R语言:朴素贝叶斯算法实现对中文垃圾邮件的分类
Posted 数据老黄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言:朴素贝叶斯算法实现对中文垃圾邮件的分类相关的知识,希望对你有一定的参考价值。
本期主要是实操在
R语言中如何使用朴素贝叶斯算法实现对中文垃圾邮件的分类,并尝试优化模型分类效果。本文中所用到的数据均为真实的中文邮件文本数据,因此整个过程十分贴近真实的操作场景,能够帮助我们更深入的理解和掌握在R语言中如何进行中文文本处理和如何使用朴素贝叶斯算法进行分类。关于算法原理本文将不作介绍,需要了解的同学可以百度一下,网上有许多非常深入和详细解读。
数据基本情况
在开始进行文本分类之前我们需要了解一下数据的基本情况以便我们理清数据处理的思路,这是非常重要的一步,对数据结构有了清晰的认识才能够事半功倍。数据获取:https://trec.nist.gov/data/spam.html,下载2006垃圾邮件语料库,其中的trec06c文件为本文中使用的数据
首先,我们导入一份邮件,来看看这份数据文件内的中文邮件长什么样子。
setwd("~/Desktop/R/python/email/trec06c")
email_exm <- read.table("data/001/005",fill=TRUE,fileEncoding = "GB18030",sep = "|")
该文件内包含了一份邮件所应该的全部信息,然而我们实际需要的只是其中邮件的正文部分,其他的信息都是基本用不到,是要被清理掉的,这其中主要是一些英文字符、特殊符号以及数字。另外,为了方便后续对中文文本进行分词的处理,我们需要将读入多行的数据合并成一行。
粗略阅读该邮件的内容,发现这是一份翻译公司的推销邮件, 显然这是一份垃圾邮件。full文件夹中的index文件中标记了邮件是否为垃圾邮件,我们将index文件导入,查看一下这份数据的结构。
library(dplyr)
email_class_full <- read.table("full/index",fill=TRUE,fileEncoding = "GB18030",col.names = c("type","path"))
str(email_class_full)
prop.table(table(email_class_full$type))
head(email_class_full)
filter(email_class_full,path == "../data/001/005")
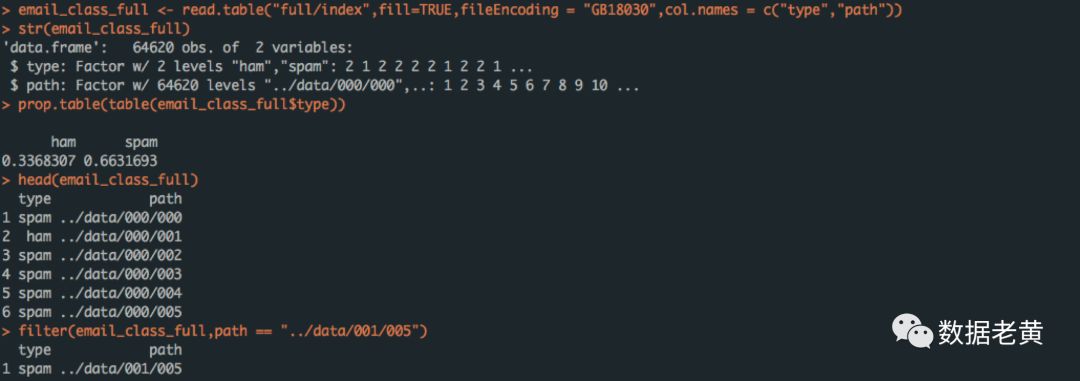
index文件包含了所有邮件的文件路径以及邮件的是否为垃圾邮件,一共64620行数据,即64620份邮件,其中非垃圾邮件占比为33.68%,垃圾邮件占比66.32%;另外我们查看了data/001/005的类型,为spam,其的确为垃圾邮件。后续的数据处理中我们将随机抽取其中的10000份邮件,通过index中的文件路径将抽样的文本导入。
文本数据导入
library(dplyr)
library(plyr)
library(stringr)
#随机抽取10000条数据
email_class_full <- email_class_full[sample(1:length(email_class_full$type),size=10000),]
#准备for循环中用到的变量
warn_path = c()
emails = c()
num <- length(email_class_full$type)
#逐一读入文件
for(i in 1:num){
#截取邮件的文件路径
path <- str_sub(email_class_full[i,2],4)
#个别邮件包含无法识别的特殊字符无法读入,将其抓取出来
warn <-tryCatch(
{text <- read.table(path,fill=TRUE,fileEncoding = "GB18030",colClasses ="character",sep = "|")},
warning = function(w){"warning"}
)
if(warn == "warning"){ warn_path <- c(warn_path,as.character(email_class_full[i,2]))}
#去除文本中的英文字符、特殊字符
arrange_text <- gsub("[a-zA-Z]","",as.character(warn)) %>%
gsub('[\\(\\.\\\\)-<\n-=@\\>?_]',"",.)
