深入了解 Eureka 架构原理及实现
Posted 平凡人笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入了解 Eureka 架构原理及实现相关的知识,希望对你有一定的参考价值。
Eureka是Netflix开源的一款提供服务注册和发现的产品
注册中心是分布式开发的核心组件之一
而eureka是spring cloud推荐的注册中心实现
Eureka是一个REST (Representational State Transfer)服务
它主要用于AWS云,用于定位服务,以实现中间层服务器的负载平衡和故障转移,我们称此服务为Eureka服务器
Eureka也有一个基于java的客户端组件,Eureka客户端,这使得与服务的交互更加容易,同时客户端也有一个内置的负载平衡器,它执行基本的循环负载均衡。
基础架构图
Eureka提供了完整的Service Registry和Service Discovery实现

Eureka Server:提供服务注册和发现,多个Eureka Server之间会同步数据,做到状态一致(最终一致性)
Service Provider:服务提供方,将自身服务注册到Eureka,从而使服务消费方能够找到
Service Consumer:服务消费方,从Eureka获取注册服务列表,从而能够消费服务
上图中的3个角色都是逻辑角色,在实际运行中,这几个角色甚至可以是同一个项目(JVM进程)中
自我保护机制
自我保护机制主要在Eureka Client和Eureka Server之间存在网络分区的情况下发挥保护作用,在服务器端和客户端都有对应实现
假设在某种特定的情况下(如网络故障), Eureka Client和Eureka Server无法进行通信,此时Eureka Client无法向Eureka Server发起注册和续约请求,Eureka Server中就可能因注册表中的服务实例租约出现大量过期而面临被剔除的危险,然而此时的Eureka Client可能是处于健康状态的(可接受服务访问),如果直接将注册表中大量过期的服务实例租约剔除显然是不合理的,自我保护机制提高了eureka的服务可用性。
当自我保护机制触发时,Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务,仍能查询服务信息并且接受新服务注册请求,也就是其他功能是正常的。
这里思考下,如果eureka节点A触发自我保护机制过程中,有新服务注册了然后网络回复后,其他peer节点能收到A节点的新服务信息,数据同步到peer过程中是有网络异常重试的,也就是说,是能保证最终一致性的。
服务发现原理
eureka server可以集群部署,多个节点之间会进行(异步方式)数据同步,保证数据最终一致性,Eureka Server作为一个开箱即用的服务注册中心,提供的功能包括:服务注册、接收服务心跳、服务剔除、服务下线等。
需要注意的是,Eureka Server同时也是一个Eureka Client,在不禁止Eureka Server的客户端行为时,它会向它配置文件中的其他Eureka Server进行拉取注册表、服务注册和发送心跳等操作。
eureka server端通过appName和instanceInfoId来唯一区分一个服务实例,服务实例信息是保存在哪里呢?其实就是一个Map中:
// 第一层的key是appName,第二层的key是instanceInfoIdprivate final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry = new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
