Sklearn 中的朴素贝叶斯分类器
Posted Python开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sklearn 中的朴素贝叶斯分类器相关的知识,希望对你有一定的参考价值。
(给Python开发者加星标,提升Python技能)
https://github.com/xitu/gold-miner/blob/master/TODO1/naive-bayes-classifier-sklearn-python-example-tips.md
用豆机实现的高斯分布
这篇教程详述了朴素贝叶斯分类器的算法、它的原理及优缺点,并提供了一个使用 Sklearn 库的示例。
背景
以著名的泰坦尼克号遇难者数据集为例。它收集了泰坦尼克号的乘客的个人信息以及是否从那场海难中生还。让我们试着用乘客的船票费用来预测一下他能否生还。
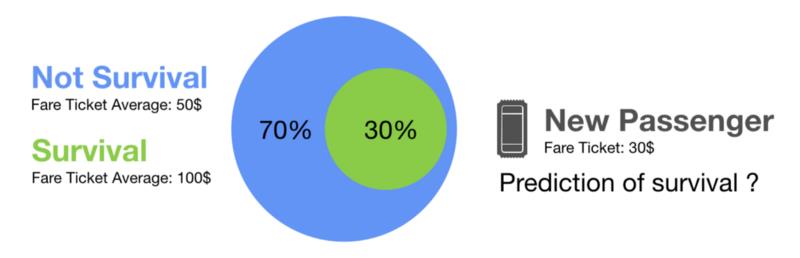
泰坦尼克号上的 500 名乘客
假设你随机取了 500 名乘客。在这些样本中,30% 的人幸存下来。幸存乘客的平均票价为 100 美元,而遇难乘客的平均票价为 50 美元。现在,假设你有了一个新的乘客。你不知道他是否幸存,但你知道他买了一张 30 美元的票穿越大西洋。请你预测一下这个乘客是否幸存。
原理
好吧,你可能回答说这个乘客没能幸存。为什么?因为根据上文所取的乘客的随机子集中所包含的信息,本来的生还几率就很低(30%),而穷人的生还几率则更低。你会把这个乘客放在最可能的组别(低票价组)。这就是朴素贝叶斯分类器所要实现的。
分析
朴素贝叶斯分类器利用条件概率来聚集信息,并假设特征之间相对独立。这是什么意思呢?举个例子,这意味着我们必须假定泰坦尼克号的房间舒适度与票价无关。显然这个假设是错误的,这就是为什么我们将这个假设称为朴素(Naive)的原因。朴素假设使得计算得以简化,即使在非常大的数据集上也是如此。让我们来一探究竟。
朴素贝叶斯分类器本质上是寻找能描述给定特征条件下属于某个类别的概率的函数,这个函数写作 P(Survival | f1,…, fn)。我们使用贝叶斯定理来简化计算:
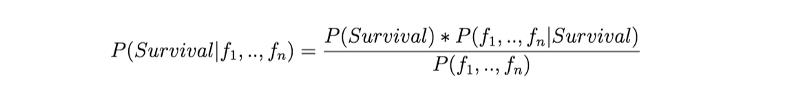
式 1:贝叶斯定理
P(Survival) 很容易计算,而我们构建分类器也不需要用到 P(f1,…, fn),因此问题回到计算 P(f1,…, fn | Survival) 上来。我们应用条件概率公式来再一次简化计算:
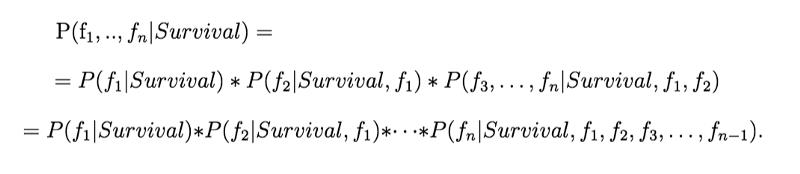
式 2:初步拓展
上式最后一行的每一项的计算都需要一个包含所有条件的数据集。为了计算 {Survival, f_1, …, f_n-1} 条件下 fn 的概率(即 P(fn | Survival, f_1, …, f_n-1)),我们需要有足够多不同的满足条件 {Survival, f_1, …, f_n-1} 的 fn 值。这会需要大量的数据,并导致维度灾难。这时朴素假设(Naive Assumption)的好处就凸显出来了。假设特征是独立的,我们可以认为条件 {Survival, f_1, …, f_n-1} 的概率等于 {Survival} 的概率,以此来简化计算:
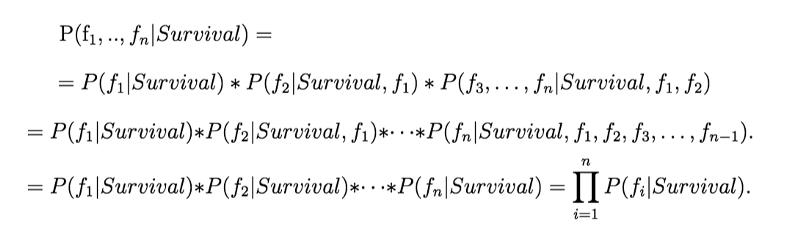
式 3:应用朴素假设
最后,为了分类,新建一个特征向量,我们只需要选择是否生还的值(1 或 0),令 P(f1, …, fn|Survival) 最高,即为最终的分类结果:
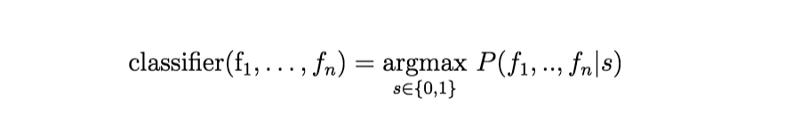
式 4:argmax 分类器
注意:常见的错误是认为分类器输出的概率是对的。事实上,朴素贝叶斯被称为差估计器,所以不要太认真地看待这些输出概率。
找出合适的分布函数
最后一步就是实现分类器。怎样为概率函数 P(f_i| Survival) 建立模型呢?在 Sklearn 库中有三种模型:
高斯分布:假设特征连续,且符合正态分布.

