朴素贝叶斯应用之识别手写数字
Posted 清醒行走
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯应用之识别手写数字相关的知识,希望对你有一定的参考价值。
引言
我们都见过或者用过的一个东西就是输入法的手写键盘,如下面的动图所示,那么输入法是如何识别出我们手写的字迹是什么字的呢?这是一个对人而言非常简单(前提是你写的字体不过于潦草),但是对于程序而言,可能就没有那么简单了,这次我就从一个更简单的角度来试一下,如何去识别手写的数字。
朴素贝叶斯
我们在前面的文章中提到了,公式表示如下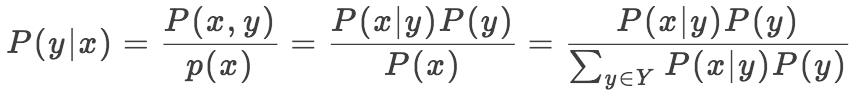
并从中得出了这样的结论:
贝叶斯定理可以精确的说明在已知新证据 x 的情况下,我们应该改变多少关于 y 的信念,这个等式中,P(y) 是新证据 x 出现之前我对于 y 的先验信念。 P(x | y) 是在 y 确定的前提下,得到证据 x 的可能性。 P(y|x) 是在考虑新证据后我对于 y 的后验信念。
而朴素贝叶斯(Naive Bayes)法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布,然后基于学习到模型,对于新的输入 x ,利用贝叶斯定理求出后验概率最大的输出 y ,朴素贝叶斯法实现简单,学习和预测的效率也非常高,是一种很常用的分类方法。
朴素贝叶斯法的学习与分类
朴素贝叶斯法如何用于分类工作呢?这里用更加数学的语言,可以表述如下:
首先设输入空间 为 n 维向量的集合,输出空间为类标记集合
为 n 维向量的集合,输出空间为类标记集合 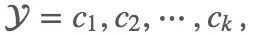 ,其中输入为特征向量 x∈,输出为类标记(class label) y∈ .则 P(X, Y) 是 X 和 Y 的联合概率分布.
,其中输入为特征向量 x∈,输出为类标记(class label) y∈ .则 P(X, Y) 是 X 和 Y 的联合概率分布.
其次训练数据集表示为: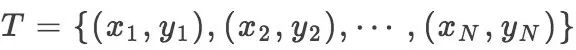
由 P(X, Y) 独立同分布产生.
最后由朴素贝叶斯法通过上述训练数据集学习到联合概率分布 P(X, Y) ,由条件概率公式可以知道只需要学习到如下的先验概率分布: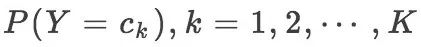
以及条件概率分布: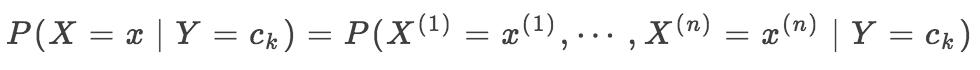
二者相乘即可得到联合概率分布。
但是,事实上,从我们学到的条件概率分布的知识可以知道,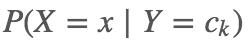 是一个具有指数级数量的参数,一旦训练集稍微具有规模,那么这个概率分布都是无法估计的。而机器学习中,训练集的规模化显然是不可避免的。
是一个具有指数级数量的参数,一旦训练集稍微具有规模,那么这个概率分布都是无法估计的。而机器学习中,训练集的规模化显然是不可避免的。
那么现在我们明显已经知道通过学习上述两个概率分布,可以得到我们想要的联合概率分布,从而得到训练模型,然而其中条件概率分布计算的不可行性却让我们止步不前。
在这样一个尴尬的时候,朴素贝叶斯法站出来为我们解围了,它提出了一个非常强的假设,就是假设条件概率分布是特征条件独立的,因此朴素贝叶斯,也就朴素在这里:他的假设太强,强到改变了理论上计算的规则。
具体的,条件独立性假设是:
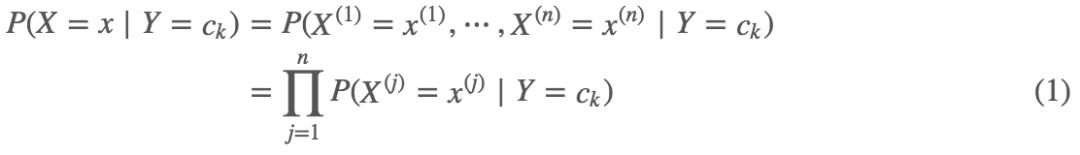
这个假设等于是说用于分类的特征在类别确定的条件下都是条件独立的,这一假设使得条件概率的计算变得异常简单,但是显然也牺牲了一定的准确率,因为一般情况下特征并不都是独立的而是有关联的。
通过上述学习到模型,就可以计算后验概率分布 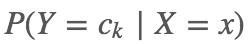 ,将后验概率最大的类别作为要预测的样本 x 的输出。后验概率的计算依据贝叶斯定理进行:
,将后验概率最大的类别作为要预测的样本 x 的输出。后验概率的计算依据贝叶斯定理进行:
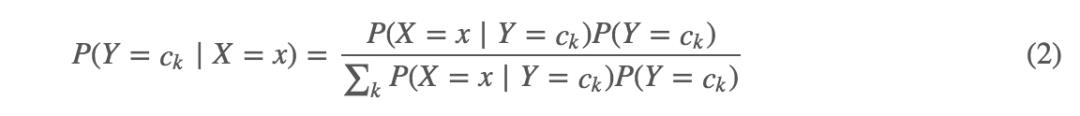
将 2 式代入 1 式,得到:
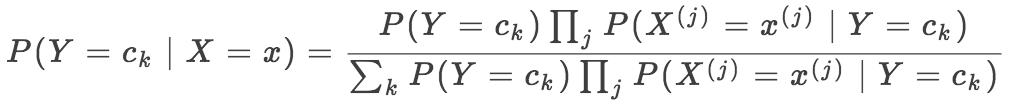
所以,贝叶斯分类器可以表示为:
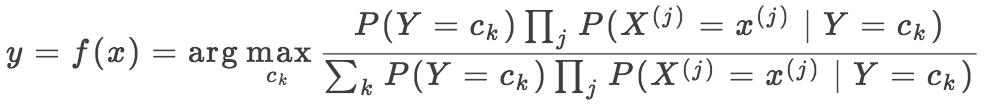
上式因为分母对所有 Ck 都是相同的,所以:
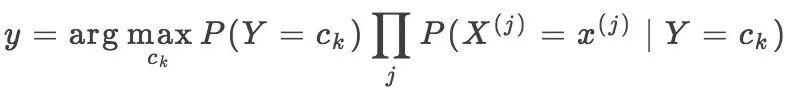
这就是朴素贝叶斯分类器的最简形式,从这个式子可以看出来,朴素贝叶斯分类器本质上是根据先验概率及条件概率求最大化的后验概率,从而推断类别。
朴素贝叶斯法的参数估计
极大似然估计
