机器学习系列朴素贝叶斯(Naive Bayes)
Posted 数据科学人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习系列朴素贝叶斯(Naive Bayes)相关的知识,希望对你有一定的参考价值。
贝叶斯原理可以解决“逆向概率”问题,解答在没有太多可靠证据的情况下,怎样做出更符合数学逻辑的推测。
正向概率问题:如果袋子里共有N个黑球白球,黑球的数量为M,那么摸一个球是黑球的概率是M/N。
逆向概率问题:如果只知道袋子里有黑球和白球,数量未知,通过摸出来的球的颜色来判断黑球和白球的比例。
先验概率:通过经验来判断事情发生的概率。
后验概率:事情发生之后推测发生原因的概率。
贝叶斯原理就是引入先验概率和逻辑推理来求解后验概率,处理不确定命题的。
目录
一、条件概率
二、贝叶斯定理
三、朴素贝叶斯分类
四、拉普拉斯修正
五、Python代码
六、朴素贝叶斯例子
一、条件概率
条件概率是指事件A在另外一个事件B发生条件下的发生概率,记为 ,计算公式为
二、贝叶斯定理
贝叶斯定理是关于随机事件A和B的条件概率的一则定理,记为
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出
,
则很难直接得出,但我们更关心
,贝叶斯定理就为我们打通从
获得
的道路,将求后验概率的问题转变为求先验概率和条件概率。
下面给大家展示一个更容易理解的贝叶斯定理的讲解,转自知乎用户Jason Huang的一篇介绍贝叶斯定理的文章。
作者是用集合的思想来看贝叶斯定理的,首先把全空间分割成若干集合Bi,如图

接着全空间里还有另外一个集合(事件) A,见图灰色区域
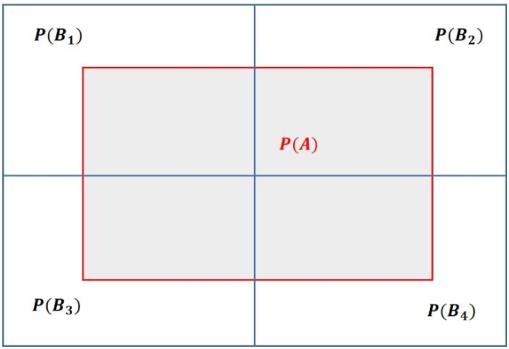
现在全空间可以更加细致的分割为图
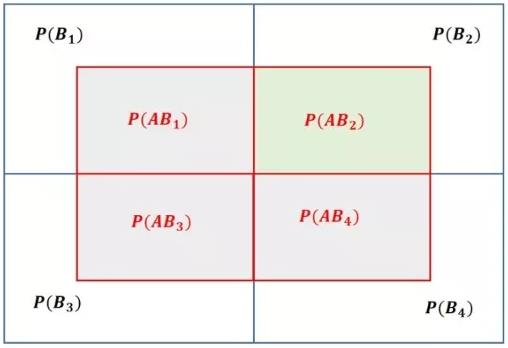
现在考察绿色方块,也就是区域
我们借用物理学中的参考系概念,以全空间为参考系,则事件A和B2发生的概率分别为
上述的概率其实也可以等效于图2中相应的方块面积,但是事件 在不同的参考系下看的结果是不一样的。
如果以 A为参考系(以 A为视角),看待 图片发生的概率(也就是所谓的条件概率)为
我们也可以从B2的视角来看待(关注右上角的方块),得到
于是有了
三、朴素贝叶斯分类
朴素贝叶斯是一种非常简单的用于不同相互独立特征下的分类,对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
基于贝叶斯公式来估计后验概率P( c | x )的主要困难在于:类条件概率P( x | c )是所有属性上的联合概率,难以从有限的训练样本直接估计而得。因此朴素贝叶斯分类器采用了“属性条件独立性假设”:对已知类别,假设所有属性相互独立。也就是说,假设每个属性独立的对分类结果发生影响。
基于属性独立性假设,后验概率P(c|x)中的x往往包含多个相关因素,即它可能有多个需要考虑的属性值x = (x1,x2,…,xn)代表所有相关因素,在信用卡审批中可能是是否有房产,是否有车辆,学历情况,月收入等相关因素, 可写为
这里将P(xi|c)条件联合概率表示成
表示所有条件概率的相乘。
对于离散数据来说,采用统计的方法(频率)来代替概率。而对于连续数据来说,需要把样本的属性看成正态分布,通过训练样本得到正态分布的均值和方差,代入标准公式得到高斯密度函数,标准公式为:
四、拉普拉斯修正
若某个离散类型的属性值在训练集中没有有某个类同时出现过,那么在进行概率计算时就会产生0的结果,不管其他属性怎么取值,最终
Dc表示训练集D中c类样本组成的集合,条件概率公式
拉普拉斯修正避免了因训练集不充分而导致概率估值为零的问题,并且在训练集变大时,修正过程所引入的先验的影响也会逐渐变得可忽略,使得估值渐趋向于实际概率值。
如果数据样本的特征属性之间具有较强的相关性,并不是条件独立的,就会限制朴素贝叶斯分类的能力。
五、Python代码
下面给出一个Python代码的朴素贝叶斯模型,来自LY豪:
import numpy as np
import pandas as pd
dataset = pd.read_csv('watermelon_3.csv', delimiter=",")
del dataset['编号']
print(dataset)
X = dataset.values[:, :-1]
m, n = np.shape(X)
for i in range(m):
X[i, n - 1] = round(X[i, n - 1], 3)
X[i, n - 2] = round(X[i, n - 2], 3)
y = dataset.values[:, -1]
columnName = dataset.columns
colIndex = {}
for i in range(len(columnName)):
colIndex[columnName[i]] = i
Pmap = {} # 函数P很耗时间,而且经常会求一样的东西,因此我加了个记忆化搜索,用map存一下,避免重复计算
kindsOfAttribute = {} # kindsOfAttribute[0] = 3,因为有3种不同的类型的"色泽"
for i in range(n):
kindsOfAttribute[i] = len(set(X[:, i]))
continuousPara = {} # 记忆一些参数的连续数据,以避免重复计算