正态分布
多项式分布:适合离散特征。
贝努利分布:适合二元特征。
二项式分布
Python 代码
接下来,基于泰坦尼克遇难者数据集,我们实现了一个经典的高斯朴素贝叶斯。我们将使用船舱等级、性别、年龄、兄弟姐妹数目、父母/子女数量、票价和登船口岸这些信息。
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport timefrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB# 导入数据集data = pd.read_csv("data/train.csv")# 将分类变量转换为数字data["Sex_cleaned"]=np.where(data["Sex"]=="male",0,1)data["Embarked_cleaned"]=np.where(data["Embarked"]=="S",0,np.where(data["Embarked"]=="C",1,np.where(data["Embarked"]=="Q",2,3)))# 清除数据集中的非数字值(NaN)data=data[["Survived","Pclass","Sex_cleaned","Age","SibSp","Parch","Fare","Embarked_cleaned"]].dropna(axis=0, how='any')# 将数据集拆分成训练集和测试集X_train, X_test = train_test_split(data, test_size=0.5, random_state=int(time.time()))# 实例化分类器gnb = GaussianNB()used_features =["Pclass","Sex_cleaned","Age","SibSp","Parch","Fare","Embarked_cleaned"]# 训练分类器gnb.fit(X_train[used_features].values,X_train["Survived"])y_pred = gnb.predict(X_test[used_features])# 打印结果print("Number of mislabeled points out of a total {} points : {}, performance {:05.2f}%".format(X_test.shape[0],(X_test["Survived"] != y_pred).sum(),100*(1-(X_test["Survived"] != y_pred).sum()/X_test.shape[0])))
Number of mislabeled points out of a total 357 points: 68, performance 80.95%这个分类器的正确率为 80.95%。
使用单个特征说明
让我们试着只使用票价信息来约束分类器。下面我们计算 P(Survival = 1) 和 P(Survival = 0) 的概率:
mean_survival=np.mean(X_train["Survived"])mean_not_survival=1-mean_survivalprint("Survival prob = {:03.2f}%, Not survival prob = {:03.2f}%".format(100*mean_survival,100*mean_not_survival))
Survival prob = 39.50%, Not survival prob = 60.50%然后,根据式 3,我们只需要得出概率分布函数 P(fare| Survival = 0) 和 P(fare| Survival = 1)。我们选用高斯朴素贝叶斯分类器,因此,必须假设数据按高斯分布。
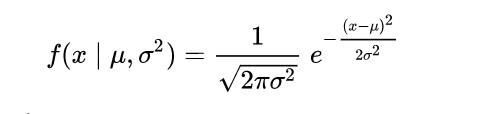
式 5:高斯公式(σ:标准差 / μ:均值)
然后,我们需要算出是否生还值不同的情况下,票价数据集的均值和标准差。我们得到以下结果:
mean_fare_survived = np.mean(X_train[X_train["Survived"]==1]["Fare"])std_fare_survived = np.std(X_train[X_train["Survived"]==1]["Fare"])mean_fare_not_survived = np.mean(X_train[X_train["Survived"]==0]["Fare"])std_fare_not_survived = np.std(X_train[X_train["Survived"]==0]["Fare"])print("mean_fare_survived = {:03.2f}".format(mean_fare_survived))print("std_fare_survived = {:03.2f}".format(std_fare_survived))print("mean_fare_not_survived = {:03.2f}".format(mean_fare_not_survived))print("std_fare_not_survived = {:03.2f}".format(std_fare_not_survived))
