带你学习朴素贝叶斯分类器
Posted AIrange
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你学习朴素贝叶斯分类器相关的知识,希望对你有一定的参考价值。
最近,90后和00后的区别一直是大家喜欢讨论的话题,今天带大家以这个话题为例来开始今天的学习。
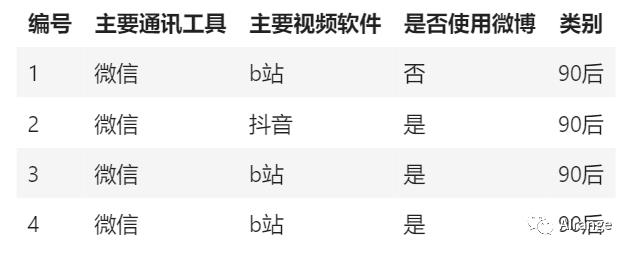
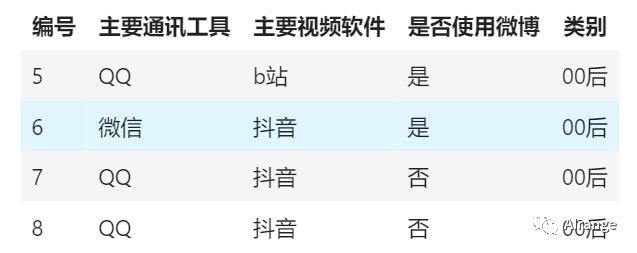
比如下面这个数据,是8个人的信息,其中有4个90后,4个00后,他们主要通讯工具、主要视频软件、是否使用微博等问题上存在着差异。
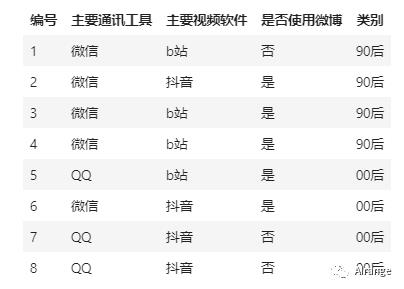
现在我们提出一个问题,如果一个人是90后或者00后,他的主要通讯工具是微信、主要视频软件是抖音、没有使用微博,那么我们猜测他是90后还是00后呢?
想要解决这个问题,可以用我们今天将要学习的算法。
本文内容:
1、朴素贝叶斯分类器如何解决问题
2、sklearn中的三种模型
3、实例应用
朴素贝叶斯分类器(Naive Bayes Classifier)
如果一个人是90后或者00后,他的主要通讯工具是微信、主要视频软件是抖音、没有使用微博,猜测他是90后还是00后。
显然这是一个二分类问题。
利用上面的8个数据,我们可以借用朴素贝叶斯分类的思想来解决这个问题。

贝叶斯公式
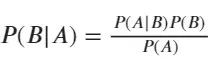
P(·):事件发生的概率。
P(B): 先验概率,是指根据以往经验和分析得到的概率。
例如,你投一个硬币,知道0.5概率正面朝上,0.5概率背面朝上。或者在不知道这个孩子任何特征的情况下,知道他是90后的概率是0.5,00后的概率是0.5。
P(A|B):条件概率,为当B事件发生的时候,A发生的概率。
也就是现在已知B发生,在这个基础上,A发生的概率。例如,你已知这个人是90后,他使用微信的概率是多少。
P(B|A):后验概率,是引入了新的信息后,对先验概率的修正。
例如,最开始由先验概率得到,这个孩子是90后和00后的概率都是0.5,现在因为知道他的一些特征,从而可以修正这个概率。
接下来我们看看贝叶斯公式如何用在机器学习的。

朴素贝叶斯分类
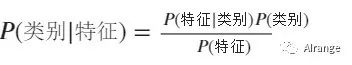
P(类别):客体属于此类别的概率。
P(特征):客体具有此特征的概率。
本题,我们想求解的问题是,一个人的主要通讯工具是微信、主要视频软件是抖音、没有使用微博,那么我们猜测他属于90后和00后的哪个类别。
也就是当这个人的特征1=微信,特征2=抖音,特征3=否的基础上,他是90后的概率是多少?他是00后的概率是多少?

如果P1>P2,则判定他为90后,否则判定为00后。
用贝叶斯公式求解P1,P2:

可以看到右边等式分母相同,所以我们只需求解分子然后比较分子大小即可。
首先,已知先验概率
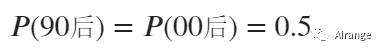
朴素贝叶斯,之所以称为朴素,是因为假定特征之间相互条件独立。也就是假设使用什么聊天工具、视频软件是否玩微博之间没有关系,之间的概率不会相互影响。
P(特征1=微信,特征2=抖音,特征3=否|90后)=P(特征1=微信|90后)P(特征2=抖音|90后)P(特征3=否|90后)=1*1/4*1/4=0.0625
P(特征1=微信,特征2=抖音,特征3=否|00后)=P(特征1=微信|00后)P(特征2=抖音|00后)P(特征3=否|00后)=1/4*3/4*1/2=0.09375
P(特征1=微信,特征2=抖音,特征3=否|90后)P(90后)=0.0625*0.5=0.03125
P(特征1=微信,特征2=抖音,特征3=否|00后)P(00后)=0.09375*0.5=0.046875
所以,可以得到 P2>P1,所以他是00后的可能性大一点,判断为00后。
理解完朴素贝叶斯分类的思想,我们来看看在sklearn的包中有哪些模型可供我们使用。
可以看到上面的例子用到的离散型特征,那么连续型特征朴素贝叶斯可以处理吗?
别担心,这里有很多模型可供我们使用。