在上面所说的朴素贝叶斯法中,训练学习意味着估计先验概率 P(Y = Ck) 和条件概率 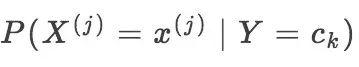 ,这可以应用极大似然估计来估计相应的概率,其中先验概率的极大似然估计是:
,这可以应用极大似然估计来估计相应的概率,其中先验概率的极大似然估计是:
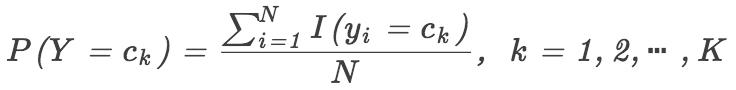
设第 j 个特征
xj 可能的取值的集合为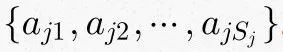 ,则条件概率的极大似然估计为:
,则条件概率的极大似然估计为:
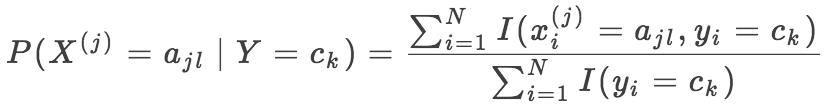
其中 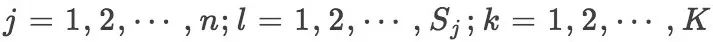 ,且
,且 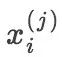 表示第 i 个样本的第 j 个特征;
表示第 i 个样本的第 j 个特征;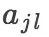 是第 j 个特征可能取的第 l 个值;I 是指示函数
是第 j 个特征可能取的第 l 个值;I 是指示函数
贝叶斯估计
因为用极大似然估计可能会出现所要估计的概率值为 0 的情况,这就会导致后续的计算出现错误,使得分类出现偏差,解决这个问题的方法就是使用贝叶斯估计,即是平滑处理估计结果,条件概率的贝叶斯估计是: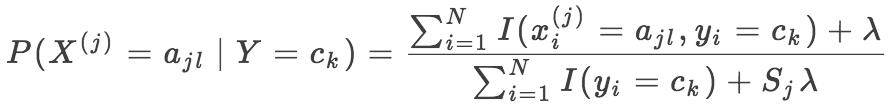
其中 λ≥0,等价于给随机变量的各个取值的频数加上一个正数 λ>0常取 λ=1,称为拉普拉斯平滑。
实战朴素贝叶斯
有了上面的基础,那么处理手写数字识别上面就变得很简单了,整个处理的步骤分为:
图片预处理
图片数据化
模型训练
模型测试
图片预处理
这里我们取现成的 mnist 数据集 [2] ,首先数据集下载下来的是特殊格式的压缩包,其中训练集的图片包和标签包格式如下:

可以看出在 train-images.idx3-ubyte 中,第一个数为 32 位的整数(魔数,图片类型的数),第二个数为32位的整数(图片的个数),第三和第四个也是 32 位的整数(分别代表图片的行数和列数),接下来的都是一个字节的无符号数(即像素,值域为0~255),因此,我们只需要依次获取魔数和图片的个数,然后获取图片的长和宽,最后逐个按照图片大小的像素读取就可以得到一张张的图片内容了。标签数据集及测试数据集的的数据读取都是一样的原理。
读取训练图片集并将图片存储成图片,读取标签集的代码实现代码如下:
1# -*- coding: utf-8 -*-
2
3from PIL import Image
4import struct
5
6
7def read_image(filename):
8 f = open(filename, 'rb')
9 index = 0
10 buf = f.read()
11 f.close()
12 // 开始读取 魔数、图片数目、图片行数、列数
13 magic, images, rows, columns = struct.unpack_from('>IIII', buf, index)
14 index += struct.calcsize('>IIII')
15 for i in range(images):
16 # 逐个读取图片,每个图片字节数为 行数X列数
17 image = Image.new('L', (columns, rows))
18 for x in range(rows):
19 for y in range(columns):
20 # 读取并填充图片的像素值,每个像素值为一个字节
21 image.putpixel((y, x), int(struct.unpack_from('>B', buf, index)[0]))
22 index += struct.calcsize('>B')
23 print('save ' + str(i) + 'image')
24 image.save('train/' + str(i) + '.png')
25
26def read_label(filename, saveFilename):
27 f = open(filename, 'rb')
28 index = 0
29 buf = f.read()
30 f.close()
31 # 开始读取 魔数及标签数目
32 magic, labels = struct.unpack_from('>II', buf, index)
33 index += struct.calcsize('>II')
34 labelArr = [0] * labels
35 for x in range(labels):
36 # 一个标签一个字节
37 labelArr[x] = int(struct.unpack_from('>B', buf, index)[0])
