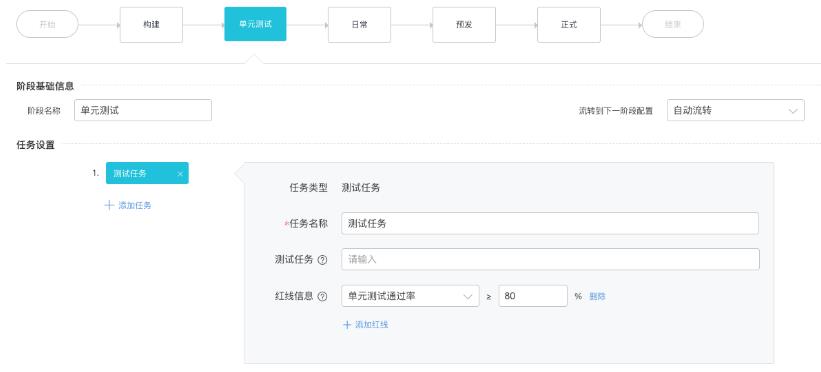
施压配置
对于容量评估的场景,我们可以开启自动增长,按照固定比例进行压测量级的递增,并在每个量级维持固定压测时长,以便观察业务系统运行情况。
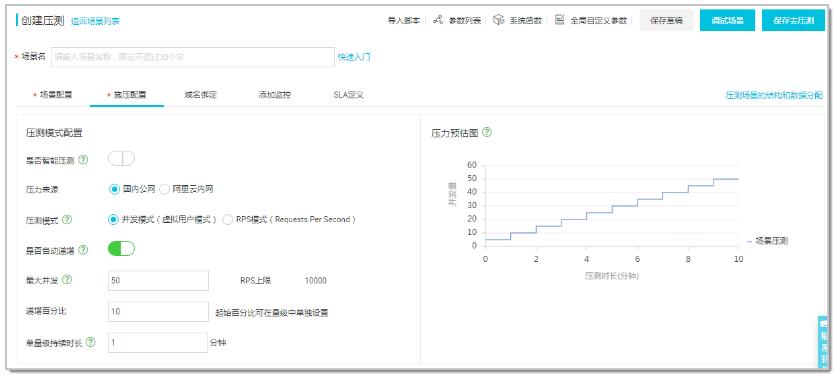
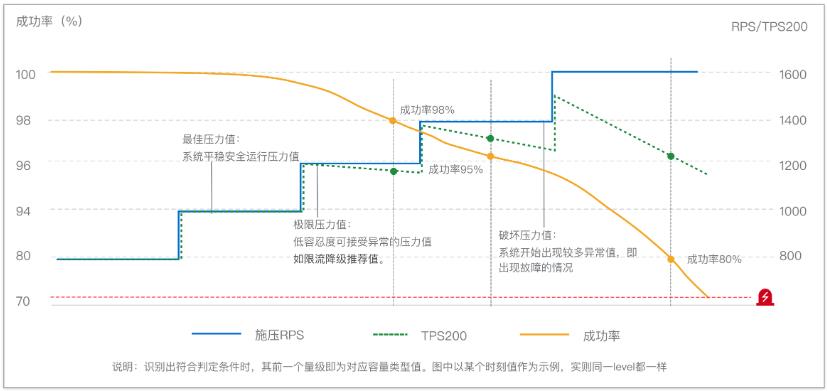
同时 PTS 给我们提供了更加方便的智能测试模式,帮我们探测系统的最佳压力点、极限压力点和破坏压力点,帮助我们评估系统容量。
性能指标
对于预估正常的并发量来说,性能测试一般通过标准为:
超时率小于万分之一
错误率小于万分之一
CPU 利用率小于 75%
Load 平均每核 CPU 小于 1
内存使用率小于 80%
对于压力测试来说,一般我们把 CPU 压到 100% 或者内存压到 90% 左右,既可认为压到了极限,如果此时你发现其他指标可能都是正常的,那么说明你的应用可能还有很大的优化空间,可以有针对性的去检查并进一步优化。
回归测试
我们需要保证应用长时间持续性的稳定,而有些问题可能是运行很多次才可能出现的,比如 OOM 等。而回归测试指的是周期性的持续压测,通过回归测试,来提前暴露出系统长时间运行中可能出现的潜在问题。
PTS 为我们提供的方便的定时功能,可以指定测试任务的执行日期、执行时间、循环周期和通知方式等,从而实现定时压测。你可以参考 PTS 定时压测来配置自己的回归测试。
当然云效也给我们提供了功能更为强大的回归测试平台,可以将线上真实流量复制并用于自动回归测试的平台。通过它,不仅能够实现低成本的日常自动化回归,同时通过它提供扩展能力可以支持系统重构升级的自动回归。比如系统重构时,复制真实线上环境流量到被测试环境进行回归,相当于在不影响业务的情况下提前上线检测系统潜在的问题。同时还可以将录制的流量作为用例管理起来进行自动化回归。

监控报警
