朴素贝叶斯之新闻分类
Posted 图灵视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯之新闻分类相关的知识,希望对你有一定的参考价值。

条件概率表示在一个事件发生的条件下,另一事件发生的概率,如在X发生的条件下,Y发生的概率表示为P(Y|X)。
条件概率公式如下:

表示在X发生的条件下,Y发生的概率等于二者同时发生的概率除以X发生的概率。此时,P(X)叫作先验概率;P(Y|X)叫作后验概率;P(XY)叫作联合概率,表示X和Y同时发生的概率。
由条件概率公式,我们很容易推出乘法公式1:
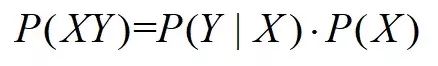
当然,条件概率公式中,X和Y的关系可以反过来,那么乘法公式2又可以表示为:
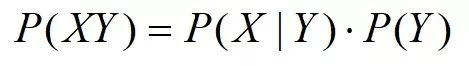
假设事件Y本身又包含了多种可能性,如Y={Y1,Y2,...,Yn},且它们构成一个完备事件组,那么又有全概率公式1:
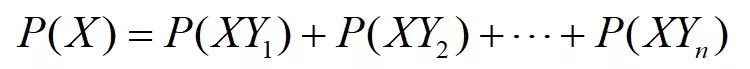
代入乘法公式,全概率公式2又可以表示为:
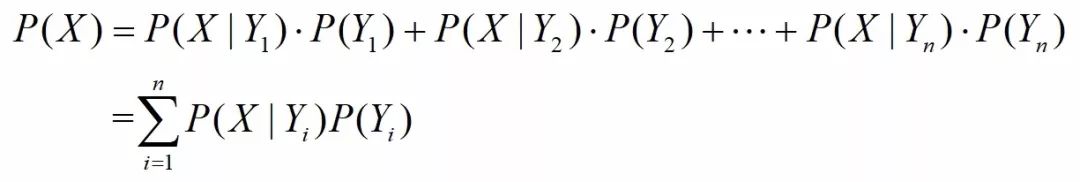
由条件概率公式和乘法公式2,可以推出简洁版的贝叶斯公式:
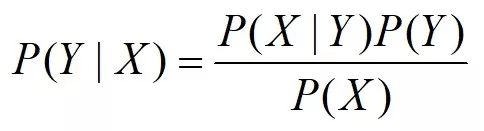
那么对于Y集合中任意一个的事件Yi,其贝叶斯公式:
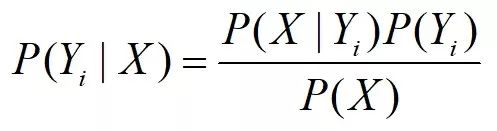
进一步代入全概率公式2,可以推出一般化的贝叶斯公式:
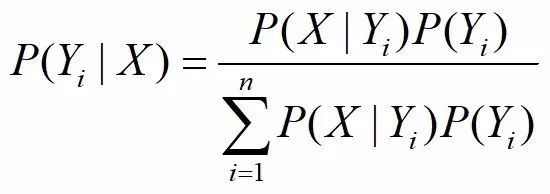
分类问题实际上是求取某一类别概率最大的问题,所以贝叶斯的分母P(X)可以不参与计算,我们只需要计算每一种类别的联合概率P(YX)=P(X|Y)P(Y)=P(XY),所以说贝叶斯是一种生成式模型。朴素贝叶斯的“朴素”二字表示特征集X中的每个特征都是条件独立的,彼此之间没有相互影响。之所以如此假设,是因为后验概率P(X|Y)非常难以计算,如果X满足“朴素”假设,则P(X|Y)可以拆解为P(X0|Y)*P(X1|Y)......P(Xn|Y),而每个成员P(Xi|Y)可以根据数据集很轻松的计算出来。
以本文文本分类为例,提取特征通常有两种方式,一种是词集模型,该模型只关注词在总的词汇表(词汇表由统计所有类别下去重后的总词汇数)中有没有出现,出现为1,否则为0;另一种是词袋模型,该模型会关注词出现的次数,以出现次数作为该词的特征。
词集模型代码:
#vocabList词汇表 inputSet某篇文档去重词汇集
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec
词袋模型代码:
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
在本文的新闻分类任务中,数据集来自《搜狗的文本分类语料库迷你版》,读者可以在该链接获取:
http://hanlp.linrunsoft.com/release/corpus/sogou-text-classification-corpus-mini.zip
或在下篇文章中的github获取数据集和全部源码。
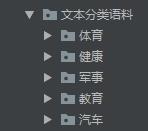
语料共有如下5个类别,每个类别共有1000篇新闻文档:
对新闻类别用数字替代,可以用一个字典来表示:
贝叶斯训练的代码如下,最终获得了每个类别的参数p0Vect, p1Vect,p2Vect, p3Vect,p4Vect,每个参数都是一个列表,其中 p0Vect =[P(X0|Y0) P(X1|Y0) ...... P(Xn|Y0)],其他参数同理:
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix)
#trainMatrix列表中的每个元素都是长度为总词汇量去重后的列表
numWords = len(trainMatrix[0])
#即概率p(c1) 表示某类文档概率 二分类问题p(c0) = 1 - p(c1)
pAbusive = 1 / 5 # 5个类别的文档数目近似相等
p0Num = ones(numWords)
p1Num = ones(numWords) # change to ones()
p2Num = ones(numWords)
p3Num = ones(numWords)
p4Num = ones(numWords)
p0Denom = 2.0
p1Denom = 2.0 # change to 2.0
p2Denom = 2.0
p3Denom = 2.0
p4Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 0:
#遍历每个侮辱性文档,求所有侮辱文档中每个词汇的出现次数和侮辱文档中词汇总次数,为了求概率p(wi|c1)
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
if trainCategory[i] == 2:
p2Num += trainMatrix[i]
p2Denom += sum(trainMatrix[i])
if trainCategory[i] == 3:
p3Num += trainMatrix[i]
p3Denom += sum(trainMatrix[i])
else:
p4Num += trainMatrix[i]
p4Denom += sum(trainMatrix[i])