# 下面是结果mean_fare_survived = 54.75std_fare_survived = 66.91mean_fare_not_survived = 24.61std_fare_not_survived = 36.29
让我们看看关于生还和未生还的直方图的结果分布:
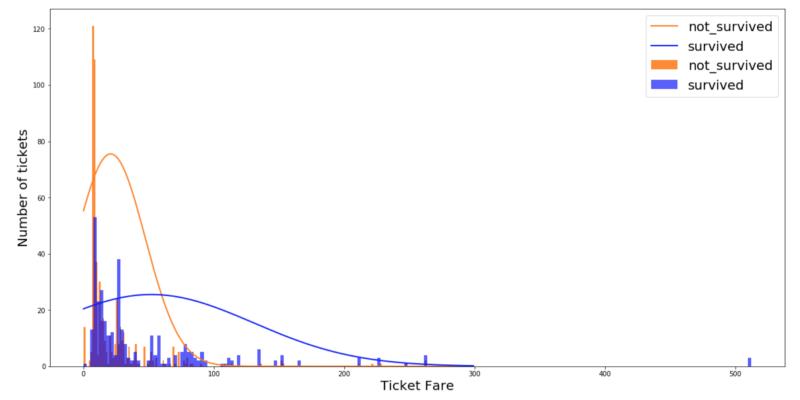
图 1:各个是否生还值的票价直方图和高斯分布(缩放等级并不对应)
可以发现,分布与数据集并没有很好地拟合。在实现模型之前,最好验证特征分布是否遵循上述三种模型中的一种。如果连续特征不具有正态分布,则应使用变换或不同的方法将其转换成正态分布。为了便于说明,这我们将分布看作是正态的。应用式 1 贝叶斯定理,可得以下这个分类器:
图 2:高斯分类器
如果票价分类器的值超过 78(classifier(Fare) ≥ ~78),则 P(fare| Survival = 1) ≥ P(fare| Survival = 0),我们将这个人归类为生还。否则我们就将他归为未生还。我们得到了一个正确率为 64.15% 的分类器。
如果我们在同一数据集上训练 Sklearn 高斯朴素贝叶斯分类器,将会得到完全相同的结果:
from sklearn.naive_bayes import GaussianNBgnb = GaussianNB()used_features =["Fare"]y_pred = gnb.fit(X_train[used_features].values, X_train["Survived"]).predict(X_test[used_features])print("Number of mislabeled points out of a total {} points : {}, performance {:05.2f}%".format(X_test.shape[0],(X_test["Survived"] != y_pred).sum(),100*(1-(X_test["Survived"] != y_pred).sum()/X_test.shape[0])))print("Std Fare not_survived {:05.2f}".format(np.sqrt(gnb.sigma_)[0][0]))print("Std Fare survived: {:05.2f}".format(np.sqrt(gnb.sigma_)[1][0]))print("Mean Fare not_survived {:05.2f}".format(gnb.theta_[0][0]))print("Mean Fare survived: {:05.2f}".format(gnb.theta_[1][0]))
# 下面是结果Number of mislabeled points out of a total 357 points: 128, performance 64.15%Std Fare not_survived 36.29Std Fare survived: 66.91Mean Fare not_survived 24.61Mean Fare survived: 54.75
朴素贝叶斯分类器的优缺点
优点:
计算迅速
实现简单
在小数据集上表现良好
在高维度数据上表现良好
即使朴素假设没有完全满足,也能表现良好。在许多情况下,建立一个好的分类器只需要近似的数据就够了。
缺点:
需要移除相关特征,因为它们会在模型中被计算两次,这将导致该特征的重要性被高估。
如果测试集中,某分类变量的一个类别没有在训练集中出现过,那么模型会把这种情况设为零概率。它将无法做出预测。这通常被称为『零位频率』。我们可以使用平滑技术来解决这个问题。最简单的平滑技术之一称为拉普拉斯平滑。当你训练一个朴素贝叶斯分类器时,Sklearn 会默认使用拉普拉斯平滑算法。
结语
非常感谢你阅读这篇文章。我希望它能帮助你理解朴素贝叶斯分类器的概念以及它的优点。
致谢 Antoine Toubhans、Flavian Hautbois、Adil Baaj 和 Raphaël Meudec。
原文链接:
https://www.sicara.ai/blog/2018-02-28-naive-bayes-classification-sklearn
- EOF -
1、
2、
3、
觉得本文对你有帮助?请分享给更多人
推荐关注「Python开发者」,提升Python技能
点赞和在看就是最大的支持❤️
以上是关于Sklearn 中的朴素贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章