Peter教你谈情说AI | 06朴素贝叶斯分类器
Posted 人人都是极客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Peter教你谈情说AI | 06朴素贝叶斯分类器相关的知识,希望对你有一定的参考价值。
开始我们谈到回归问题和分类问题,其中回归问题可以用梯度下降法求出其模型,那么分类模型可以通过什么方法可以求出呢?
我们知道回归模型是预测一个量,分类模型则是预测一个标签。换一个角度来看,回归模型输出的预测值则是连续值;而分类模型输出的预测值是离散值。也就是说输入一个样本给模型,回归模型给出的预测结果是在某个值域上的任意值;而分类模型则是给出特定的某几个离散值之一。
接下来我们就讲一个做分类的模型:朴素贝叶斯分类器。
朴素贝叶斯法
在讲朴素贝叶斯分类器之前,我们先来看看概率统计中一个非常重要的定理:贝叶斯定理。
这个公式用语言解释就是:在 B 出现的前提下 A 出现的概率,等于 A 和 B 都出现的概率除以 B 出现的概率。换句话说就是后验概率和先验概率的关系。
上面公式是当 B 作为 A 的条件出现时,我们假定它总共只有一个特征。但在实际应用中,很少有一件事只受一个特征影响的情况,往往影响一件事的因素有多个。假设,影响 B 的因素有 n 个,分别是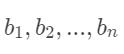 。
。
则P(A|B)可以写为:
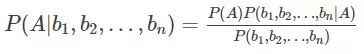
A 的先验概率 P(A) 和多个因素的联合概率 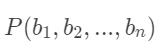 都是可以单独计算的,与A和bi之间的关系无关,因此这两项都可以被看作常数。对于求解
都是可以单独计算的,与A和bi之间的关系无关,因此这两项都可以被看作常数。对于求解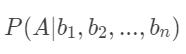 ,最关键的是
,最关键的是 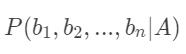 。根据链式法则,可得:
。根据链式法则,可得:
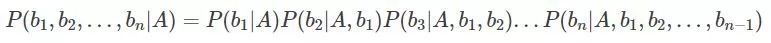
上面的求解过程,看起来好复杂,但是,如果从b1到bn这些特征之间,在概率分布上是条件独立的,也就是说每个特征bi与其他特征都不相关。
那么,当i不等于j时,有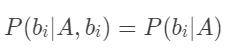 —— 无关条件被排除到条件概率之外。因此,当 中每个特征与其他 n-1 个特征都不相关时,就有:
—— 无关条件被排除到条件概率之外。因此,当 中每个特征与其他 n-1 个特征都不相关时,就有:
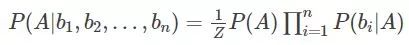
注意:此处的 Z 对应,贝叶斯分类器就是计算出概率最大的那个分类,也就是求上面这个公式的最大值。
由于 对于所有的类别都是相同的,可以省略,问题就变成了求
P(b1b2...bn|C)P(A)的最大值。
下面再通过两个例子,来看如何使用朴素贝叶斯分类器。
则 P(A|B)可以写为:
朴素贝叶斯分类器
例子1:
根据某社区网站的抽样统计,该站10000个账号中有89%为真实账号(设为C0),11%为虚假账号(设为C1)。
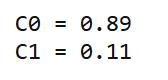
下来,就要用统计资料判断一个账号的真实性。假定某一个账号有以下三个特征:

请问该账号是真实账号还是虚假账号?方法是使用朴素贝叶斯分类器,计算下面这个计算式的值。
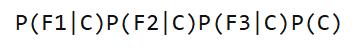
虽然上面这些值可以从统计资料得到,但是这里有一个问题:F1和F2是连续变量,不适宜按照某个特定值计算概率。 一个技巧是将连续值变为离散值,计算区间的概率。比如将F1分解成[0, 0.05]、(0.05, 0.2)、[0.2, +∞]三个区间,然后计算每个区间的概率。在我们这个例子中,F1等于0.1,落在第二个区间,所以计算的时候,就使用第二个区间的发生概率。 根据统计资料,可得:

因此:

可以看到,虽然这个用户没有使用真实头像,但是他是真实账号的概率,比虚假账号高出30多倍,因此判断这个账号为真。
例子2:
下面是一组人类身体特征的统计资料。
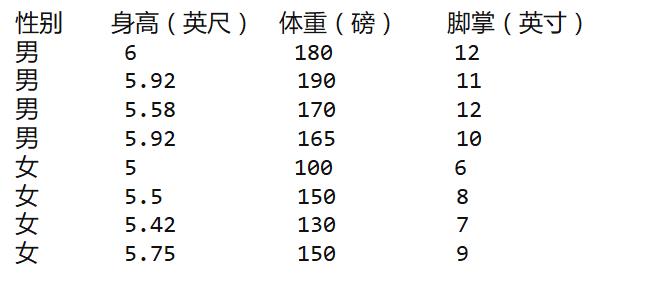
已知某人身高6英尺、体重130磅,脚掌8英寸,请问该人是男是女?根据朴素贝叶斯分类器,计算下面这个式子的值。
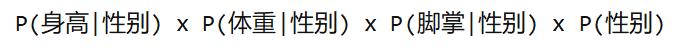
这里的困难在于,由于身高、体重、脚掌都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。怎么办?
这时,可以假设男性和女性的身高、体重、脚掌都是正态分布,通过样本计算出均值和方差,也就是得到高斯分布的密度函数。有了密度函数,就可以把值代入,算出某一点的密度函数的值。
我们知道,高斯分布又名正态分布(在二维空间内形成钟形曲线),每一个高斯分布由两个参数——均值和方差决定。
比如,男性的身高是均值5.855、方差0.035的正态分布。所以,男性的身高为6英尺的概率的相对值等于1.5789(大于1并没有关系,因为这里是密度函数的值,只用来反映各个值的相对可能性)。
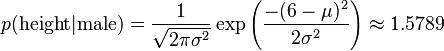
有了这些数据以后,就可以计算性别的分类了。

可以看到,女性的概率比男性要高出将近10000倍,所以判断该人为女性。
:
工作流程
与多数的机器学习过程类似,分为准备过程,以确定特征值及分类为主,之后开始训练并生成分类器;最后则可以应用步骤二产生的分类器了。
【推荐阅读】
轻轻一扫 欢迎关注~
如果觉得好,请
转发
转发
转发
以上是关于Peter教你谈情说AI | 06朴素贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章