#分别求每个类别中的概率p(wi|ci),这里取log是防止下溢风险
p0Vect = log(p0Num / p0Denom) # p(wi|c0)
p1Vect = log(p1Num / p1Denom) # p(wi|c1)
p2Vect = log(p2Num / p2Denom) # p(wi|c2)
p3Vect = log(p3Num / p3Denom) # p(wi|c3)
p4Vect = log(p4Num / p4Denom) # p(wi|c4)
return p0Vect, p1Vect,p2Vect, p3Vect,p4Vect,pAbusive
利用上面求取的参数对新出的新闻进行分类(或随机抽取若干篇进行分类)。
def classifyNB(vec2Classify, p0Vec, p1Vec,p2Vec, p3Vec,p4Vec, pClass1):
p0 = sum(vec2Classify * p0Vec) + log(pClass1)
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
p2 = sum(vec2Classify * p2Vec) + log(pClass1)
p3 = sum(vec2Classify * p3Vec) + log(pClass1)
p4 = sum(vec2Classify * p4Vec) + log(pClass1)
list = []
list.append(p0)
list.append(p1)
list.append(p2)
list.append(p3)
list.append(p4)
if max(list) == p0:
return 0
if max(list) == p1:
return 1
if max(list) == p2:
return 2
if max(list) == p3:
return 3
if max(list) == p4:
return 4
此方法会对文本做一些预处理,去除新闻中的标点和特殊字符,并采用结巴分词进行分词。
def docClassificationTest():
docList = []
classList = []
fullText = []
dict = {}
path = '文本分类语料'
dirs = os.listdir(path)
# 共有5个类别
for dir in dirs:
dict[dirs.index(dir)] = dir
for i in range(1, 1001):
# print(dir)
if i < 10:
num = "000" + str(i)
elif i < 100:
num = "00" + str(i)
elif i < 1000:
num = "0" + str(i)
else:
num = str(i)
print('%s' % dir + '/' + '%s.txt' % num)
# 去除特殊符号和标点
doc = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!―:,,。?、“”~@#¥%……&*();()《》【】]+", "",
open(path + '/%s' % dir + '/' + '%s.txt' % num, encoding='utf-8').read())
# 结巴分词
wordGenerator = jieba.cut(doc)
wordList = []
for index in wordGenerator:
wordList.append(index)
#print(wordList)
docList.append(wordList)
fullText.extend(wordList)
classList.append(dirs.index(dir))
vocabList = createVocabList(docList) # create vocabulary
trainingSet = list(range(5000))
testSet = [] # create test set
for i in list(range(100)):
randIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del (trainingSet[randIndex])
trainMat = []
trainClasses = []
for docIndex in trainingSet: # train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V, p1V,p2V, p3V,p4V,pSpam = trainNB0(array(trainMat), array(trainClasses))
errorCount = 0
for docIndex in testSet: # classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector), p0V, p1V,p2V, p3V,p4V, pSpam) != classList[docIndex]:
errorCount += 1
print("classification error", docList[docIndex])
print('the error rate is: ', float(errorCount) / len(testSet))
return float(errorCount) / len(testSet)
以上是关于朴素贝叶斯之新闻分类的主要内容,如果未能解决你的问题,请参考以下文章