应用出现异常并不可怕,可怕的是出现问题以后而并不自知。没有哪个系统可以保证线上不出现问题,重要的是及时发现问题并解决,不让问题持续恶化。因此线上的监控和报警十分重要。
监控与日志
一般来说我们需要进行三个方面的监控:业务可用性、业务指标衡量、业务错误追踪,而对应的方式为:健康检查、单点度量、错误日志和链路。
健康检查
健康检查是用来定义一个应用当前的状态,它需要能频繁调用并快速返回,而健康检查包含着一系列的检查项,比如:
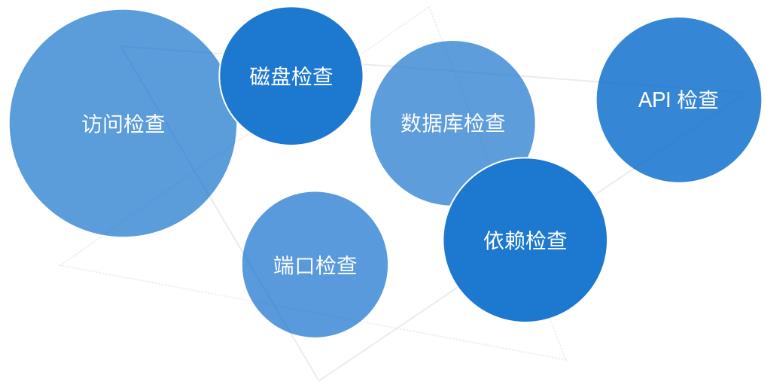
一般来说,我们可以通过 Pandora + 云监控 CloudMonitor 来帮助我们进行健康检查。
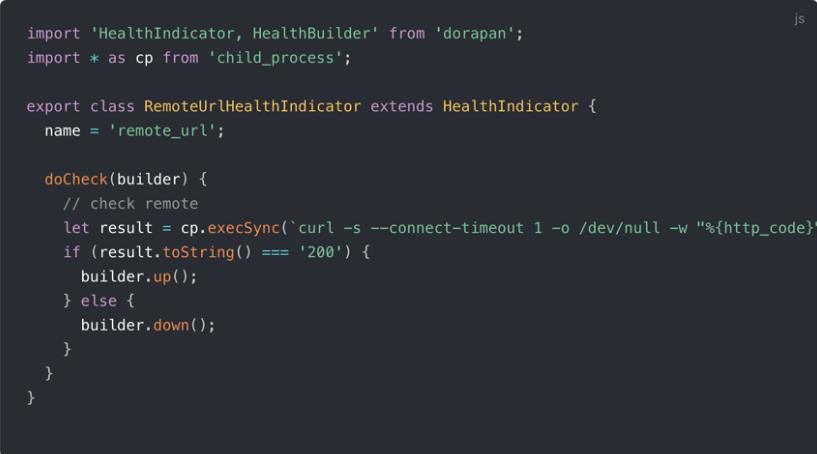
首先 Pandora 是阿里内部开源出去的,提供一个通用的 Node.js 应用运行时模型和相关基础设施。提供一个标准的 Node.js 的 DevOps 流程。其提供了一些基础的检查,比如磁盘检查,端口检查等。同时我们也可以自定义更多的检查项。
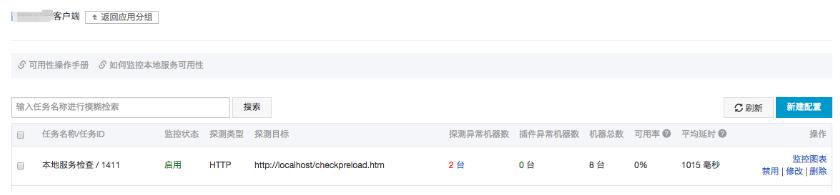
Pandora 配置好后,我们可以通过云监控对暴露出来的检查服务进行监控。
单点度量
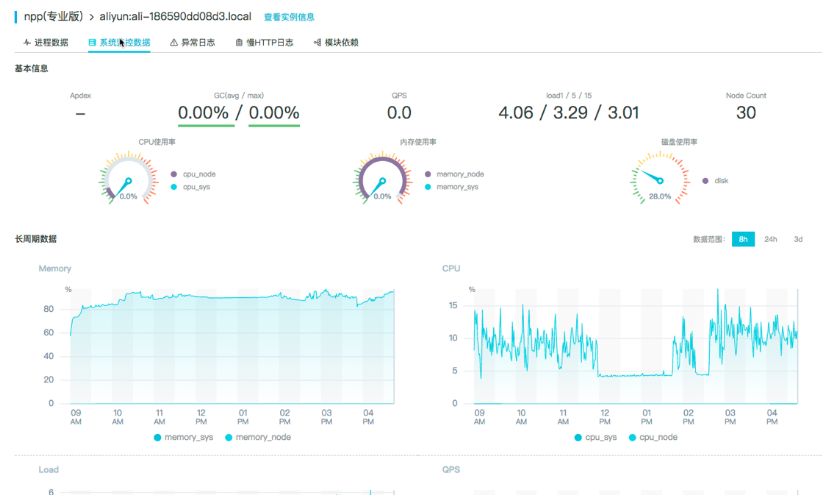
阿里云提供了 Node.js 性能平台来帮助我们对 Node.js 应用进行单点度量。Node.js 性能平台是面向中大型 Node.js 应用提供性能监控、安全提醒、故障排查、性能优化等服务的整体性解决方案。
Node.js 性能平台提供了丰富的度量指标,包括系统、进程的内存、CPU、QPS 等等。
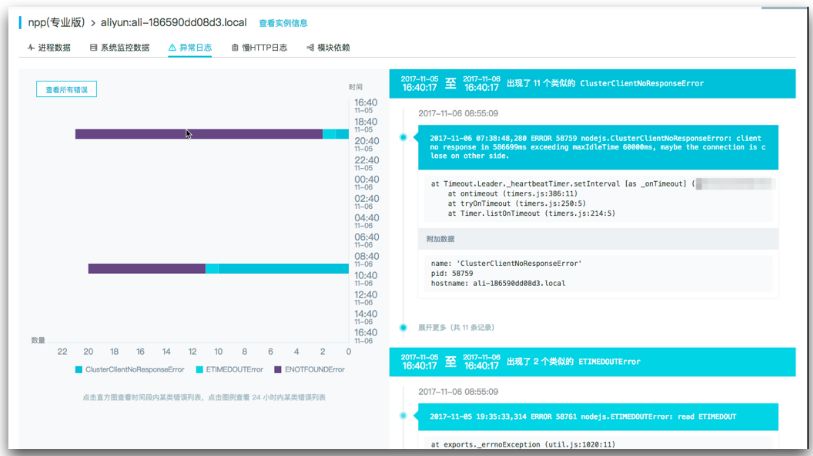
同时,其还为我们提供的故障排查的能力,比如热点函数分析、内存泄露分析等。你可以参考 Node 应用内存泄漏分析方法论与实战来学习使用 Node.js 性能平台发现、定位解决内存泄露问题。
