干货 | 朴素贝叶斯算法
Posted 数字地形周刊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | 朴素贝叶斯算法相关的知识,希望对你有一定的参考价值。

01
概念
朴素贝叶斯算法是基于贝叶斯定理与特征条件独立假设的分类方法。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier,或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
02
主要内容
算法思想
朴素贝叶斯法(Naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大输出y。
朴素贝叶斯分类器中的一个假设是:每个特征同等重要。
贝叶斯公式:
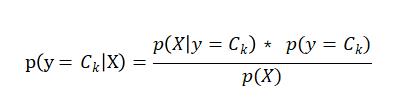
X是M维向量的时候 因为特征条件独立(朴素),根据全概率公式展开,即:
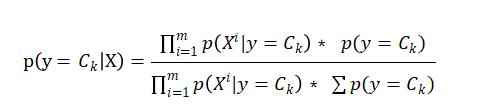
朴素贝叶斯算法实际上是解决一种分类问题,其本质上正是利用以上概率统计的方法,求解后验概率,并将后验概率的大小作为分类的依据。
算法使用条件
朴素:特征条件独立
优缺点
优点:
1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
2)对小规模的数据表现很好,能够处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以分批次训练。
3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点:
1) 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性进行适度改进。
2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候由于假设的先验模型会导致预测效果不佳。
3)由于我们是通过先验和数据来决定后验的概率从而决定分类,因此分类决策存在一定的错误率。
4)对输入数据的表达形式很敏感。
03
代码示例
朴素贝叶斯算法最典型的一个例子,即垃圾邮件分类方法。我们想判断一个邮件是不是垃圾邮件,那么我们知道的是这个邮件中词的分布,那么我们还要知道:垃圾邮件中某些词的出现频率是多少,这个问题可以利用贝叶斯定理解决。
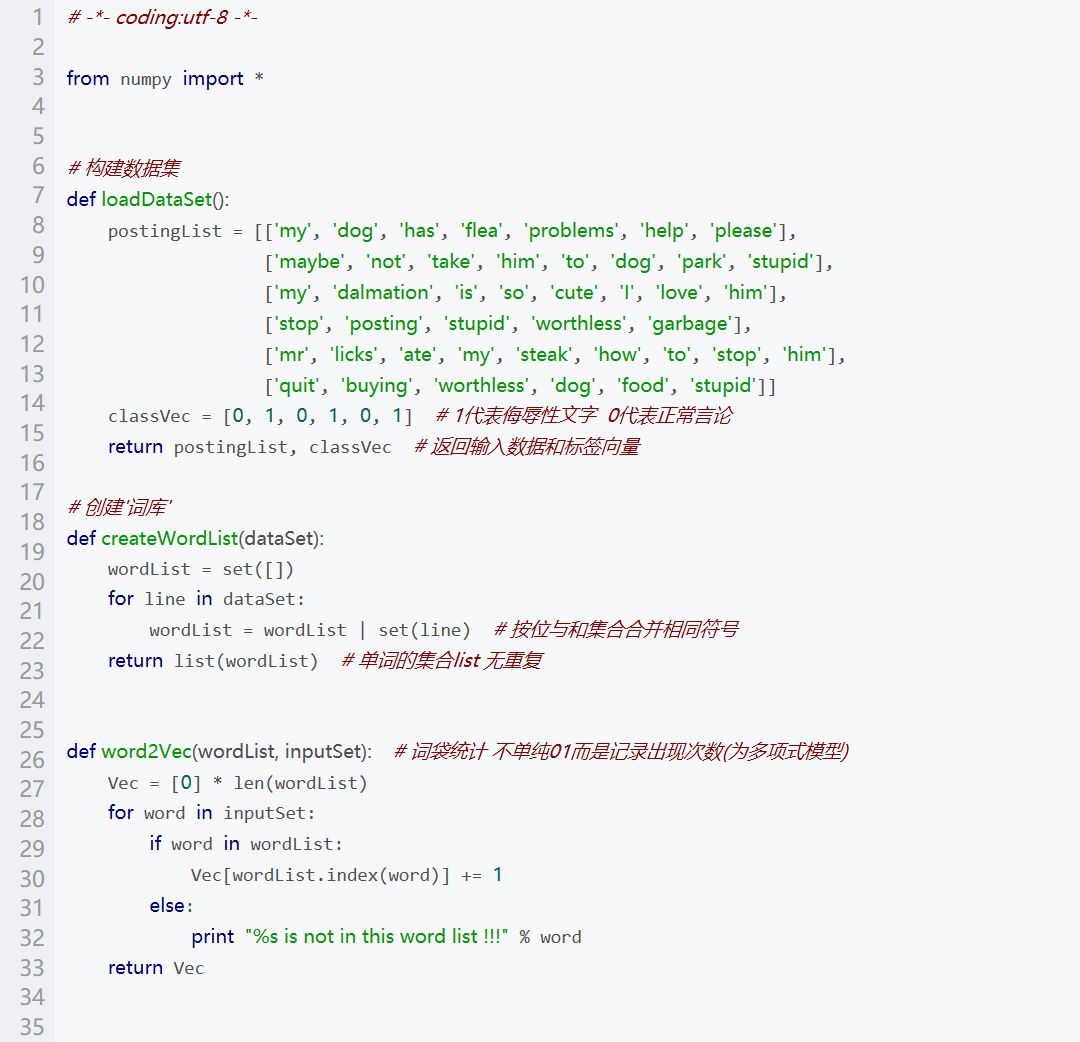
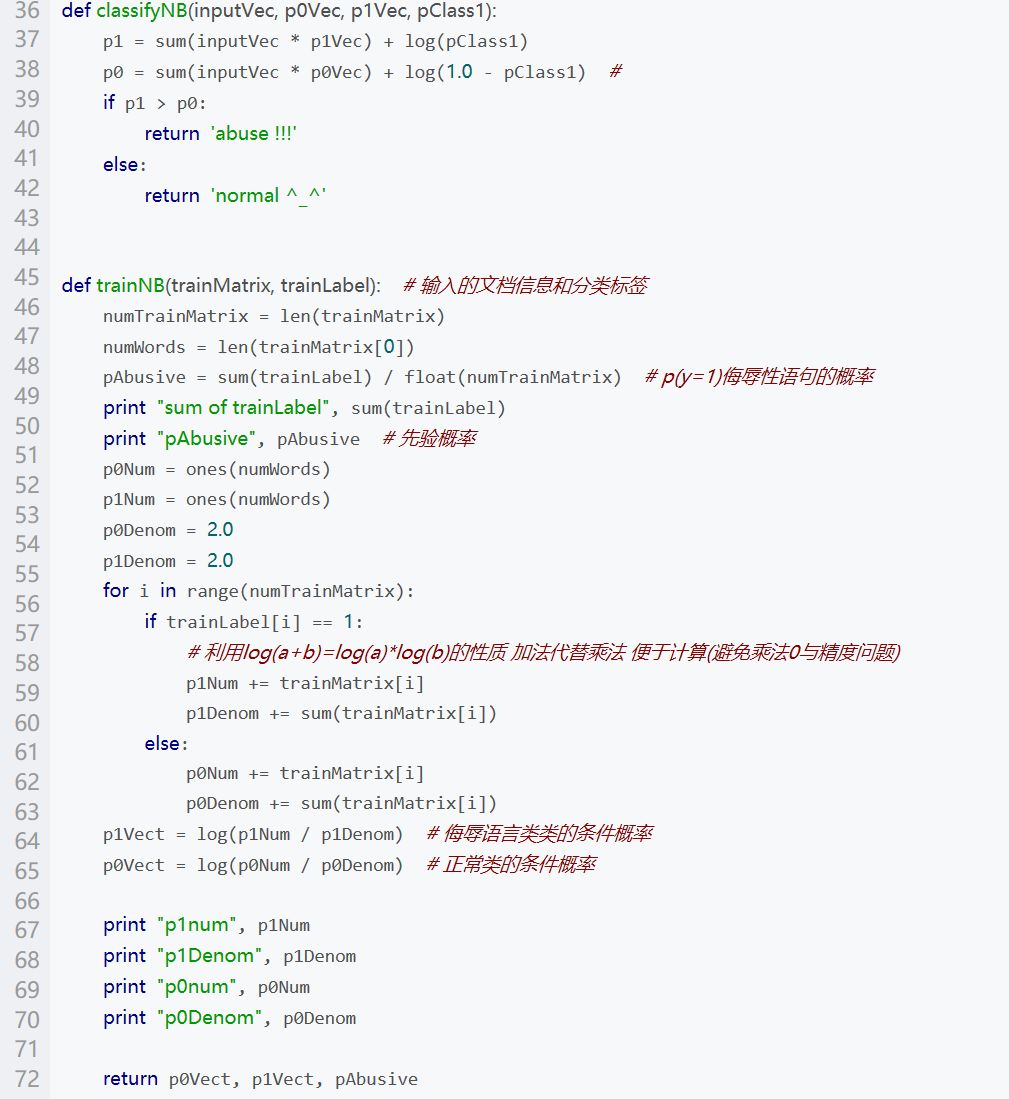
运行结果:
数字地形周刊整理
供稿 | 赵飞
编辑 | 丁紫妍
以上是关于干货 | 朴素贝叶斯算法的主要内容,如果未能解决你的问题,请参考以下文章