服务注册
Service Provider启动时会将服务信息(InstanceInfo)发送给eureka server,
eureka server接收到之后会写入registry中,服务注册默认过期时间DEFAULT_DURATION_IN_SECS = 90秒。
InstanceInfo写入到本地registry之后,然后同步给其他peer节点,对应方法com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl#replicateToPeers。
写入本地registry
服务信息(InstanceInfo)保存在Lease中,写入本地registry对应方法com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl#register,Lease统一保存在内存的ConcurrentHashMap中,
在服务注册过程中,首先加个读锁,然后从registry中判断该Lease是否已存在,
如果已存在则比较lastDirtyTimestamp时间戳,取二者最大的服务信息,避免发生数据覆盖
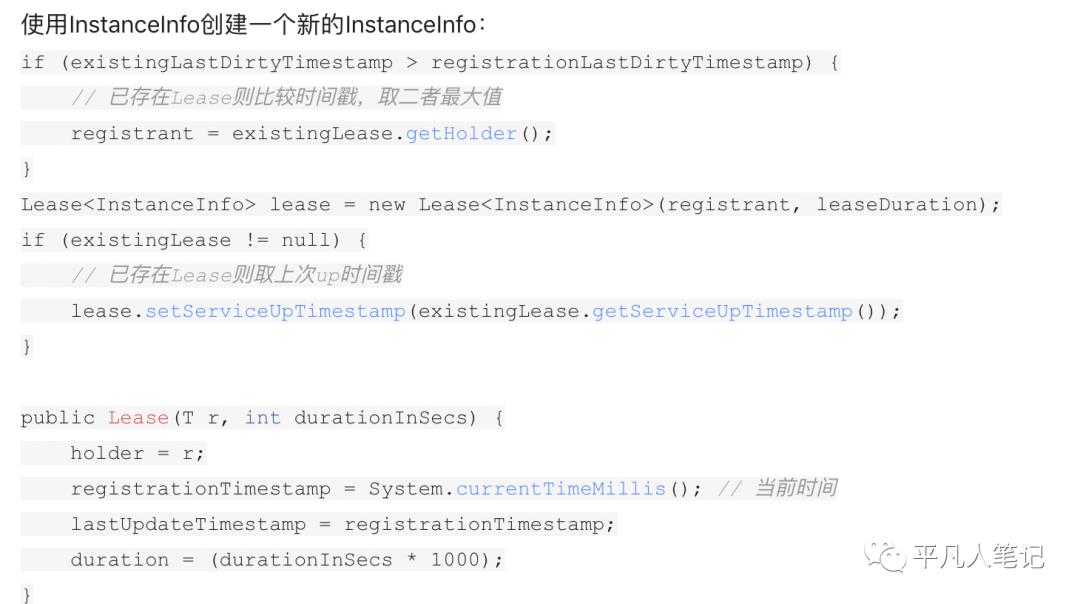
、
通过读锁并且 registry 的读取和写入不是原子的,那么在并发时其实是有可能发生数据覆盖的,如果发生数据覆盖岂不是有问题了?
其实针对这个问题,eureka的处理方式是没有问题的,该方法并发时,针对InstanceInfo Lease的构造,二者的信息是基本一致的,因为registrationTimestamp取的就是当前时间,所以并发的数据不会产生问题。
同步给其他peer
InstanceInfo写入到本地registry之后,然后同步给其他peer节点,对应方法com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl#replicateToPeers。
如果当前节点接收到的InstanceInfo本身就是另一个节点同步来的,则不会继续同步给其他节点,避免形成“广播效应”;
InstanceInfo同步时会排除当前节点。
InstanceInfo的状态有依以下几种:Heartbeat, Register, Cancel, StatusUpdate,DeleteStatusOverride,默认情况下同步操作时批量异步执行的,同步请求首先缓存到Map中,key为requestType+appName+id,然后由发送线程将请求发送到peer节点。
Peer之间的状态是采用异步的方式同步的,所以不保证节点间的状态一定是一致的,不过基本能保证最终状态是一致的
合服务发现的场景,实际上也并不需要节点间的状态强一致。在一段时间内(比如30秒),节点A比节点B多一个服务实例或少一个服务实例,在业务上也是完全可以接受的(Service Consumer侧一般也会实现错误重试和负载均衡机制)。所以按照C(一致性)A(高可用)P(分区容错)理论,Eureka的选择就是放弃C,选择AP。
如果同步过程中,出现了异常怎么办呢,这时会根据异常信息做对应的处理,如果是读取超时或者网络连接异常,则稍后重试;如果其他异常则打印错误日志不再后续处理。
服务续约
Renew(服务续约)操作由Service Provider定期调用,类似于heartbeat。