goodList = []
badList = []
for i in range(len(y)):
if y[i] == '是':
goodList.append(i)
else:
badList.append(i)
import math
def P(colID, attribute, C): # P(colName=attribute|C) P(色泽=青绿|是)
if (colID, attribute, C) in Pmap:
return Pmap[(colID, attribute, C)]
curJudgeList = []
if C == '是':
curJudgeList = goodList
else:
curJudgeList = badList
ans = 0
if colID >= 6:
mean = 1
std = 1
if (colID, C) in continuousPara:
curPara = continuousPara[(colID, C)]
mean = curPara[0]
std = curPara[1]
else:
curData = X[curJudgeList, colID]
mean = curData.mean()
std = curData.std()
# print(mean,std)
continuousPara[(colID, C)] = (mean, std)
ans = 1 / (math.sqrt(math.pi * 2) * std) * math.exp((-(attribute - mean) ** 2) / (2 * std * std))
else:
for i in curJudgeList:
if X[i, colID] == attribute:
ans += 1
ans = (ans + 1) / (len(curJudgeList) + kindsOfAttribute[colID])
Pmap[(colID, attribute, C)] = ans
# print(ans)
return ans
def predictOne(single):
ansYes = math.log2((len(goodList) + 1) / (len(y) + 2))
ansNo = math.log2((len(badList) + 1) / (len(y) + 2))
for i in range(len(single)): # 书上是连乘,但在实践中要把“连乘”通过取对数的方式转化为“连加”以避免数值下溢
ansYes += math.log2(P(i, single[i], '是'))
ansNo += math.log2(P(i, single[i], '否'))
# print(ansYes,ansNo,math.pow(2,ansYes),math.pow(2,ansNo))
if ansYes > ansNo:
return '是'
else:
return '否'
def predictAll(iX):
predictY = []
for i in range(m):
predictY.append(predictOne(iX[i]))
return predictY
predictY = predictAll(X)
print(y)
print(np.array(predictAll(X)))
confusionMatrix = np.zeros((2, 2))
for i in range(len(y)):
if predictY[i] == y[i]:
if y[i] == '否':
confusionMatrix[0, 0] += 1
else:
confusionMatrix[1, 1] += 1
else:
if y[i] == '否':
confusionMatrix[0, 1] += 1
else:
confusionMatrix[1, 0] += 1
print(confusionMatrix)
六、朴素贝叶斯例子
本例子摘自阮一峰的朴素贝叶斯分类器的应用,某个医院早上收了六个门诊病人,如下表:
| 症状 | 职业 | 疾病 |
|---|---|---|
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 建筑工人 | 脑震荡 |
| 头痛 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:
可得
P(感冒|打喷嚏x建筑工人)= P(打喷嚏x建筑工人|感冒) x P(感冒)/ P(打喷嚏x建筑工人)
假定"打喷嚏"和"建筑工人"这两个特征是独立的,因此,上面的等式就变成了
P(感冒|打喷嚏x建筑工人)= P(打喷嚏|感冒) x P(建筑工人|感冒) x P(感冒)/ P(打喷嚏) x P(建筑工人)
这是可以计算的。
P(感冒|打喷嚏x建筑工人)= 0.66 x 0.33 x 0.5 / 0.5 x 0.33= 0.66
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。
参考:
http://www.ruanyifeng.com/blog/2013/12/naive_bayes_classifier.html
https://www.jianshu.com/p/a4ddf754357b
以上是关于机器学习系列朴素贝叶斯(Naive Bayes)的主要内容,如果未能解决你的问题,请参考以下文章