生成模型分类(含朴素贝叶斯)
Posted 码蚁LucasGY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生成模型分类(含朴素贝叶斯)相关的知识,希望对你有一定的参考价值。
一、生成方法概述
在所有的机器学习分类算法中,有一种分法可以分为生成方法和判别方法。
判别方法,也就是直接学习出特征输出Y和特征X之间的关系,要么是决策函数Y=f(X),要么是条件分布P(Y|X)
生成方法,就是直接找出特征输出Y和特征X的联合分布P(X,Y),然后用P(Y|X)=P(X,Y)/P(X)得出P(Y|X),实际学到的是数据的生成机制。
总结如图所示:
二、生成方法分类模型推导
2.1 输入、输出等参数定义

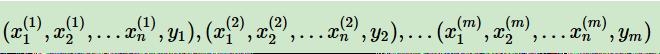
由P(X, Y)独立同分布产生。
即我们有m个样本,每个样本有n个特征,特征输出有K个类别,定义为C1,C2,...,CK。

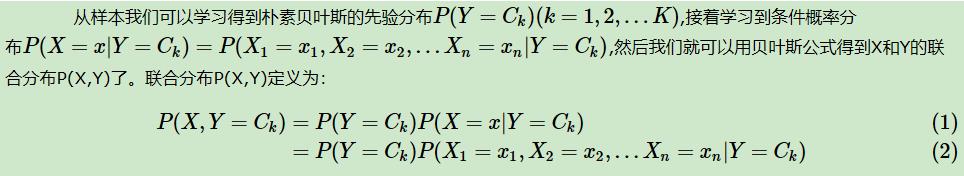

计算出针对每个类别的联合概率分布,最大的即为该样本属于最可能的那个类。
2.1 后验概率最大化等价于期望风险最小化
《统计学习方法》
三、朴素贝叶斯与非朴素贝叶斯的分水岭——参数估计
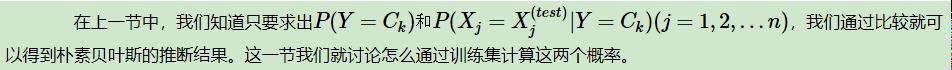
3.1 求先验分布
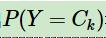
比较简单,一般通过极大似然估计得到。

这里的N和上文的m都是训练集样本数的意思,为了省事直接截图了。
注意:其实也可以not only极大似然,but also 最大后验法、贝叶斯估计。。。balabala
3.2 求条件概率分布
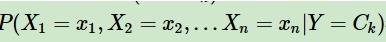
3.2.1 朴素贝叶斯的观点认为:

由计算Ck类的条件下,各个维度的联合后验概率变成的独立的每个维度特征概率的乘积。计算每个特征的出现概率时:
a) 如果我们的Xj是离散的值,那么我们可以假设Xj符合多项式分布
b)如果我们我们的Xj是非常稀疏的离散值,即各个特征出现概率很低,这时我们可以假设Xj符合伯努利分布
c)如果我们我们的Xj是连续值,我们通常取Xj的先验概率为正态分布
这里关于那些分布产生概率的公式就不赘述了,书上网上遍地都是。注意:至于拉普拉斯平滑,就是没有利用我们经常用到的极大似然估计,而是使用了贝叶斯估计得到的结果。
3.2.2 我们也可以让朴素贝叶斯不再朴素!!!!
在特征维度没有那么多的条件下,我们可以直接求出条件概率分布:
我遇到大部分场景(传感器数据),每个特征都是连续值,在不经过处理/经过微小处理(log1)就可以变为类似的高斯分布,所以可以将各个特征看作是多元高斯分布,从而求出每个点对应的条件概率分布的值(其实求的是概率密度,但不影响结果,朴素贝叶斯也是如此)。
多元高斯分布

