说Node.js做后端开发,stream有必要了解下
Posted 程序员成长指北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了说Node.js做后端开发,stream有必要了解下相关的知识,希望对你有一定的参考价值。
什么是stream
定义
流的英文stream,流(Stream)是一个抽象的数据接口,Node.js中很多对象都实现了流,流是EventEmitter对象的一个实例,总之它是会冒数据(以 Buffer 为单位),或者能够吸收数据的东西,它的本质就是让数据流动起来。可能看一张图会更直观:
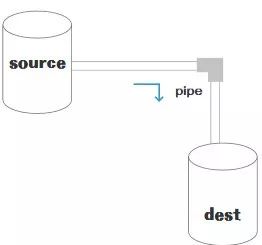
注意:stream不是node.js独有的概念,而是一个操作系统最基本的操作方式,只不过node.js有API支持这种操作方式。linux命令的|就是stream。
为什么要学习stream
视频播放例子
小伙伴们肯定都在线看过电影,对比定义中的图-水桶管道流转图,source就是服务器端的视频,dest就是你自己的播放器(或者浏览器中的flash和h5 video)。大家想一下,看电影的方式就如同上面的图管道换水一样,一点点从服务端将视频流动到本地播放器,一边流动一边播放,最后流动完了也就播放完了。
说明:视频播放的这个例子,如果我们不使用管道和流动的方式,直接先从服务端加载完视频文件,然后再播放。会造成很多问题
因内存占有太多而导致系统卡顿或者崩溃
因为我们的网速 内存 cpu运算速度都是有限的,而且还要有多个程序共享使用,一个视频文件加载完可能有几个g那么大。
读取大文件data的例子
有一个这样的需求,想要读取大文件data的例子
使用文件读取
const http = require('http');
const fs = require('fs');
const path = require('path');
const server = http.createServer(function (req, res) {
const fileName = path.resolve(__dirname, 'data.txt');
fs.readFile(fileName, function (err, data) {
res.end(data);
});
});
server.listen(8000);
使用文件读取这段代码语法上并没有什么问题,但是如果data.txt文件非常大的话,到了几百M,在响应大量用户并发请求的时候,程序可能会消耗大量的内存,这样可能造成用户连接缓慢的问题。而且并发请求过大的话,服务器内存开销也会很大。这时候我们来看一下用stream实现。
const http = require('http');
const fs = require('fs');
const path = require('path');
const server = http.createServer(function (req, res) {
const fileName = path.resolve(__dirname, 'data.txt');
let stream = fs.createReadStream(fileName); // 这一行有改动
stream.pipe(res); // 这一行有改动
});
server.listen(8000);
使用stream就可以不需要把文件全部读取了再返回,而是一边读取一边返回,数据通过管道流动给客户端,真的减轻了服务器的压力。
看了两个例子我想小伙伴们应该知道为什么要使用stream了吧!因为一次性读取,操作大文件,内存和网络是吃不消的,因此要让数据流动起来,一点点的进行操作。
stream流转过程
再次看这张水桶管道流转图
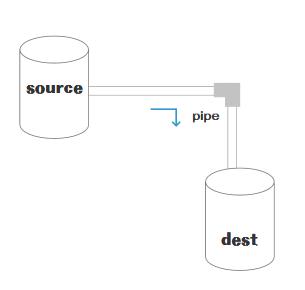
图中可以看出,stream整个流转过程包括source,dest,还有连接二者的管道pipe(stream的核心),分别介绍三者来带领大家搞懂stream流转过程。
stream从哪里来-soucre
stream的常见来源方式有三种:
从控制台输入
http请求中的request读取文件
这里先说一下从控制台输入这种方式,2和3两种方式stream应用场景章节会有详细的讲解。
看一段process.stdin的代码
process.stdin.on('data', function (chunk) {
console.log('stream by stdin', chunk)
console.log('stream by stdin', chunk.toString())
})
//控制台输入koalakoala后输出结果
stream by stdin <Buffer 6b 6f 61 6c 61 6b 6f 61 6c 61 0a>
stream by stdin koalakoala
运行上面代码:然后从控制台输入任何内容都会被data 事件监听到,process.stdin就是一个stream对象,data 是stream对象用来监听数据传入的一个自定义函数,通过输出结果可看出process.stdin是一个stream对象。
说明:stream对象可以监听"data","end","opne","close","error"等事件。node.js中监听自定义事件使用.on方法,例如process.stdin.on(‘data’,…), req.on(‘data’,…),通过这种方式,能很直观的监听到stream数据的传入和结束