主要是用来告诉Eureka Server Service Provider还活着,避免服务被剔除掉。
renew接口实现方式和register基本一致:首先更新自身状态,再同步到其它Peer,服务续约也就是把过期时间设置为当前时间加上duration的值。
注意:服务注册如果InstanceInfo不存在则加入,存在则更新;而服务预约只是进行更新,如果InstanceInfo不存在直接返回false。
服务下线
Cancel(服务下线)一般在Service Provider shutdown的时候调用,用来把自身的服务从Eureka Server中删除,以防客户端调用不存在的服务,eureka从本地”删除“(设置为删除状态)之后会同步给其他peer,对应方法com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl#cancel。
服务失效剔除
Eureka Server中有一个EvictionTask,用于检查服务是否失效。
Eviction(失效服务剔除)用来定期(默认为每60秒)在Eureka Server检测失效的服务,检测标准就是超过一定时间没有Renew的服务。
默认失效时间为90秒,也就是如果有服务超过90秒没有向Eureka Server发起Renew请求的话,就会被当做失效服务剔除掉。
失效时间可以通过eureka.instance.leaseExpirationDurationInSeconds进行配置,定期扫描时间可以通过eureka.server.evictionIntervalTimerInMs进行配置。
服务剔除#evict方法中有很多限制,都是为了保证Eureka Server的可用性:
比如自我保护时期不能进行服务剔除操作、过期操作是分批进行、服务剔除是随机逐个剔除,剔除均匀分布在所有应用中,防止在同一时间内同一服务集群中的服务全部过期被剔除,以致大量剔除发生时,在未进行自我保护前促使了程序的崩溃。
eureka server/client流程
服务信息拉取
Eureka consumer服务信息的拉取分为全量式拉取和增量式拉取,
eureka consumer启动时进行全量拉取,运行过程中由定时任务进行增量式拉取,
如果网络出现异常,可能导致先拉取的数据被旧数据覆盖(比如上一次拉取线程获取结果较慢,数据已更新情况下使用返回结果再次更新,导致数据版本落后),产生脏数据。
对此,eureka通过类型AtomicLong的fetchRegistryGeneration对数据版本进行跟踪,版本不一致则表示此次拉取到的数据已过期。
fetchRegistryGeneration过程是在拉取数据之前,执行fetchRegistryGeneration.get获取当前版本号,获取到数据之后,通过fetchRegistryGeneration.compareAndSet来判断当前版本号是否已更新。
注意:如果增量式更新出现意外,会再次进行一次全量拉取更新。
Eureka server的伸缩容
Eureka Server在启动后会调用EurekaClientConfig.getEurekaServerServiceUrls来获取所有的Peer节点,并且会定期更新。
定期更新频率可以通过eureka.server.peerEurekaNodesUpdateIntervalMs配置。
这个方法的默认实现是从配置文件读取,所以如果Eureka Server节点相对固定的话,可以通过在配置文件中配置来实现。
如果希望能更灵活的控制Eureka Server节点,比如动态扩容/缩容,那么可以override getEurekaServerServiceUrls方法,提供自己的实现,比如我们的项目中会通过数据库读取Eureka Server列表。