我这里自己写了一个非朴素贝叶斯分类器,来对比和朴素贝叶斯的分类效果。
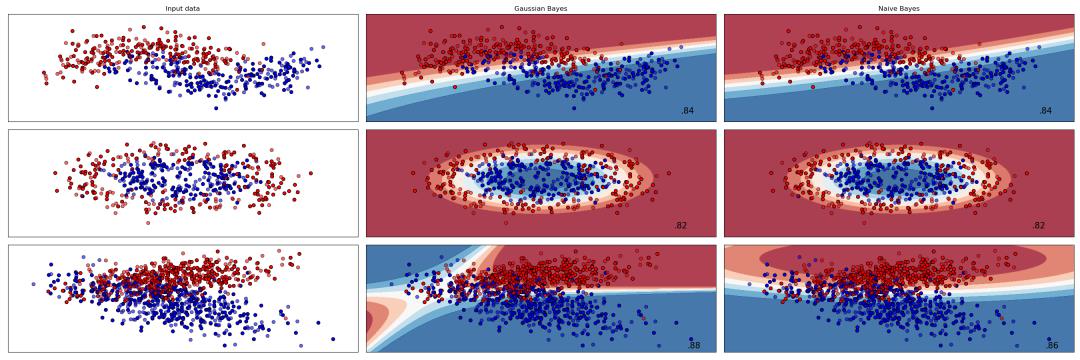
1、对于第三个数据集,更能反映出非朴素贝叶斯分类器和朴素贝叶斯分类器的区别,对于非朴素贝叶斯分类器,对于特征具有线性相关性的,具有比较好的决策边界,比朴素贝叶斯更合理,预测效果也更好。
2、从程序的结果来看,多元高斯分布考虑的是各个维度之间的线性相关性,对特征的非线性相关性没有很好的解释,这时,我想到了,能不能将点映射到核空间上,然后进行贝叶斯分类(就是像核SVM那样),也许早已经有人这么做了,但我还不太清楚,是一个继续做/学下去的点!!!!!
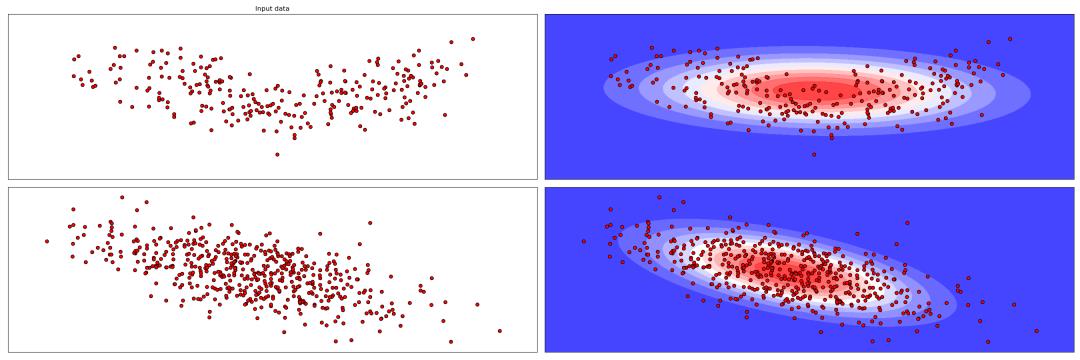
这里使用非线性相关特征数据和线性相关数据做多元高斯分布的结果:
四、从后验概率看生成模型与逻辑回归的关系
假设将问题简化至二分类,将 P(C1|x)整理,得到一个σ(z),这叫做Sigmoid function。
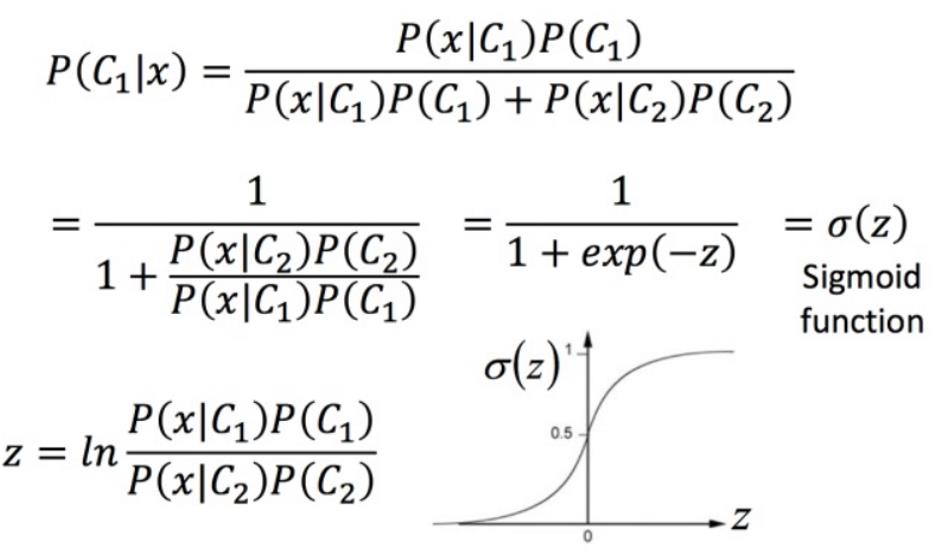
接下来算一下z 长什么样子:
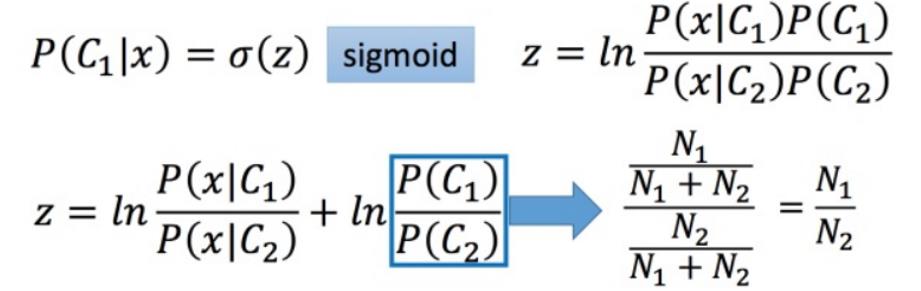
又因为已知假设在某个类的条件下,各个维度特征遵循多元高斯分布:
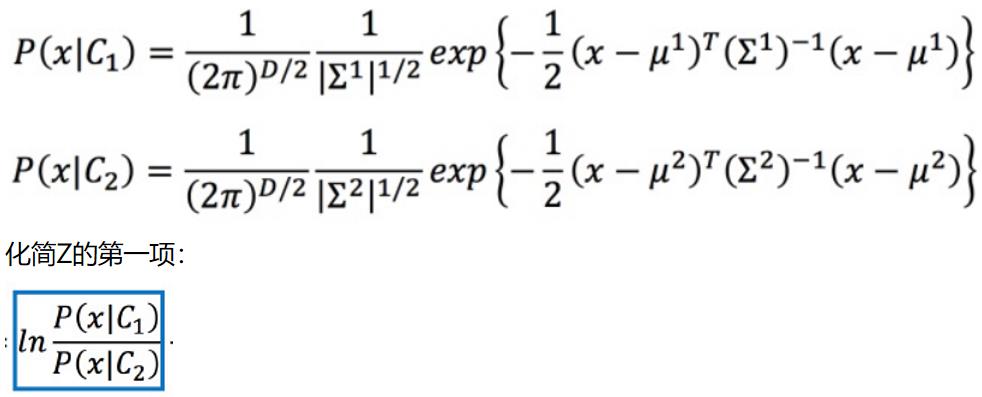