连接水桶的管道-pipe
从水桶管道流转图中可以看到,在source和dest之间有一个连接的管道pipe,它的基本语法是source.pipe(dest),source和dest就是通过pipe连接,让数据从source流向了dest。
stream到哪里去-dest
stream的常见输出方式有三种:
输出控制台
http请求中的response写入文件
stream应用场景
stream的应用场景主要就是处理IO操作,而http请求和文件操作都属于IO操作。这里再提一下stream的本质——由于一次性IO操作过大,硬件开销太多,影响软件运行效率,因此将IO分批分段进行操作,让数据像水管一样流动起来,直到流动完成,也就是操作完成。下面对几个常用的应用场景分别进行介绍
介绍一个压力测试的小工具
一个对网络请求做压力测试的工具ab,ab 全称 Apache bench ,是 Apache 自带的一个工具,因此使用 ab 必须要安装 Apache 。mac os 系统自带 Apache ,windows用户视自己的情况进行安装。运行ab 之前先启动 Apache ,mac os 启动方式是 sudo apachectl start 。
介绍这个小工具的目的是对下面几个场景可以进行直观的测试,看出使用stream带来了哪些性能的提升。
get请求中应用stream
这样一个需求:
使用node.js实现一个http请求,读取data.txt文件,创建一个服务,监听8000端口,读取文件后返回给客户端,讲get请求的时候用一个常规文件读取与其做对比,请看下面的例子。
常规使用文件读取返回给客户端response例子 ,文件命名为
getTest1.js
// getTest.js
const http = require('http');
const fs = require('fs');
const path = require('path');
const server = http.createServer(function (req, res) {
const method = req.method; // 获取请求方法
if (method === 'GET') { // get 请求方法判断
const fileName = path.resolve(__dirname, 'data.txt');
fs.readFile(fileName, function (err, data) {
res.end(data);
});
}
});
server.listen(8000);
使用stream返回给客户端response 将上面代码做部分修改,文件命名为
getTest2.js
// getTest2.js
// 主要展示改动的部分
const server = http.createServer(function (req, res) {
const method = req.method; // 获取请求方法
if (method === 'GET') { // get 请求
const fileName = path.resolve(__dirname, 'data.txt');
let stream = fs.createReadStream(fileName);
stream.pipe(res); // 将 res 作为 stream 的 dest
}
});
server.listen(8000);
对于下面get请求中使用stream的例子,会不会有些小伙伴提出质疑,难道response也是一个stream对象,是的没错,对于那张水桶管道流转图,response就是一个dest。
虽然get请求中可以使用stream,但是相比直接file文件读取·res.end(data)有什么好处呢?这时候我们刚才推荐的压力测试小工具就用到了。getTest1和getTest2两段代码,将data.txt内容增加大一些,使用ab工具进行测试,运行命令ab -n 100 -c 100 http://localhost:8000/,其中-n 100表示先后发送100次请求,-c 100表示一次性发送的请求数目为100个。对比结果分析使用stream后,有非常大的性能提升,小伙伴们可以自己实际操作看一下。
post中使用stream
/*
* 微信生成二维码接口
* params src 微信url / 其他图片请求链接
* params localFilePath: 本地路径
* params data: 微信请求参数
* */
const downloadFile=async (src, localFilePath, data)=> {
try{
const ws = fs.createWriteStream(localFilePath);
return new Promise((resolve, reject) => {
ws.on('finish', () => {
resolve(localFilePath);
});
if (data) {
request({
method: 'POST',
uri: src,
json: true,
body: data
}).pipe(ws);
} else {
request(src).pipe(ws);