错误日志和链路
一般来说,我们需要采集以下几类日志:
trace:请求链路的监控日志。当出现错误时,可以根据 traceId 快读的定位到产生问题的那个请求链路,还原上下文。尤其是我们的应用如果依赖了其他二方/三方系统,链路比较长时,可以明确的知道调用依赖系统时的入参和返回,快读定位出现问题的环节,减少扯皮和定位还原问题的时间。
error:错误日志。包括应用本身和业务逻辑的错误。
metric:CPU、内存等机器指标
nginx:如果你的应用用了 nginx,nginx 的错误日志的采集也是很关键的。nginx 的错误日志可能是最容易被忽略的,经常见到这样的场景,应用没有异常,但是访问就是挂的,开发吭哧吭哧排查半天,终于定位到 nginx 有错误抛出。
其中,trace 链路日志是很重要但是容易被忽略的日志,链路的重要性不言而喻,可以帮助我们分析上下游依赖、进行节点分析和故障排查,尤其是依赖其他二方/三方系统时,trace 链路日志十分重要,但是也是需要花非常大的精力去做,业界的 newRelic,oneAPM 都有着非常明显的链路视图。
一般来说我们采用 Pandora + SLS 日志服务 + Node.js 性能平台 来进行日志收集。
其中 Pandora 通过拦截 httpServer 和 httpClient,在对我们系统业务没有侵入性的同时帮助我们收集 trace 链路日志。
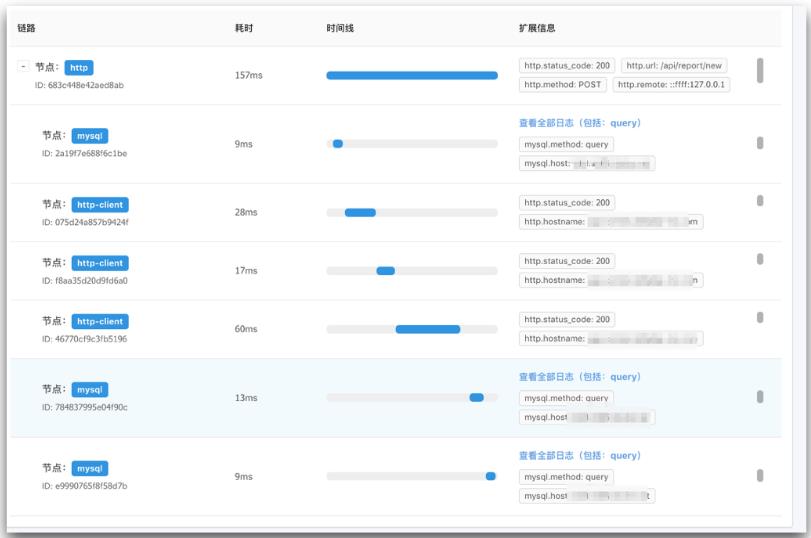
配合 SLS 日志服务,可以帮助我们无死角的采集我们需要的任何日志信息。
报警
应用出现异常后,需要有及时的报警机制来提醒我们,以便快速响应和处理。
监控项与报警指标
一般来说,需要的监控项及报警指标为:
日志监控
Nginx 错误日志
应用 Error 日志
Trace 链路日志
日志报警
每分钟错误日志数量 > 流量 * SLA 等级
机器指标
CPU > 70%
内存泄露:@heap_used / @heap_limit > 0.7