eureka server启动时把自己当做是Service Consumer从其它Peer Eureka获取所有服务的注册信息。
然后对每个服务信息,在自己这里执行Register,isReplication=true,从而完成初始化。
Service Provider
Service Provider启动时首先时注册到Eureka Service上,这样其他消费者才能进行服务调用,除了在启动时之外,只要实例状态信息有变化,也会注册到Eureka Service。
需要注意的是,需要确保配置eureka.client.registerWithEureka=true。
register逻辑在方法AbstractJerseyEurekaHttpClient.register中,Service Provider会依次注册到配置的Eureka Server Url上,如果注册出现异常,则会继续注册其他的url。
Renew操作会在Service Provider端定期发起,用来通知Eureka Server自己还活着。这里instance.leaseRenewalIntervalInSeconds属性表示Renew频率。默认是30秒,也就是每30秒会向Eureka Server发起Renew操作。
这部分逻辑在HeartbeatThread类中。在Service Provider服务shutdown的时候,需要及时通知Eureka Server把自己剔除,从而避免客户端调用已经下线的服务,逻辑本身比较简单,通过对方法标记@PreDestroy,从而在服务shutdown的时候会被触发。
Service Consumer
Service Consumer这块的实现相对就简单一些,因为它只涉及到从Eureka Server获取服务列表和更新服务列表。
Service Consumer在启动时会从Eureka Server获取所有服务列表,并在本地缓存
需要注意的是,需要确保配置eureka.client.shouldFetchRegistry=true
由于在本地有一份Service Registries缓存,所以需要定期更新,定期更新频率可以通过eureka.client.registryFetchIntervalSeconds配置
为什么要用eureka呢,因为分布式开发架构中,任何单点的服务都不能保证不会中断,因此需要服务发现机制,某个节点中断后,服务消费者能及时感知到保证服务高可用。
从eureka的设计与实现上来说还是容易理解的,SpringCloud将它集成在自己的子项目spring-cloud-netflix中,实现SpringCloud的服务发现功能。
注册中心除了用eureka之外,还有zookeeper、consul、nacos等解决方案,他们实现原理不同,各自适用于不同的场景,可按需使用。
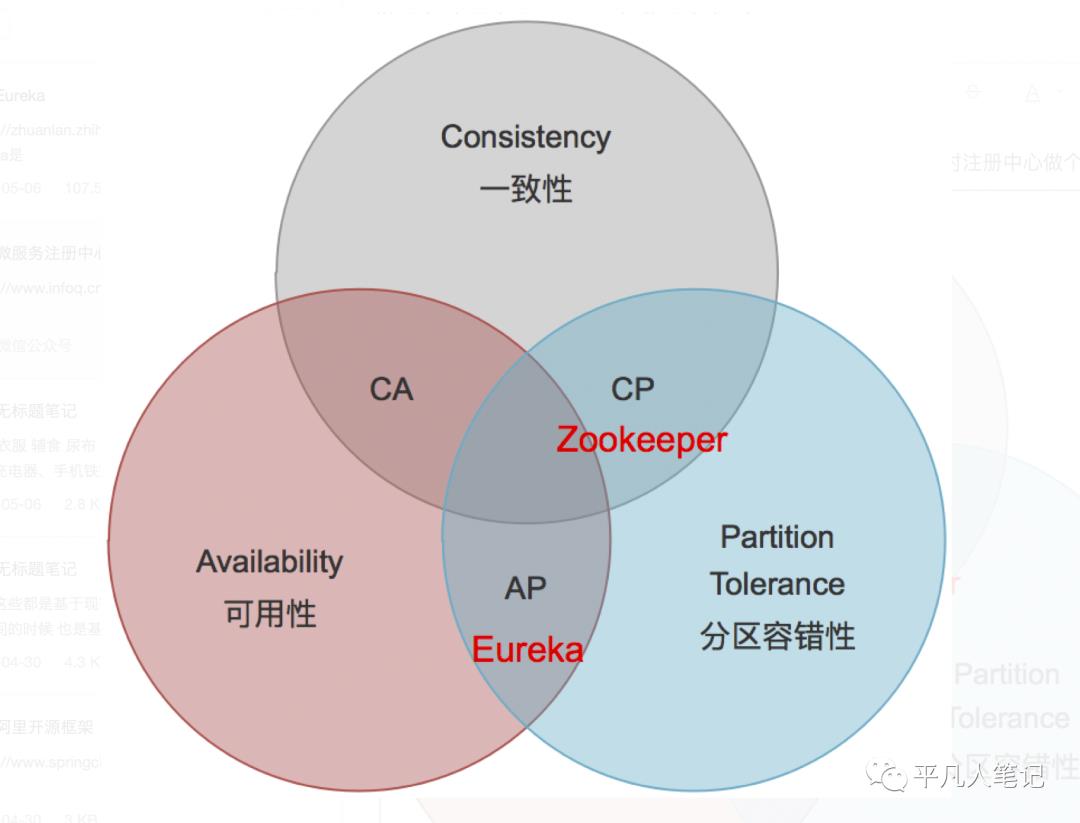
Eureka比ZooKeeper相比优势是什么
Zookeeper保证CP 当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。
但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。
问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。
在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
