免费赠书贝叶斯分类器的实现
Posted Python那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了免费赠书贝叶斯分类器的实现相关的知识,希望对你有一定的参考价值。
本文的主要目的是引导读者更加深入的学习数据挖掘和分析技术的同时进一步熟悉Python数据分析的基本流程以及对加深对Python编程的掌握。
贝叶斯理论介绍
在概率和统计学领域,贝叶斯理论基于对某一事件证据的认识,来预测该时间事件的发生概率。比如,如果癌症和年龄相关,在考虑年龄影响的条件下,预测癌症的概率的准确率就会高于不考虑年龄的准确率。贝叶斯理论的表达公式如下所示:
A、B为事件,并且P(B)≠0
P(A)和P(B)为独立观察事件A、B发生的概率
P(A|B),条件概率,即是在B事件发生的情况下,A事件发生的概率
P(B|A),条件概率,即是在A事件发生的情况下,B事件发生的概率
假设药品测试的灵敏度为99%,准确率为99%。意思就是如果使用了药品,那么99%的可能性,会测试结果会显阳性;如果没有用药,那有99%的可能性测试结果显阴性。现在随机抽出一个人,测试结果显阳性,试问用药的可能性有多大。
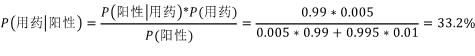
这个结果与直觉有较大的出入,计算结果表明随机抽出一个人进行用药测试,即使结果呈阳性,没有用药的可能性也要大于用药的可能性。
在机器学习领域,朴素贝叶斯分类器是基于贝叶斯理论并假设各特征相互独立的分类方法。朴素贝叶斯模型构建分类器的基本方法是:使用特征向量来表示某个,并赋给这些实体代表其类别的标签。所有的朴素贝叶斯分类器都假设某个特征的值与另一个特征的值是相互独立的。比如,一种水果,形状为圆形、直径在5cm左右且颜色为红色被分类为苹果。贝叶斯在进行分类的时候,在判别这种水果为苹果时,只考虑这几种特征独自对分类概率的影响,而不去考虑形、颜色、直径这些特征的相关性。贝叶斯分类器可以通过监督式学习的方式非常高效的训练。。
尽管贝叶斯分类器的假设条件过于简单,甚至与实际不符。但大多数时候,它都有较好的表现;它有一个较大的优点是,只需要少量的训练数据,就可以建立起分类所需要的所有参数。
从抽象的角度而言,朴素贝叶斯其实就是条件概率模型:给定一个实体,求解这个实体属于某一个类别的概率,这个实体用一个长度为n的向量来表示,向量中的每一个元素都表示一个特征量的值(相互独立)。
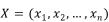
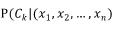 。
。
使用贝叶斯理论计算上式:
观察上式 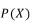 对于上式对于某一个实体而言是一个常数,所以某一个实体属于某一类与的大小无关。使用之前的假设特征量之间相互独立以及联合概率的计算公式:
对于上式对于某一个实体而言是一个常数,所以某一个实体属于某一类与的大小无关。使用之前的假设特征量之间相互独立以及联合概率的计算公式:
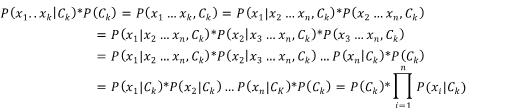
基于介绍的各特征值相互独立的概率模型,再加上一个决策规则,就构成了贝叶斯分类器。决策规则比较常用的是选择最大概率规则来判断对应的类别,即实体的所属类别为下式,最大值时,k所对应的类别。
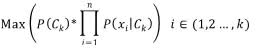
下面用一个例子,来说明如何应用贝叶斯分类器,假设现在有1000封邮件,其中200封邮件为垃圾邮件,800封为正常。现在一封邮件的特征值为(“ 你好”,”中国”)。假设在垃圾邮件里面出现“你好”的频数为50,“中国”的频数为1。在正常邮件里面出现”你好”的频数为700,“中国”的频数为80。分别计算邮件属于正常邮件和垃圾邮件的概率:
P(垃圾邮件|(“你好”,“中国”))=P(“你好”|垃圾邮件)*P(“中国”|垃圾邮件)=
50/200*1/200=0.125%。
类似的,计算出正常邮件的概率为8.75%。正常邮件的概率大于垃圾邮件的概率,根据最大概率规则判断这封邮件是正常邮件。
bayes分类器的实现
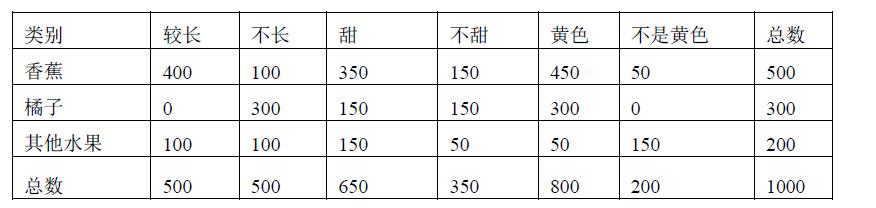
本节主要介绍如何使用Python来实现贝叶斯分类器,数据集如表所示:
使用文本编辑器,建立一个bayes_classfier.py的文件,写入下面的代码。
#bayes分类器源代码
datasets={'banana':{'long':400,'not_long':100,
'sweet':350,'not_sweet':150,
'yellow':450,'not_yellow':50},
'orange':{'long':0,'not_long':300,
'sweet':150,'not_sweet':150,
'yellow':300,'not_yellow':0},
'other_fruit':{'long':100,'not_long':100,
'sweet':150,'not_sweet':50,
'yellow':50,'not_yellow':150},
}
def count_total(data):
'''计算各种水果的总数
return {'bananas':500 ...}'''
count={}
total=0
for fruit in data:
#因为各种水果要么甜要么不甜
#所有可以使用'sweet'和‘not’ sweet 这两种特征的水果数目统计出各种水果的总数