朴素贝叶斯的三种模型
不同的朴素贝叶斯分类器的主要区别在于它们对分布的假设:
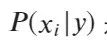
是xi出现在一个属于y类的样本中的概率。
多项式模型
sklearn.naive_bayes.MultinomialNB(alpha=1.0,fit_prior=True,class_prior=None)
适用于具有离散特征的分类(例如,用于文本分类的字数统计)。
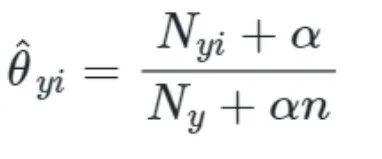
Nyi为特征i在训练集T上的y类样本出现的次数,Ny是y类样本的总数。其中α为平滑值(平滑值α≥0是为了解决学习数据集中不存在的具有特征i的样本,进一步防止了计算中的零概率),n为类别个数。
高斯模型
sklearn.naive_bayes.GaussianNB(priors=None, var_smoothing=1e-09)
适用于具有连续型特征的分类。
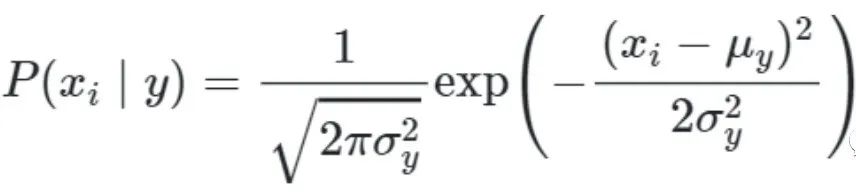
这里将概率密度视为高斯概率密度分布。
其中的参数σ 和μ 通过在训练集上进行最大似然估计来得到。
将xi代入,即可求出特征i出现在一个属于y类的样本中的概率。
伯努利模型
sklearn.naive_bayes.BernoulliNB(alpha=1.0,binarize=0.0,fit_prior=True, class_prior=None)
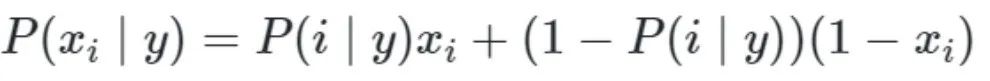
像MultinomialNB一样,此分类器适用于离散数据。区别在于,虽然MultinomialNB可处理出现次数,但BernoulliNB是为二进制/布尔型特征而设计的。
接下来我们来用实例调用模型。

实例
导入包
1import numpy as np
2import matplotlib.pyplot as plt
3import pandas as pd
查看数据
1dataset.head()
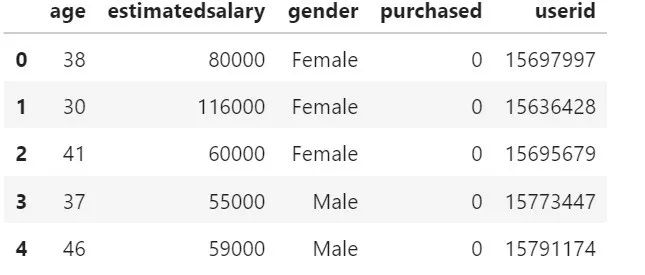
本例通过用户的年龄和预估薪水来预测用户购买汽车的意愿,为二分类问题。
数据预处理
1dataset[['age','estimatedsalary']]=dataset[['age','estimatedsalary']].astype(int)
2#设置特征和标签
3X = dataset.iloc[:, [0, 1]].values
4y = dataset.iloc[:, 3].values
5#划分训练集和测试集
6from sklearn.model_selection import train_test_split
7X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
8#特征标准化
9from sklearn.preprocessing import StandardScaler
10sc = StandardScaler()
11X_train = sc.fit_transform(X_train)
12X_test = sc.fit_transform(X_test)调用模型
因为是连续型特征,所以这里调用GaussianNB分类器。
1from sklearn.naive_bayes import GaussianNB
2Gaus_classifier = GaussianNB()
3Gaus_classifier.fit(X_train, y_train)
预测
1y_pred = Gaus_classifier.predict(X_test)
查看混淆矩阵
1from sklearn.metrics import confusion_matrix
2cm = confusion_matrix(y_test, y_pred)
3cm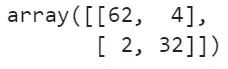
现实生活中朴素贝叶斯算法应用广泛,其中比较常用的就是文本分类,对NLP感兴趣的同学可以多多学习哦。
参考文档
https://scikit-learn.org/stable/modules/naive_bayes.html
https://zhuanlan.zhihu.com/p/26262151
精彩内容回顾:
编辑:Sunam
以上是关于带你学习朴素贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章