38 index += struct.calcsize('>B')
39 save = open(saveFilename, 'w')
40 save.write(','.join([str(x) for x in labelArr]))
41 save.write('\n')
42 save.close()
43 print('save labels success')
44 return labelArr
45
46
47if __name__ == '__main__':
48 read_image('train-images.idx3-ubyte')
49 read_label('train-labels.idx1-ubyte', 'train/label.txt')
读取到图片之后,存储的结果如下:

图片数据化
为了将图片变成更易为计算机接受的形式,这里需要将图片二值化,即是只包含0和1的图片表现形式,即是下面这样的矩阵,其方法是超过一定像素值的点标记为 1,否则为 0:

可以隐约看出一个 5 的形状。
这里为了方便继续处理图片特征,将这个 28 *28 的矩阵进行 reshape 操作,将一幅图展开为行向量。因此整个训练集()60000张图片)就变成了一个大小为 60000×784 的矩阵,之后尽量进行矩阵操作。
同时为了方便标记,将每行向量表示的数字写在最后一列,因此整个矩阵的大小为 60000×785。
并为了后续数据操作的方便,将这个矩阵存在本地的CSV文件中,代码及结果如下:
1N = 28
2def get_train_set():
3 f = open('data.csv', 'wb')
4 category = MR.read_label('train-labels.idx1-ubyte', 'train/label.txt')
5
6 file_names = os.listdir(r"./train/", )
7 train_picture = np.zeros([len(file_names)-1, N ** 2 + 1])
8 # 遍历文件,转为向量存储
9 for file in range(len(file_names)-1):
10 img_num = io.imread('./train/%d.png' % (file))
11 rows, cols = img_num.shape
12 for i in range(rows):
13 for j in range(cols):
14 if img_num[i, j] < 100:
15 img_num[i, j] = 0
16 else:
17 img_num[i, j] = 1
18 train_picture[file, 0:N ** 2] = img_num.reshape(N ** 2)
19 train_picture[file, N ** 2] = category[file]
20 print("完成处理第%d张图片" % (file+1))
21 np.savetxt(f,train_picture,fmt='%d',delimiter=',', newline='\n', header='', footer='')
22 f.close()
23 time_e = time.time()
24 print('process data train cost ', time_e - time_0, ' seconds', '\n')
25 return train_picture
结果如下,红色框内即是该行向量的标签:

处理测试数据也是一样的原理。
模型训练
从第一部分我们可以了解到,要求后验概率的本质是求在类别为 j 的条件下,样本 x 的第 i 个特征出现的条件概率的,将所有特征的概率与该类别的先验概率作连乘即得到后验概率。
因此,重点是计算类别的先验概率和在类别为 j 的条件下,样本 x 的第 i 个特征出现的条件概率,这也就是我们要训练的模型,代码如下:
1def Train():
2 conditional_probability = np.zeros((class_num, feature_len, 2)) # 条件概率
3
4 # 计算先验概率及条件概率
5 for i in range(len(labels)):
6 img = data_map[i, :]
7 label = labels[i]
8 for j in range(feature_len):
9 conditional_probability[label][j][img[j]] += 1
10
11 # 将概率归到[1.1001]
12 for i in range(class_num):
13 for j in range(feature_len):
14
15 # 经过二值化后图像只有0,1两种取值