count[fruit]=data[fruit]['sweet']
count[fruit]+=data[fruit]['not_sweet']
total=+count[fruit]
return count,total
def cal_base_rates(data):
'''计算各种水果的先验概率(priori probabilities)
return {'banana':0.5...}'''
categories,total=count_total(data)
base_rates={}
for label in categories:
priori_prob=categories[label]/total
base_rates[label]=priori_prob
return base_rates
def likelihood_prob(data):
'''计算各个特征值在已知水果下的概率(likelihood probabilities)
{'banana':{'long:0.8'...}...}'''
count,_=count_total(data)
likelihood={}
for fruit in data:
#创建一个新字典,临时存储各个特征的概率
attr_prob={}
for attr in datasets[fruit]:
#计算各个特征在已知某种水果下的概率
attr_prob[attr]=data[fruit][attr]/count[fruit]
#把某种水果的各个特征的概率放入到likelihood这个字典中
likelihood[fruit]=attr_prob
return likelihood
def evidence_prob(data):
'''虽然各个证据(特征)的概率的概率对分类结果没有影响
主要目的是说明一些基本的概念
return {'long':'50%'}'''
#水果的所有特征
attrs=list(data['banana'].keys())
count,total=count_total(data)
evidence_prob={}
#计算各种特征的概率
for attr in attrs:
attr_total=0
for fruit in data:
attr_total+=data[fruit][attr]
evidence_prob[attr]=attr_total/total
return evidence_prob
class naive_bayes_classifier:
#初始化贝叶斯分类器
def __init__(self,data=datasets):
self._data=datasets
self._labels=[key for key in self._data.keys()]
self._priori_prob=cal_base_rates(self._data)
self._likelihood_prob=likelihood_prob(self._data)
self._evidence_prob=evidence_prob(self._data)
def get_label(self,length,sweetness,color):
#获取某一组特征值的类别
self._attrs=[length,sweetness,color]
res={}
for label in self._labels:
prob=self._priori_prob[label]
for attr in self._attrs:
prob*=self._likelihood_prob[label][attr]/self._evidence_prob[attr]
res[label]=prob
return res下面使用一些未知类别的数据集,来测试贝叶斯分类器的预测能力。
注意:测试数据集,一定要随机选取,否则不能准确反映bayes分类器的预测能力。
这里使用Python的random模块下的randint来随机生成(0,1) 之间的整数,然后再使用这些随机数生成相应的特征值。使用文本编辑器,建立一个generate_attires.py的文件,写入下面的代码。
import random
def random_attr(pair):
#生成0或1的随机数
return pair[random.randint(0,1)]
def gen_attrs():
#特征值的取值集合
sets=[('long','not long'),('sweet','not sweet'),('yellow','not yellow')]
test_datasets=[]
for i in range(20):
#使用map函数来生成一组特征值
test_datasets.append(list(map(random_attr,sets)))
return test_datasets随机生成的20组特征值如下,
['long', 'sweet', 'yellow']
['not_long', 'not_sweet', 'not_yellow']
['long', 'sweet', 'yellow']
['not_long', 'sweet', 'yellow']
['long', 'sweet', 'not_yellow']
['not_long', 'sweet', 'not_yellow']
['not_long', 'sweet', 'not_yellow']
['not_long', 'not_sweet', 'not_yellow']
