小烨推荐分享一个明学平台的实验-Mahout贝叶斯分类算法
Posted SureData数烨数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小烨推荐分享一个明学平台的实验-Mahout贝叶斯分类算法相关的知识,希望对你有一定的参考价值。
或者明学平台二维码:

25.1 实验目的
1) 了解Mahout分类算法基础;
2) 了解分类算法:朴素贝叶斯算法基础及原理;
3) 通过示例,了解分类算法:朴素贝叶斯算法运行过程;
4) 了解mahout与hadoop版本支持问题。
25.2 实验要求
实验结束,要求:
1) 搭建好Hadoop集群,并完成Mahout自带贝叶斯算法示例;
2) 通过示例运行,理解分类算法:朴素贝叶斯算法运行原理。
25.3 实验原理
25.3.1 分类算法简介
分类是一种基于训练样本数据(这些数据都已经被贴标签)区分另外的样本数据标签的过程,即另外的样本数据应该如何贴标签的问题。举一个简单的例子,现在有一批人的血型已经被确定,并且每个人都有M个指标来描述这个人,那么这批人的M个指标数据就是训练样本数据(这些数据都是已经被贴好标签了的),根据这些训练样本数据,建立分类器(即运用分类算法得到一些规则),然后使用分类器对测试样本集中的未被贴标签的数据进行血型判断。分类算法的一般过程如图25-1所示:
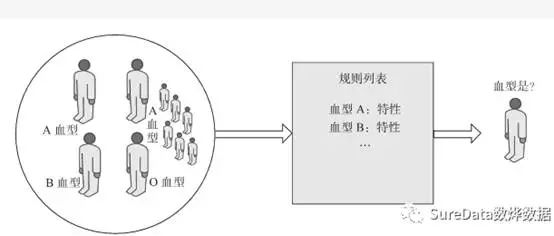
图 25-1 分类算法过程
即在分类里,训练样本数据(这些数据都是已经被贴好标签的)---> 根据这些训练样本数据,建立好分类器(运用分类算法得到一些规则)--->使用分类器对测试样本数据(这些数据是没有贴标签的)--->做出判断,达到分类的目的。分类算法按原理分为以下四大类:
基于统计:如贝叶斯算法
基于规则:如决策树算法
基于神经网络:如神经网络算法
基于距离:如KNN算法
本实验主要介绍下朴素贝叶斯算法。
25.3.2 朴素贝叶斯算法
25.3.2.1 原理
条件概率P(A|B) 表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为P(A|B)= P(AB)/ P(B)。该公式说明了如何计算已知B发生的前提下A还要发生的概率。贝叶斯定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。所以该定理的用途十分广泛,可以用作数据的预测分类等。下面直接给出贝叶斯定理:
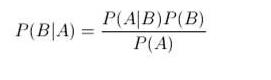
贝叶斯分类的正式定义如下:
(1)设
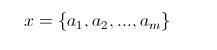
为一个待分类项,而每个a为x的一个特征属性。
(2)有类别集合
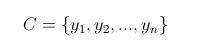
(3)计算
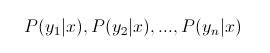
(4)如果
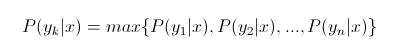
,则
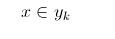
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
(1)找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
(2)统计得到在各类别下各个特征属性的条件概率估计。即
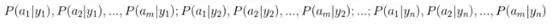
(3)如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
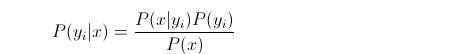
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
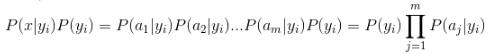
也就是说只需要计算出每一个特征向量在某一种分类的累乘然后乘以这个分类的概率。这样算出的最大值所在的分类则为需要的分类。
25.3.2.1 分类流程
根据上述分析,朴素贝叶斯分类的流程如图 25-2所示:
图 25-2 朴素贝叶斯分类流程
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段――准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段――分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段――应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
25.4 实验步骤
本例主要演示,使用Mahout命令完成贝叶斯分类,以下实验都在client服务器操作。
由于mahout最新的版本都只支持Hadoop1.x,我们实验环境是Hadoop2.x,大家可以自行编译基于Hadoop2.x的mahout进行实验,或者安装Hadoop1.x版本。本实验就不做演示。
25.4.1 Mahout环境准备
按照前面实验方法,配置Mahout,验证Mahout是否正确安装。
25.4.4 测试数据准备
Client服务器上本地创建目录/tmp/mahout-work-root,并将实验数据拷贝到本路径下:
[root@client ~]# mkdir /tmp/mahout-work-root |
HDFS上使用创建目录/tmp/mahout-work-root:
[root@client ~]# hadoop fs -mkdir -p /tmp/mahout-work-root |
25.4.5 执行Mahout中的贝叶斯示例脚本
执行如下命令执行Mahout的贝叶斯示例程序:
[root@client ~]# /suredata/mahout/examples/bin/classify-20newsgroups.sh |
选择模式2(naivebayes)。
查看该示例脚本分析执行流程如下:
1) 将数据文件解压,并上传到HDFS相应目录下;
2) 产生Input数据集,即对训练数据集进行预处理,数据准备阶段,将各类中的数据进行分词处理,去掉标点及副词等,同时将各类中的文件读入到一个大文件中,使得每类最后只有一个文件包含起初所有的文件,mahout下处理的文件必须是SequenceFile格式的,还需要把txtfile转换成sequenceFile;
3) 用处理好的训练数据集进行训练得出分类模型即中间结果,模型保存在分布式文件系统上;
4) 用模型进行测试。
25.5 实验结果
可以看到程序结果,如图25-3所示:
图 25-3 实验结果
以上是关于小烨推荐分享一个明学平台的实验-Mahout贝叶斯分类算法的主要内容,如果未能解决你的问题,请参考以下文章