#将处理后的文本保存
emails <- c(emails,arrange_text)
}
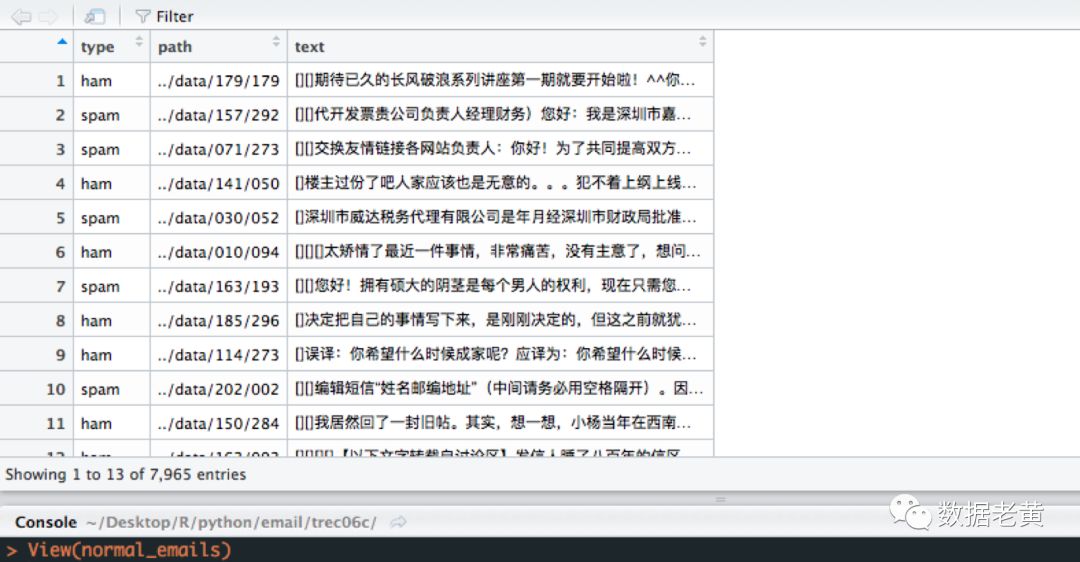
normal_emails <- mutate(email_class_full,text = emails,type = factor(type)) %>% filter(.,text !="")
warn_emails <- mutate(email_class_full,text = emails) %>% filter(.,text =="")
随机抽取10000份邮件导入并进行初步的数据清洗后,我们查看一下导入后的数据情况。基本上文本内容均是我们所需要的汉字正文,可以进行下一步的分词提取关键词了。
文本分词处理
在用朴素贝叶斯算法进行邮件分类之前,需对整段的中文文本进行分词,并提取关键词。本文中用的中文分词包为jiebaR,分词后的数据格式整理用的是tm包,如果是处理英文文本,则可直接使用tm包,其十分强大,能够很方便的处理英文文本,但是对中文文本的支持则没有那么完善。
#分词并提取关键词
engine <- worker()
keys = worker("keywords",topn=20)
clean_word <- function(data){
return(paste(unique(vector_keywords(segment(data$text,engine),keys)),collapse=" "))
}
email_words <- ddply(normal_emails,.(type,path),clean_word) %>% rename(.,replace = c("V1" = "words"))
#建立语料库
emails_corpus <- Corpus(VectorSource(email_words$words)) %>% tm_map(.,stripWhitespace)
#创建文档-单词矩阵
emails_dtm <- DocumentTermMatrix(emails_corpus)
垃圾邮件分类
在文本数据处理完后,则可以开始进行垃圾邮件分类了!本文中进行垃圾邮件分类用的是e1071包。
library(dplyr)
library(plyr)
library(stringr)
library(tm)
library(jiebaR)
library(e1071)
#随机抽取70%的数据作为训练集,剩下的30%作为测试集
train_row <- sample(1:length(email_words$type),size = floor((length(email_words$type) *0.7)))
email_words_train <- email_words[train_row,]
email_words_test <- email_words[-train_row,]
emails_dtm_train <- emails_dtm[train_row,]
emails_dtm_test <- emails_dtm[-train_row,]
emails_corpus_train <- emails_corpus[train_row]
emails_corpus_test <- emails_corpus[-train_row]
#选取词频>=5的词汇
emails_words_dict <- findFreqTerms(emails_dtm_train,5)
emails_corpus_freq_train <- DocumentTermMatrix(emails_corpus_train,list(dictionry = emails_words_dict))
emails_corpus_freq_test <- DocumentTermMatrix(emails_corpus_test,list(dictionry = emails_words_dict))
#将训练集和测试集中的词用0,1分别标记在文本中未出现、出现某一词汇
convert_counts <- function(x){
x <- ifelse(as.numeric(as.character(x))>0,1,0)
x <- factor(x,levels = c(0,1),labels = c("No","Yes"))
return(x)
}
emails_corpus_convert_train <- apply(emails_corpus_freq_train,MARGIN = 2,convert_counts)
emails_corpus_convert_test <- apply(emails_corpus_freq_test,MARGIN = 2,convert_counts)
#利用朴素贝叶斯算法进行分类
emails_naiveBayes <- naiveBayes(emails_corpus_convert_train,email_words_train$type,laplace = 1)
#测试分类的效果
emails_predict <- predict(emails_naiveBayes,emails_corpus_convert_test)
我们来看一下分类器对测试集的分类效果,
library(gmodels)
CrossTable(emails_predict,email_words_test$type)
926条非垃圾邮件数据中的14条被误分为垃圾邮件,占比1.5%;1464条垃圾邮件数据中的1295条被正确分类,占比88.5%。详情如下
分类过程中的尝试
在得到最终的分类结果之前,还进行了一些尝试,得到分类器效果均不及最终的分类结果,具体情况如下:
1.在分词后,关键词选取文本中出现的名词、形容词作为输入模型的数据,得到的分类器将926条非垃圾邮件数据中的30条误分为垃圾邮件,占比3.2%;1464条垃圾邮件数据中的1202条被正确分类,占比83.3%。
2.以TF-IDF值筛选关键词,但是训练分类器时未加入拉普拉斯平滑,得到的分类器将926条非垃圾邮件数据中的20条误分为垃圾邮件,占比2.2%;1464条垃圾邮件数据中的1230条被正确分类,占比84%。
以上是在R语言用朴素贝叶斯算法进行垃圾邮件分类的全过程。如有做的不好或这不对的地方还请大家指正!
以上是关于R语言:朴素贝叶斯算法实现对中文垃圾邮件的分类的主要内容,如果未能解决你的问题,请参考以下文章