['long', 'not_sweet', 'yellow']
['not_long', 'not_sweet', 'yellow']
['long', 'not_sweet', 'yellow']
['not_long', 'not_sweet', 'not_yellow']
['not_long', 'sweet', 'not_yellow']
['long', 'not_sweet', 'not_yellow']
['not_long', 'sweet', 'not_yellow']
['not_long', 'not_sweet', 'yellow']
['long', 'not_sweet', 'not_yellow']
['not_long', 'not_sweet', 'yellow']
['not_long', 'sweet', 'yellow']
['long', 'sweet', 'not_yellow']使用贝叶斯分类器来对测试数据集进行分类。使用文本编辑器,建立一个classfication.py的文件,写入下面的代码:
import operator
import bayes
import generate_attrs
def main():
#生成测试数据集
test_datasets=generate_attrs.gen_attrs()
#建立分类器
classfier=bayes.naive_bayes_classifier()
for data in test_datasets:
print('特征值:',end='\t')
print(data)
print('预测结果:',end='\t')
res=classfier.get_label(*data)
print(res)
print('水果类别:',end='\t')
#对后验概率排序,输出概率最大的标签
print(sorted(res.items(),key=operator.itemgetter(1),reverse=True)[0][0])
#导入该模块,并自动运行main函数
if __name__=='__main__':
main()输出结果如下:
特征值: ['long','sweet', 'yellow']
预测结果: {'other_fruit':0.006490384615384616, 'banana': 0.08723076923076924, 'orange': 0.0}
水果类别: banana
特征值: ['long','not_sweet', 'not_yellow']
预测结果: {'other_fruit':0.04821428571428571, 'banana': 0.03085714285714286, 'orange': 0.0}
水果类别: other_fruit
特征值: ['not_long','sweet', 'not_yellow']
预测结果: {'other_fruit':0.07788461538461539, 'banana': 0.009692307692307695, 'orange': 0.0}
水果类别: other_fruit
特征值: ['not_long','not_sweet', 'yellow']
预测结果: {'other_fruit':0.0040178571428571425, 'banana': 0.01735714285714286, 'orange':0.09642857142857142}
水果类别: orange
特征值: ['long','not_sweet', 'not_yellow']
预测结果: {'other_fruit':0.04821428571428571, 'banana': 0.03085714285714286, 'orange': 0.0}
水果类别: other_fruit
特征值: ['not_long','sweet', 'yellow']
预测结果: {'other_fruit':0.006490384615384616, 'banana': 0.02180769230769231, 'orange':0.051923076923076926}
水果类别: orange
特征值: ['long','not_sweet', 'not_yellow']
预测结果: {'other_fruit':0.04821428571428571, 'banana': 0.03085714285714286, 'orange': 0.0}
水果类别: other_fruit
特征值: ['not_long','not_sweet', 'yellow']
预测结果: {'other_fruit':0.0040178571428571425, 'banana': 0.01735714285714286, 'orange':0.09642857142857142}
水果类别: orange
特征值: ['long','not_sweet', 'not_yellow']
预测结果: {'other_fruit':0.04821428571428571, 'banana': 0.03085714285714286, 'orange': 0.0}
水果类别: other_fruit
特征值: ['long','not_sweet', 'yellow']
预测结果: {'other_fruit':0.0040178571428571425, 'banana': 0.06942857142857144, 'orange': 0.0}
