金融数据挖掘之朴素贝叶斯
Posted 大数据实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了金融数据挖掘之朴素贝叶斯相关的知识,希望对你有一定的参考价值。
你和我之前的人生,
就像是来自同一个分布族的共轭曲线,
即使有各自的参数空间,
也注定要相识相念。
你和我之后的人生,
是我们相扶相持下不离不弃的最大似然,
用“信任与珍惜”的先验去修正所有后验,
用“包容和分享”的样本去做无悔一生的推断。
这是朴素的贝叶斯思想,
也是我们朴素的爱情宣言。
一、贝叶斯的故事
“托马斯.贝叶斯……这个生性孤僻,哲学气味重于数学气味的学术怪杰,以其一篇遗作的思想重大地影响了两个世纪以后的统计学术界,顶住了统计学的半边天”。
——中国科学院院士陈希孺
托马斯·贝叶斯(ReverendThomas Bayes, 1702-1761)是对归纳推理给出精确定量表达方式的第一人,他死后发表的论文,可以作为科学史上最著名的论文之一(Press,1989:P181)。
40岁当选英国皇家学会会员,相当于今天的英国科学院院士。
即使这样,他在18世纪上半叶欧洲学术界也不算一个起眼的人物。在他生前,没有片纸只字的科学论著发表。那时,传播和交流科学成果的一种方式,是学者间的私人通信。这些信件许多都得以保存下来并发表传世。
他最伟大的论文《机遇理论中一个问题的解》,在他死后第三年才发表,1764年被发表在伦敦皇家学会的《Philosophical Transactions》上。
贝叶斯开创了统计学的贝叶斯学派,用先验知识和逻辑推理来处理不确定命题,与古老的频率学派分庭抗礼,频率学派只从数据中获得信息,完全不考虑先验知识,即人的经验。
二、贝叶斯定理
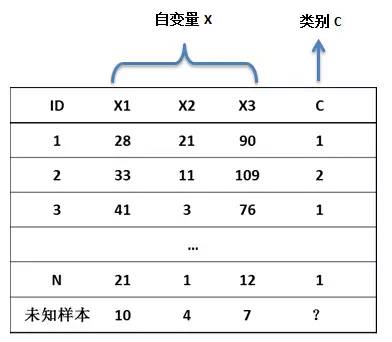
如果想判断未知样本的类别,即,已知它的三个属性X1、X2、X3,判断它是属于第一类(C=1)还是第二类(C=2),前面有介绍过如何用Knn邻均值和决策树来判断分类,本文介绍用这种新的思路:
P(C=1|X1,X2,X3)>P(C=2|X1,X2,X3),给定数据的X1、X2、X3后,数据属于类别1的概率要大于属于类别2,即说明现有样本支持未知样本属于类别1,判定为类别1。
P(C=1|X1,X2,X3)<P(C=2|X1,X2,X3),则说明现有样本支持未知样本属于类别2,判定为类别2。
如何得到
P(C=1|X1,X2,X3)
P(C=2|X1,X2,X3)
这两个概率呢?答案是——得不到。但是没关系,因为,只要知道这两个谁大谁小就可以进行判断:
P(C=1|X1,X2,X3)>P(C=2|X1,X2,X3),则判定类别为1;
P(C=1|X1,X2,X3)<P(C=2|X1,X2,X3),则判定类别为2;
贝叶斯定理就提供了方法进行这种比较。
1. 贝叶斯定理
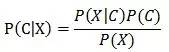
P(C|X)是给定属性X下,C的后验概率,P(C)是C的先验概率,该公式被称为“贝叶斯定理”。根据贝叶斯定理,我们想找出最大的P(C|X),由于P(X)对所有类为常数,只要找出最大的P(X|C)P(C)即可,这便是朴素贝叶斯分类的基础。
2. 朴素贝叶斯分类
利用贝叶斯定理,找出最大的P(X|C)P(C)即可对未知样本进行分类,如max{P(X|C)P(C)}=P(X|C=n)P(C=n),则说明未知样本属于第n类,其中,
(1)P(C=i)=Si/S,Si是类Ci中的训练样本数,S是训练样本总数;
(2)P(X|C=i)的计算开销可能非常大,因为会涉及到很多属性变量,这里可以做“属性值互相条件独立”的假定,即属性间不存在依赖关系:
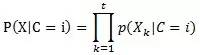
即,如果用三个属性值X1、X2、X3,来推测类别C,那么有:
P(X1,X2,X3|C=i)= P(X1|C=i)*P(X1|C=i)*P(X1|C=i)
这一假定是为了简化所需计算,也因此该算法被冠以“朴素的”定语。
(3)要注意的是,在计算P(Xk|C=i)时,要看Xk是分类属性还是连续属性:
如果Xk是分类属性,则
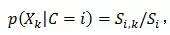 ,
,
比如 即在类别C=1的样本中,X1占的比例;
如果Xk是连续属性,则通常做正态分布假定:
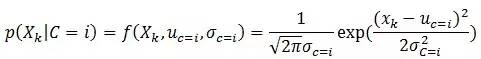
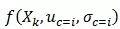 是属性Xk的密度函数,
是属性Xk的密度函数,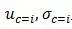 为平均值和标准差。
为平均值和标准差。