Load > CPU 核数
流量监控
周同比监控:同比下降 > SLA 的承诺
流量预警,接近 QPS 峰值
其中 SLA 为服务等级,用百分比的服务可用性来来定义服务质量。
报警配置
一般来说我们使用 云监控 CloudMonitor + SLS 日志服务 + Node.js 性能平台的报警配置即可。
其中云监控 CloudMonitor的报警主要针对上文提到的健康检查。你可以参考云监控报警服务来配置报警功能。
对于 SLS,我们可以对错误数量进行报警,或者根据同比环比来进行报警。比如我们可以新建两个快速查询,针对我们应用 error 和 nginx error 日志。
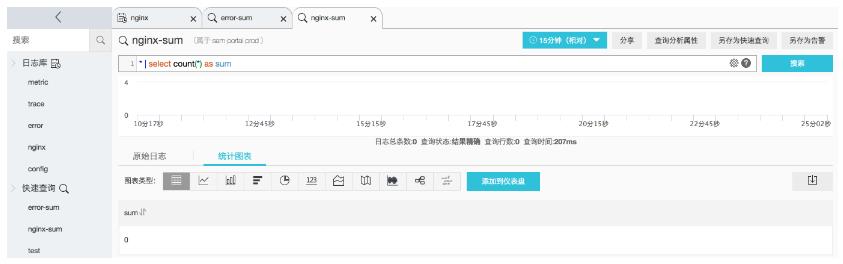
这里的查询语句为 * | select count(*) as sum。然后将快速查询另存为告警,根据需要配置告警规则,触发告警时,可以选择通过钉钉机器人进行通知。
对于服务器指标告警,比如 CPU、内存等。我们可以利用 Node.js 性能平台 配置监控。
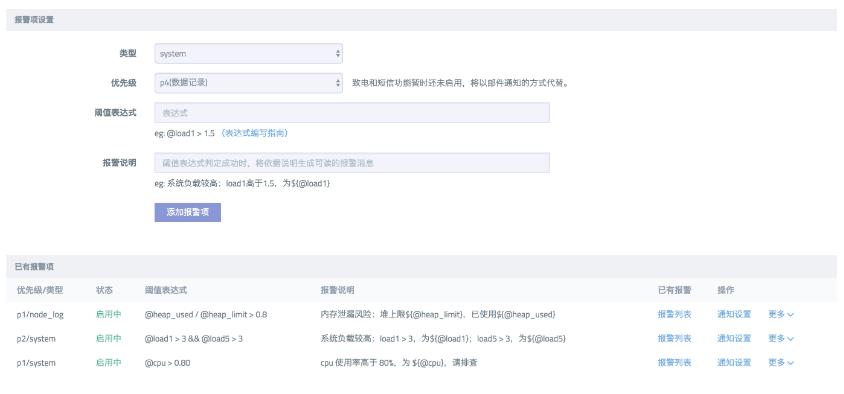
可以看到,上面配置的告警规则是:堆上线 80%、load1 和 load5 <= 3、cpu 上线 80%。这里需要编写监控项的表达式,可以参考如何进行监控项表达式的编写。
最后
其实稳定性的保障还有很多工作和措施可以做,比如我们的部署可以采取多集群、多 Region 的部署,这样可以保证当某个集群或者 Region 出现故障,不会造成更大范围的问题,保证故障范围可控。同时我们还可以采取灰度发布的方式,在不断验证新上线功能的情况下,平滑的过渡发布上线,保证应用整体稳定性等等。
最后的最后,稳定性保障是应用整个生命周期内的事情,是每个开发者的责任和义务。

交流学习
在看你最美
以上是关于阿里云的 Node.js 稳定性实践的主要内容,如果未能解决你的问题,请参考以下文章