基于贝叶斯定理的算法——朴素贝叶斯分类
Posted Stata and Python数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于贝叶斯定理的算法——朴素贝叶斯分类相关的知识,希望对你有一定的参考价值。
文字编辑:孙晓玲
导读
算 法 原 理
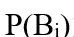 为先验概率,
为先验概率,
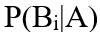 为后验概率。而朴素贝叶斯就是要在先验概率的基础上将每个样本都归入后验概率最大的那一类中,由于P(A|B)难以从有限的训练样本中估计得到,因此采用了条件独立性假设——每个属性独立的对分类结果产生影响,这也是朴素贝叶斯中“朴素”二字的含义,它构成了这一分类的前提。
为后验概率。而朴素贝叶斯就是要在先验概率的基础上将每个样本都归入后验概率最大的那一类中,由于P(A|B)难以从有限的训练样本中估计得到,因此采用了条件独立性假设——每个属性独立的对分类结果产生影响,这也是朴素贝叶斯中“朴素”二字的含义,它构成了这一分类的前提。
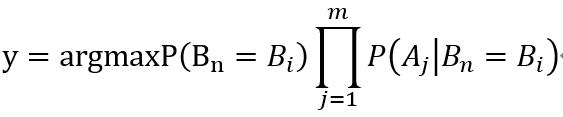
这就是朴素贝叶斯的推导式,对于不同的先验条件可以计算得到不同的模型,然后就可以利用得到的模型进行预测。
算 法 实 例
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score #用来计算分类准确率iris_sample = load_iris()x_train, x_test, y_train, y_test = train_test_split(iris_sample.data, iris_sample.target, test_size=0.25, random_state=123)nbclf = GaussianNB()nbclf.fit(x_train, y_train)y_test_pre = nbclf.predict(x_test)score = accuracy_score(y_test, y_test_pre) #accuracy_score(y_true, y_predict, normalize=True, sample_weight=None),normalize为True时计算正确分类比例,否则计算的是样本数print('测试集预测结果为:', y_test_pre)print('测试集正确结果为:', y_test)print('测试集准确度为:', score)
分类结果及准确率如图:

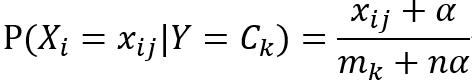
这个类中有三个参数,参数alpha即为上式中的α,默认取1,此时也称为拉普拉斯平滑;fit_prior表示是否要考虑先验概率,默认为True,当选择False时所有的样本类别输出都有相同的类别先验概率;class_prior用来输入先验概率,默认为None。该类所具有的预测方法与GaussianNB相同。
(3)BernoulliNB
BernoulliNB假设特征的先验概率为伯努利二项分布,它一共有4个参数,其中3个参数和MultinomialNB完全相同,剩下的那个参数binarize,当不传入取值时则将每个特征都看作二元,当传入数值时将小于binarize的归为一类,大于binarize归为另一类。此类的预测方法也与前两种一致。
如果样本特征大部分是连续值,一般会使用GaussianNB;如果样本特征大部分是多元离散值,则会使用MultinomialNB;而如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB。
以上就是我们对朴素贝叶斯分类器的介绍。

关于我们
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

以上是关于基于贝叶斯定理的算法——朴素贝叶斯分类的主要内容,如果未能解决你的问题,请参考以下文章