朴素贝叶斯分类模型,与前面介绍的决策树一样被用于分类。它发源于贝叶斯定理,有着坚实的数学基础和稳定的分类效率,但受制于一些假定的不准确性(如类条件独立),以及缺乏可用的概率数据,该算法的准确率可能没有理论表现的那么美好。然而,它的计算量比第一集中的Knn要小很多,其简单的算法又可以与第二集介绍的决策树和以后要接受的神经网络相媲美,是使用最广泛的分类模型之一。
三、金融应用实例
1. 选股
复旦大学的钱颖能、胡运发用朴素贝叶斯分类法进行选股,在给定上海证券交易所中所有交易的股票的基本会计和价格信息的情况下,他们试图用朴素贝叶斯法来辨别那些超过市场指数而可望获得额外汇报的股票。由朴素贝叶斯法选择的股票所组成的同等权重证券组合1年半内总共获得21%的回报,明显优于市场指数的-9%的回报。
2. 反洗钱
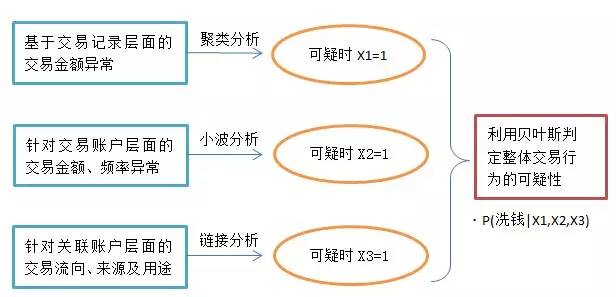
西安交通大学的张成虎、赵小虎(2009)利用朴素贝叶斯分类来识别可疑金融交易,发现洗钱行为。在他们的论文“基于贝叶斯分类的可疑金融交易识别研究”中提到,从反洗钱检测实践来看,可疑金融交易行为主要有以下几类特征:
(1) 交易金额、交易频率的异常。
如短期内发生资金收付行为,长期闲置的账户不明原因突然启用等。
(2) 交易流向、交易来源的异常。
如与来自贩毒、走私、恐怖活动、赌博严重的地区或者避税型离岸中心客户之间的资金往来活动在短期内增多;多个境内居民接受一个离岸账户汇款等。
(3) 交易用途或交易性质异常。
如没有正常原因的多头开户、销户,且销户前发生大量资金收付;保险机构通过银行频繁大量对同一家投保人发生赔付或者办理退保等。
论文中他们先用聚类分析、小波分析、链接分析来分别对以上几种可疑行为进行识别,并对识别有问题的交易行为标注为1,在利用贝叶斯来对整个交易行为进行判定。
四、软件实现
本文主要介绍Python和MATLAB的实现思想,仅以分类变量为例:
1. PYTHON
如果现在有已知数据data:

分类向量c_value=[“yes”,”no”]两类,未知数据test:
test={"outlook":"sunny","temp":"cool","humidity":"high","wind":"strong"}
那么如何在python中实现对未知样本test的朴素贝叶斯分类呢?主要需要三段代码:

2. MATLAB
Matlab最好先把分类变量值以字符串形式转变为数字形式,在上个例子中,
outlook有三个分类:sunny、overcast、rain,分别赋值为1、2、3;
temp有三个分类:hot、mild、cool,分别赋值为1、2、3;
humidity有两个分类:high、normal,分别赋值为1、2;
wind有两个分类:strong、weak,分别赋值为1、2;
class有两个分类:yes、no,分别赋值为1、2;
data = [
1 1 1 2 2;
1 1 1 1 2;
2 1 1 2 1;
3 2 1 2 1;
3 3 2 2 1;
3 3 2 1 2;
2 3 2 1 1;
1 2 1 2 2;
1 3 2 2 1;
3 2 2 2 1;
1 2 2 1 1;
2 2 1 1 1;
2 1 2 2 1;
3 2 1 1 2;
]
我们把Python实现思想转化成MATLAB形式:
function p =p(data,c_id,c_value) count=0.0; for i=1:size(data,1) if data(i,c_id)==c_value count=count+1; end end p=count/size(data,1) end |
function pp=pp(data,c_id,c_value,a_id,a_value) count1=0.0; count2=0.0; for l=1:size(data,1) if data(l,c_id)==c_value count1=count1+1; if data(l,a_id)==a_value count2=count2+1; end end end pp=count2/count1; end |
function nb(data,test,c_id,c_value) pv=0*c_value for i=1:size(c_value,2) pv(1,i)=p(data,c_id,c_value(1,i)); end for i=1:size(c_value,2) for j=1:size(test,2) pv(1,i)=pv(1,i)*pp(data,c_id,c_value(1,i),j,test(1,j)); end end pv end |
(来源:数说工作室 )
以上是关于金融数据挖掘之朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章