水果类别: banana
特征值: ['not_long','not_sweet', 'yellow']
预测结果: {'other_fruit':0.0040178571428571425, 'banana': 0.01735714285714286, 'orange':0.09642857142857142}
水果类别: orange
特征值: ['long','not_sweet', 'not_yellow']
预测结果: {'other_fruit':0.04821428571428571, 'banana': 0.03085714285714286, 'orange': 0.0}
水果类别: other_fruit
特征值: ['long','sweet', 'yellow']
预测结果: {'other_fruit':0.006490384615384616, 'banana': 0.08723076923076924, 'orange': 0.0}
水果类别: banana
特征值: ['long','not_sweet', 'yellow']
预测结果: {'other_fruit':0.0040178571428571425, 'banana': 0.06942857142857144, 'orange': 0.0}
水果类别: banana
特征值: ['not_long','sweet', 'yellow']
预测结果: {'other_fruit':0.006490384615384616, 'banana': 0.02180769230769231, 'orange':0.051923076923076926}
水果类别: orange
特征值: ['not_long','not_sweet', 'yellow']
预测结果: {'other_fruit':0.0040178571428571425, 'banana': 0.01735714285714286, 'orange':0.09642857142857142}
水果类别: orange
特征值: ['long','sweet', 'not_yellow']
预测结果: {'other_fruit':0.07788461538461539, 'banana': 0.03876923076923078, 'orange': 0.0}
水果类别: other_fruit
特征值: ['long','sweet', 'not_yellow']
预测结果: {'other_fruit':0.07788461538461539, 'banana': 0.03876923076923078, 'orange': 0.0}
水果类别: other_fruit
特征值: ['not_long','not_sweet', 'not_yellow']
预测结果: {'other_fruit':0.04821428571428571, 'banana': 0.007714285714285715, 'orange': 0.0}
水果类别: other_fruit
特征值: ['not_long','not_sweet', 'not_yellow']
预测结果: {'other_fruit':0.04821428571428571, 'banana': 0.007714285714285715, 'orange': 0.0}
水果类别: other_fruit本节假设读者具备基本的概率知识,如果觉得学习有困难,可以去补习一下概率论方面的基础知识。这里建议读者去选择别的问题实现一个bayes分类器,加深对知识的理解。
以上内容选自《Python数据分析从入门到精通》。如何通过贝叶斯分类器实现协同推荐系统?想要了解更多的Python数据技术吗?可以点击阅读原文来订购哦。
内容简介
对于希望使用Python来完成数据分析工作的人来说,学习IPython、Numpy、pandas、Matplotlib这个组合是目前看来不错的方向。《Python数据分析从入门到精通》就是这样一本循序渐进的书。
《Python数据分析从入门到精通》共3篇14章。第1篇是Python数据分析语法入门,将数据分析用到的一些语言的语法基础讲解清楚,为接下来的数据分析做铺垫。第2篇是Python数据分析工具入门,介绍了Python数据分析“四剑客”——IPython、Numpy、pandas、Matplotlib。第3篇是Python数据分析案例实战,包括两个案例,分别是数据挖掘和玩转大数据,为读者能真正使用Python进行数据分析奠定基础。
《Python数据分析从入门到精通》内容精练、重点突出、实例丰富,是广大数据分析工作者必备的参考书,同时也非常适合大、中专院校师生学习阅读,还可作为高等院校统计分析及相关专业的教材。
福利来了
本次拿出 6 本书作为福利赠送给关注【Python那些事】的小伙伴们,特别感谢电子工业出版社的赞助与支持。点击 阅读原文 即可订购哦。
赠书规则:
2、大家可以在本留言区留言评论自己想要这本书的理由或者是评论某项Python技术,小编将从留言区选择最受欢迎的2位赠书;
3、我将从本文留言中选择我最喜欢的2个留言赠书,大家可以自由发挥;
由于留言区数目有限,会筛选放出认真有价值的评论(刷赞无效,并且会永久取消资格,欢迎举报)。截止日期为3月29日 22:00。
(完)
看完本文有收获?请转发分享给更多人
关注「Python那些事」,做全栈开发工程师
以上是关于免费赠书贝叶斯分类器的实现的主要内容,如果未能解决你的问题,请参考以下文章