朴素贝叶斯(Naive Bayes)及python实现(sklearn)
Posted 奔跑的郭小明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯(Naive Bayes)及python实现(sklearn)相关的知识,希望对你有一定的参考价值。
今天介绍一个分类算法——朴素贝叶斯,最经典应用用于垃圾邮件分类问题,该算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
贝叶斯公式:
先验概率P(X):先验概率:是指根据以往经验和分析得到的概率。
后验概率P(Y|X):事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小。
类条件概率P(X|Y):在已知某类别的特征空间中,出现特征值X的概率密度。
朴素贝叶斯算法是假设各个特征之间相互独立,也是朴素这词的意思。
但是我们通常不关心具体的P(Y|X)值,而是关注最大值:

朴素贝叶斯模型可以解决整个训练集不能导入内存的大规模分类问题。 为了解决这个问题, MultinomialNB, BernoulliNB, 和 GaussianNB 实现了 partial_fit 方法,可以动态的增加数据,使用方法与其他分类器的一样
三种朴素贝叶斯算法:
① 高斯朴素贝叶斯分类器(默认条件概率分布概率符合高斯分布)
sklearn.naive_bayes.GaussianNB(priors=None)
当特征是连续变量的时候,假设特征分布为正太分布,根据样本算出均值和方差,再求得概率,用于classification问题,假定属性/特征是服从正态分布的,一般用在数值型特征。
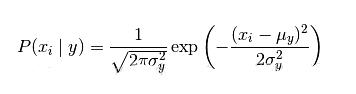
模型参数:
class_count_属性:获取各类标记对应的训练样本数
class_prior_属性:获取各个类标记对应的先验概率,返回数组
priors属性:同class_prior,返回列表
theta_属性:获取各个类标记在各个特征上的均值
sigma_属性:获取各个类标记在各个特征上的方差
partial_fit(X, y, classes=None, sample_weight=None):增量式训练,当训练数据集数据量非常大,不能一次性全部载入内存时,可以将数据集划分若干份,重复调用partial_fit在线学习模型参数,在第一次调用partial_fit函数时,必须制定classes参数,在随后的调用可以忽略
②多项式朴素贝叶斯分类器(条件概率符合多项式分布)MultinomialNB
用于离散值模型里,比如文本分类问题里面我们提到过,我们不光看词语是否在文本中出现,也得看出现的次数,多项式模型在计算先验概率P(Yk)和条件概率P(xi|Yk)时,会做一些平滑处理,具体公式为(因为朴素贝叶斯有一个致命缺点即对数据稀疏问题过于敏感,可能导致有些新测试样本在训练样本中从未出现,所以使用平滑处理):
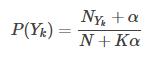
参数:N:样本数;NYk:类别为Yk的样本数;K:总的类别个数;α:平滑值
当α=1时,称作Laplace平滑,当0<α<1时,称作Lidstone平滑,α=0时不做平滑。

参数:NYk,xi:类别为Yk,且特征为x1的样本数;n:特征x1可以选择的数量。
模型参数:
alpha:浮点型,可选项,默认1.0,添加拉普拉修/Lidstone平滑参数
fit_prior:布尔型,可选项,默认True,表示是否学习先验概率,参数为False表示所有类标记具有相同的先验概率
class_prior:类似数组,数组大小为(n_classes,),默认None,类先验概率
③伯努利朴素贝叶斯分类器(条件概率符合二项分布)BernoulliNB
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,伯努利模型中每个特征的取值只能是1和0(以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0).条件概率P(xi|yk)的计算方式是:
当特征值xi为1时:
当特征值xi为0时:
我们就以文档主题分类为目标,因为涉及到了多分类问题,那么就使用多项贝叶斯分类器,以python代码实现,用sklearn已经有现成的新闻文本数据集,20个不同主题的新闻组集合,我们先看看数据集的案例:
From: scotts@math.orst.edu (Scott Settlemier)
Subject: FORSALE: MAG Innovision MX15F 1280x1024
Article-I.D.: gaia.1r7hir$9sk
Distribution: world
Organization: Oregon State University Math Department
Lines: 7
NNTP-Posting-Host: math.orst.edu
MAG Innovision MX15F
Fantastic 15" multiscan monitor that can display up to
1280x1024 noninterlaced (!) with .26 mm dot pitch.
If you are looking for a large crystal clear super vga
monitor then this is for you.
$430 call Scott at (503) 757-3483 or
email scotts@math.orst.edu
而对应的样本标签为数字,分别为0~19。
python实现多分类代码:
from sklearn.datasets import fetch_20newsgroups # 导入新闻数据抓取器 fetch_20newsgroups
from sklearn.model_selection import train_test_split # 导入数据集分割工具
from sklearn.feature_extraction.text import CountVectorizer # 导入文本特征向量化模块
from sklearn.naive_bayes import MultinomialNB # 导入多项式朴素贝叶斯模型
from sklearn.metrics import classification_report # 分类问题的评估报告
# 数据获取
news = fetch_20newsgroups(subset='all')
print (len(news.data)) # 输出数据的条数:18846
# 对数据进行预处理:训练集和测试集分割
# 随机采样25%的数据样本作为测试集
X_train,X_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25,random_state=11)
# 对数据进行预处理:文本特征向量化
vec = CountVectorizer()
X_train = vec.fit_transform(X_train)
X_test = vec.transform(X_test)
# 使用多项式朴素贝叶斯进行训练
mnb = MultinomialNB() # 使用默认配置初始化朴素贝叶斯
# 训练拟合模型
mnb.fit(X_train,y_train) # 利用训练数据对模型参数进行估计
# 模型预测
y_predict = mnb.predict(X_test) # 对参数进行预测
# 结果评估:模型分数及分类报告
print ('The Accuracy of MultinomialNB is:', mnb.score(X_test,y_test))
print (classification_report(y_test, y_predict, target_names = news.target_names))
欢迎小伙伴们留言或者私信我,代码已上传:
https://github.com/jm199504/ML
以上是关于朴素贝叶斯(Naive Bayes)及python实现(sklearn)的主要内容,如果未能解决你的问题,请参考以下文章