16 pix_0 = conditional_probability[i][j][0]
17 pix_1 = conditional_probability[i][j][1]
18
19 # 计算0,1像素点对应的条件概率
20 probalility_0 = (float(pix_0)/float(pix_0+pix_1))*1000 + 1
21 probalility_1 = (float(pix_1)/float(pix_0+pix_1))*1000 + 1
22
23 conditional_probability[i][j][0] = probalility_0
24 conditional_probability[i][j][1] = probalility_1
25
26 return conditional_probability
其中部分说明如下:
由于 Python 浮点数精度的原因,784个浮点数联乘后结果变为 Inf,而 Python 中 int 可以无限相乘的,因此可以利用python int 数据类型的特性对先验概率与条件概率进行一些改造。
先验概率: 由于先验概率分母都是 N,因此不用除于 N,直接用分子即可。
条件概率: 条件概率公式如上说明济代码所示,我们得到概率后再乘以1000000 (最小的可能性为1/784,同时需要尽量保存概率精度,这里保存到白万分之一,因此乘以1000000),将概率映射到[0,1000000]中,但是为防止出现概率值为0的情况,人为的加上1,使概率映射到[1,1000001]中。^3
模型预测
模型预测的方法就是根据上面训练出来的朴素贝叶斯模型,对任一个新的样本 x ,分别计算它是类别 j 的条件下的后验概率,取最大后验概率的类别即可。
代码如下:
1# 计算概率
2def calculate_probability(img, label):
3 probability = int(prior_probability[label])
4
5 for i in range(len(img)):
6 probability *= int(conditional_probability[label][i][img[i]])
7
8 return probability
9
10def Predict(testset, test_labels):
11 predict = []
12 accuracy = []
13 right = 0
14 rows, cols = testset.shape
15 for row in range(rows):
16 # 图像二值化
17 img = testset[row, :]
18
19 max_label = 0
20 max_probability = calculate_probability(img, 0)
21
22 for j in range(1, 10):
23 probability = calculate_probability(img, j)
24
25 if max_probability < probability:
26 max_label = j
27 max_probability = probability
28 predict.append(max_label)
29 if max_label == test_labels[row]:
30 right += 1
31 if (row+1) % 500 == 0:
32 accuracy.append(float(right)/(row+1))
33 return float(right)/len(test_labels), np.array(predict), accuracy
整个代码运行的结果如下:
准确率曲线如下:
其他说明
本次实验将图像展开、对单个像素独立判断,损失了图像的空间信息,而这种空间信息正是我们人眼识别图像的关键。所以最终的准确率受此影响。
测试数据的准确率为84.47%,还是非常不错的(共有10个分类,理论上随机猜测的准确率只有10%)。能使准确率达到84.15%的原因主要是:(1) MNIST数据集被预先处理过。通过上面的示例图片可以看出,MNIST中的图片较为纯净,没有噪声干扰,非常清晰。所以实验中可以直接进行二值化。(2) MNIST数据集中,图片中的数字总是在中心位置,大小合适,比较饱满。这一点保留了部分的空间信息。
本例中的二值化过程是直接将超过一定像素阀值值置1,如果采用更合理的阈值(比如取当前图片最大像素阀值为 100 )进行二值化操作,进行训练、测试过程,最终的准确率可能会提升。 ^4
以上就是这次朴素贝叶斯法的理论及实战啦。
NEXT
下次是 K 近邻算法在手写识别上的应用。
Reference
1. 李航《统计学习方法》第四章
2. THE MNIST DATABASE
获得更佳阅读体验,点击阅读原文进入博客~
以上是关于朴素贝叶斯应用之识别手写数字的主要内容,如果未能解决你的问题,请参考以下文章