小知识:什么是贝叶斯分类器
Posted 轨道车辆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小知识:什么是贝叶斯分类器相关的知识,希望对你有一定的参考价值。



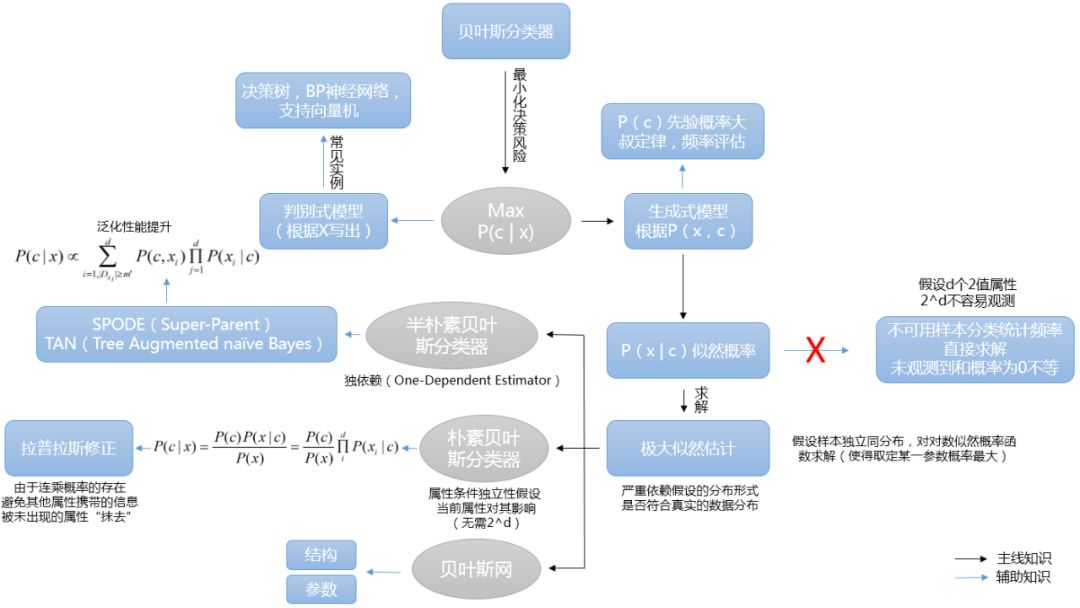
贝叶斯决策论通过相关概率已知的情况下利用误判损失来选择最优的类别分类。
“风险”(误判损失)= 原本为cj的样本误分类成ci产生的期望损失(如下式,概率乘以损失为期望损失)
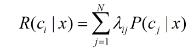
为了最小化总体风险,只需在每个样本上选择能够使条件风险R(c|x)最小的类别标记。
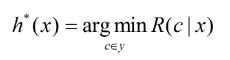
h*称为贝叶斯最优分类器,与之对应的总体风险为贝叶斯风险,另lambda等于1时,最优贝叶斯分类器是使后验概率P(c|x)最大。
利用贝叶斯判定准则来最小化决策风险,首先要获得后验概率P(c|x),机器学习则是基于有限的训练样本集尽可能准确的估计出后验概率P(c|x)。通常有两种模型:1.“判别式模型”: 通过直接建模P(c|x)来预测(决策树,BP神经网络,支持向量机)。2.“生成式模型”:通过对联合概率模型P(x,c)进行建模,然后再获得P(c|x)。
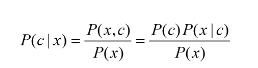
P(c)是类“先验”概率,P(x|c)是样本x相对于类标记条件概率,或称似然。似然函数定义(对同一个似然函数,如果存在一个参数值,使得它的函数值达到最大的话,那么这个值就是最为“合理”的参数值。
对于P(c)而言代表样本空间中各类样本所占的比例,根据大数定理当训练集包含充足的独立同分布样本时,可通过各类样本出现的频率进行估计。对于P(x|c)而言,涉及关于所有属性的联合概率,无法根据样本出现的频率进行估计。
极大似然估计
假设P(x|c)具有确定的形式并且被参数向量唯一确定,则我们的任务是利用训练集估计参数Qc,将P(x|c)记为P(x|Qc)。令Dc表示训练集D第c类样本的集合,假设样本独立同分布,则参数Qc对于数据集Dc的似然是
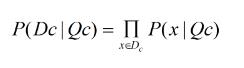
连乘容易造成下溢,通常使用对数似然
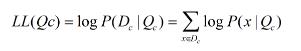
注意。这种参数化的方法虽然能使类条件概率估计变得相对简单,但是估计结果的准确性严重依赖所假设的概率分布形式是否符合潜在的真实数据分布。有限的数据集合难以直接估计其联合概率分布。故此我们提出朴素贝叶斯分类器。
为了避开联合概率分布这一障碍,朴素贝叶斯分类器采用了“属性条件独立性假设”:对已知类别,假设所有属性相互独立。
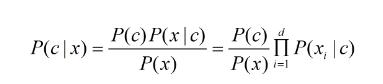
若存在某个属性值在训练的过程中没有与某个类同时出现过,直接利用式子进行概率估计将会出错。因为会存在某一属性为概率0,导致无论其他属性多好都将为零。为了避免上述产生的将某种未出现的属性值抹去,在估计概率时可进行“平滑”(smoothing),常用“拉普拉斯修正”。具体来说可以令N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值数。
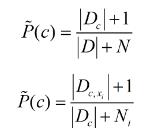
拉普拉斯修正避免了因训练集样本不充分而导致概率估值为零的问题,并且在训练集变大时,修正过程所引入的先验(prior)的影响也会逐渐变得可忽略,使得估值逐渐趋于实际的概率值。
在现实任务中朴素贝叶斯分类器有很多种使用方式。对预测速度要求较高的,将所有概率的估计值事先计算好存储起来,这样在进行预测是只需要查表就可以进行判别。若任务数据更替频繁,则可采用懒惰学习(lazy learning),收到数据进行概率估计,若数据不断增加,则可在现有的估值基础上,仅对新增样本属性值所涉及的概率估值进行技术修正即可实现增量学习。
朴素贝叶斯分类器采用属性完全独立的假设,在现实生活中通常难以成立,对属性条件独立性假设进行一定程度的放松,由此产生一类“半朴素被夜色分类器”(semi-naive Bayes classifiers)的学习方法,不需要进行完全联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。
“独依赖估计”(One dependent Estimator, ODE),假设每个属性在类别之外最多依赖一个其他的属性。
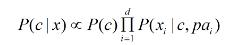
pai为属性xi所依赖的属性,称为xi的父属性。若对每个属性xi,其父属性已知,则可用类似如下的方法进行估计概率
因此我们将问题转化成确定每个属性的父属性。1. SPODE:确认一个超父属性,其余属性都依赖该属性。2.TAN(最大带全生成树)
以上部分图片及内容来源于网络。
以上是关于小知识:什么是贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章