}
});
}catch (e){
logger.error('wxdownloadFile error: ',e);
throw e;
}
}
看这段使用了stream的代码,为本地文件对应的路径创建一个stream对象,然后直接.pipe(ws),将post请求的数据流转到这个本地文件中,这种stream的应用在node后端开发过程中还是比较常用的。
post与get使用stream总结
request和reponse一样,都是stream对象,可以使用stream的特性,二者的区别在于,我们再看一下水桶管道流转图,
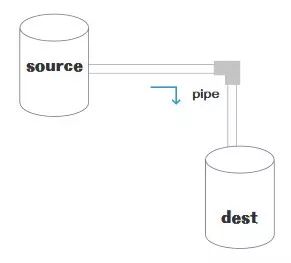 request是source类型,是图中的源头,而response是dest类型,是图中的目的地。
request是source类型,是图中的源头,而response是dest类型,是图中的目的地。
在文件操作中使用stream
一个文件拷贝的例子
const fs = require('fs')
const path = require('path')
// 两个文件名
const fileName1 = path.resolve(__dirname, 'data.txt')
const fileName2 = path.resolve(__dirname, 'data-bak.txt')
// 读取文件的 stream 对象
const readStream = fs.createReadStream(fileName1)
// 写入文件的 stream 对象
const writeStream = fs.createWriteStream(fileName2)
// 通过 pipe执行拷贝,数据流转
readStream.pipe(writeStream)
// 数据读取完成监听,即拷贝完成
readStream.on('end', function () {
console.log('拷贝完成')
})
看了这段代码,发现是不是拷贝好像很简单,创建一个可读数据流readStream,一个可写数据流writeStream,然后直接通过pipe管道把数据流转过去。这种使用stream的拷贝相比存文件的读写实现拷贝,性能要增加很多,所以小伙伴们在遇到文件操作的需求的时候,尽量先评估一下是否需要使用stream实现。
前端一些打包工具的底层实现
目前一些比较火的前端打包构建工具,都是通过node.js编写的,打包和构建的过程肯定是文件频繁操作的过程,离不来stream,例如现在比较火的gulp,有兴趣的小伙伴可以去看一下源码。
stream的种类
Readable Stream可读数据流Writeable Stream可写数据流Duplex Stream双向数据流,可以同时读和写Transform Stream转换数据流,可读可写,同时可以转换(处理)数据(不常用)
之前的文章都是围绕前两种可读数据流和可写数据流,第四种流不太常用,需要的小伙伴网上搜索一下,接下来对第三种数据流Duplex Stream 说明一下。
Duplex Stream 双向的,既可读,又可写。Duplex streams同时实现了 Readable和Writable 接口。Duplex streams的例子包括
tcp socketszlib streamscrypto streams我在项目中还未使用过双工流,一些Duplex Stream的内容可以参考这篇文章NodeJS Stream 双工流
stream有什么弊端
用
rs.pipe(ws)的方式来写文件并不是把 rs 的内容append到 ws 后面,而是直接用 rs 的内容覆盖 ws 原有的内容已结束/关闭的流不能重复使用,必须重新创建数据流
pipe方法返回的是目标数据流,如a.pipe(b)返回的是 b,因此监听事件的时候请注意你监听的对象是否正确如果你要监听多个数据流,同时你又使用了
pipe方法来串联数据流的话,你就要写成:代码实例:
data
.on('end', function() {
console.log('data end');
})
.pipe(a)
.on('end', function() {
console.log('a end');
})
.pipe(b)
.on('end', function() {
console.log('b end');
});
stream的常见类库
event-stream 用起来有函数式编程的感觉
awesome-nodejs#streams也是一个不错的第三方stream库,有兴趣的小伙伴可以github看一下
总结
本篇文章属于进阶路线【Node必知必会系列】,看完了这篇文章是不是对stream有了一定的了解,并且知道了node对于文件处理还是有完美的解决方案的。本文中三次展示了水桶管道流转图,总要的事情说三遍希望小伙伴们记住它,除了以上内容小伙伴们会不会有一些思考,比如
stream数据流转具体内容是什么呢?二进制还是
string类型还是其他类型,该类型为stream带来了什么好处?水桶管道流转图中的水管,也就是
pipe函数什么时候触发的呢?在什么情况下触流转发?底层机制是什么?上面的疑问(由于篇幅过长拆分为两篇)会在我stream的第二篇文章为大家详细讲解


交流学习
加入我们

以上是关于说Node.js做后端开发,stream有必要了解下的主要内容,如果未能解决你的问题,请参考以下文章