「数据分类」朴素贝叶斯算法
Posted Python编程学习圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「数据分类」朴素贝叶斯算法相关的知识,希望对你有一定的参考价值。
1.贝叶斯公式
一般情况下,令F1,F2,...,FN表示一组互不相容事件,在E(新的证据)已发生的情况下,Fk发生的概率为:
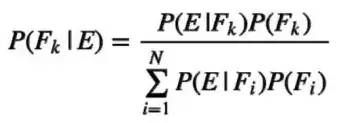
贝叶斯公式
其中:
·P(Fk)称为先验概率(Prior Probability)
·P(E|Fk)称为类似然(Class Likelihood)
·分母称为证据(Evidence)
·P(Fk|E)称为后验概率(Posterior Probability)
2.贝叶斯分类器
假设分类问题有N种类别c1,c2,...,cN,对于一个实例x进行分类时,贝叶斯分类器先根据贝叶斯公式分别计算在x条件下属于各个类别的条件概率,即后验概率:
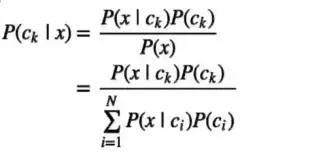
贝叶斯分类器
然后根据后验概率最大化准则(期望风险最小化),将x归为有最大后验概率的类别。
3.三种贝叶斯分类算法:
(1)高斯朴素贝叶斯:sklearn.naive_bayes.GaussianNB()

高斯朴素贝叶斯
【注】
①属性:
·priors属性:默认值为None,获取各个类标记对应的先验概率。可以利用set_params()方法更改该属性的属性值。
>>>gnb.set_params(priors=[0.6,0.4])
GaussianNB(priors=[0.6, 0.4], var_smoothing=1e-09)
·class_prior_属性:与priors属性一样,获取各个类标记对应的先验概率。区别在于priors属性返回列表,class_prior_返回的是数组。
>>> gnb.class_prior_
array([0.625, 0.375])
>>> gnb.priors
[0.6, 0.4]
·class_count_属性:获取各类标记对应的训练样本数.
>>>gnb.class_count_
array([5., 3.])
·theta_属性:获取各个类标记在各个特征上的均值.
>>> gnb.theta_
array([[-3., -3.],
[ 2., 2.]])
·sigma_属性:获取各个类标记在各个特征上的方差.
>>> gnb.sigma_
array([[2.00000001, 2.00000001],
[0.66666667, 0.66666667]])
②方法
·get_params(deep=True):返回priors与其参数值组成字典,deep属性默认值为True.
>>>gnb.get_params(deep=True)
{'priors': [0.6, 0.4], 'var_smoothing': 1e-09}
·set_params(params=[]):设置priors参数.
·fit(x, y, sample_weight=None):训练样本,X表示特征向量,y类标记,sample_weight表各样本权重数组.
·partial_fit(X, y, classes=None, sample_weight=None):增量式训练,当训练数据集数据量非常大,不能一次性全部载入内存时,可以将数据集划分若干份,重复调用partial_fit在线学习模型参数,在第一次调用partial_fit函数时,必须制定classes参数,在随后的调用可以忽略.
·predict(X):直接输出测试集预测的类标记.
·predict_proba(X):输出测试样本在各个类标记预测概率值.
·predict_log_proba(X):输出测试样本在各个类标记上预测概率值对应对数值.
·score(X, y, sample_weight=None):返回测试样本映射到指定类标记上的得分(准确率).
(2)多项式朴素贝叶斯:sklearn.naive_bayes.MultinomialNB(),主要用于离散特征分类,例如文本分类单词统计,以出现的次数作为特征值。
多项式朴素贝叶斯
【注】
①多项式朴素贝叶斯参数:
·alpha:浮点型,可选项,默认1.0,添加拉普拉修/Lidstone平滑参数。
·fit_prior:布尔型,可选项,默认True,表示是否学习先验概率,参数为False表示所有类标记具有相同的先验概率。
·class_prior:类似数组,数组大小为(n_classes,),默认None,类先验概率。
②除高斯朴素贝叶斯算法下注释的属性外,多项式朴素贝叶斯算法还包括的不同属性有:
·class_log_prior_:各类标记的平滑先验概率对数值,其取值会受fit_prior和class_prior参数的影响。
·intercept_:将多项式朴素贝叶斯解释的class_log_prior_映射为线性模型,其值和class_log_propr相同。
·coef_:将多项式朴素贝叶斯解释feature_log_prob_映射成线性模型,其值和feature_log_prob相同。
·feature_log_prob_:指定类的各特征概率(条件概率)对数值,返回形状为(n_classes, n_features)数组【特征的条件概率=(指定类下指定特征出现的次数+alpha)/(指定类下所有特征出现次数之和+类的可能取值个数*alpha)】。
>>> mnb.feature_log_prob_
array([[-2.15948425, -1.46633707, -1.178655 , -1.06087196],
[-1.89711998, -1.60943791, -1.04982212, -1.2039728 ],
[-1.02961942, -1.94591015, -1.54044504, -1.25276297],
[-1.89711998, -1.38629436, -1.2039728 , -1.2039728 ]])
·feature_count_:各类别各个特征出现的次数,返回形状为(n_classes, n_features)数组。
>>> mnb.feature_count_
array([[2., 5., 7., 8.],
[2., 3., 6., 5.],
[9., 3., 5., 7.],
[2., 4., 5., 5.]])
(3)伯努利朴素贝叶斯:sklearn.naive_bayes.BernoulliNB(),类似于多项式朴素贝叶斯,也主要用户离散特征分类,和MultinomialNB的区别是:MultinomialNB以出现的次数为特征值,BernoulliNB为二进制或布尔型特性。
4.贝叶斯应用场景实例:
经常被应用在文本分类中,包括互联网新闻的分类,垃圾邮件的筛选等。
声明:https://www.jianshu.com/p/48ee3eb0820c
以上是关于「数据分类」朴素贝叶斯算法的主要内容,如果未能解决你的问题,请参考以下文章