最后得到Z:
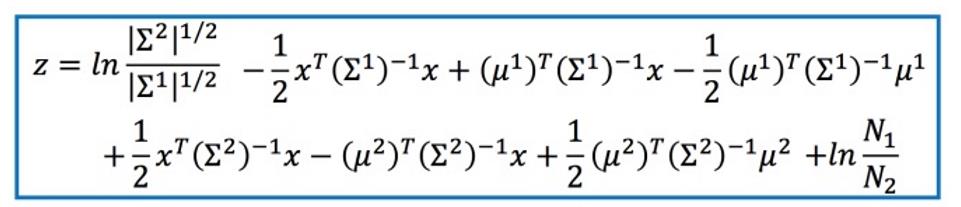
协方差矩阵是和输入feature大小的平方成正比,所以当feature很大的时候,协方差矩阵是可以增长很快的。此时考虑到model参数过多,容易Overfitting,为了有效减少参数,给描述这两个类别的高斯分布相同的协方差矩阵,有:
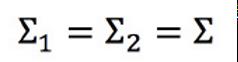
因此Z可以接着化简:

得到的,是一个线性模型(注意是在多个类共享一个协方差矩阵的条件下)。因此,在生成模型中,我们需要估计的参数有:
对于逻辑回归,我们是直接估计:
以上是关于生成模型分类(含朴素贝叶斯)的主要内容,如果未能解决你的问题,请参考以下文章