Eureka保证AP Eureka看明白了这一点,因此在设计时就优先保证可用性。
Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。
而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障。
eureka有哪些不足:eureka consumer本身有缓存,服务状态更新滞后,最常见的状况就是,服务下线了但是服务消费者还未及时感知,此时调用到已下线服务会导致请求失败,只能依靠consumer端的容错机制来保证。
微服务架构中最核心的部分是服务治理,服务治理最基础的组件是注册中心。随着微服务架构的发展,出现了很多微服务架构的解决方案,其中包括我们熟知的 Dubbo 和 Spring Cloud。
关于注册中心的解决方案,dubbo 支持了 Zookeeper、Redis、Multicast 和 Simple,官方推荐 Zookeeper。Spring Cloud 支持了 Zookeeper、Consul 和 Eureka,官方推荐 Eureka。
两者之所以推荐不同的实现方式,原因在于组件的特点以及适用场景不同。简单来说:
ZK 的设计原则是 CP,即强一致性和分区容错性。他保证数据的强一致性,但舍弃了可用性,如果出现网络问题可能会影响 ZK 的选举,导致 ZK 注册中心的不可用。
Eureka 的设计原则是 AP,即可用性和分区容错性。他保证了注册中心的可用性,但舍弃了数据一致性,各节点上的数据有可能是不一致的(会最终一致)。
Eureka 采用纯 Java 实现,除实现了注册中心基本的服务注册和发现之外,极大的满足注册中心的可用性,即使只有一台服务可用,也可以保证注册中心的可用性。
Eureka 总体架构
下面是 Eureka 注册中心部署在多个机房的架构图,这正是他高可用性的优势(Zookeeper 千万别这么部署)。
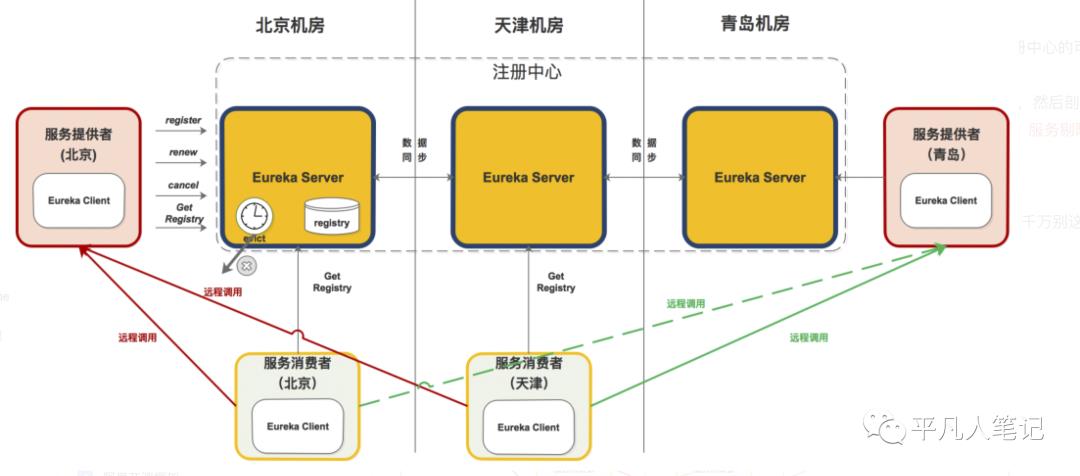
从组件功能看:
黄色注册中心集群,分别部署在北京、天津、青岛机房;
红色服务提供者,分别部署北京和青岛机房;
淡绿色服务消费者,分别部署在北京和天津机房;
从机房分布看:
北京机房部署了注册中心、服务提供者和服务消费者;
天津机房部署了注册中心和服务消费者;
青岛机房部署了注册中心和服务提供者;
组件调用关系
服务提供者
启动后,向注册中心发起 register 请求,注册服务
在运行过程中,定时向注册中心发送 renew 心跳,证明“我还活着”。
停止服务提供者,向注册中心发起 cancel 请求,清空当前服务注册息。
服务消费者
启动后,从注册中心拉取服务注册信息
在运行过程中,定时更新服务注册信息。
服务消费者发起远程调用:
a> 服务消费者(北京)会从服务注册信息中选择同机房的服务提供者(北京),发起远程调用。只有同机房的服务提供者挂了才会选择其他机房的服务提供者(青岛)。
b> 服务消费者(天津)因为同机房内没有服务提供者,则会按负载均衡算法选择北京或青岛的服务提供者,发起远程调用。
注册中心
启动后,从其他节点拉取服务注册信息。
运行过程中,定时运行 evict 任务,剔除没有按时 renew 的服务(包括非正常停止和网络故障的服务)。
运行过程中,接收到的 register、renew、cancel 请求,都会同步至其他注册中心节点。
本文将详细说明上图中的 registry、register、renew、cancel、getRegistry、evict 的内部机制。
数据存储结构
既然是服务注册中心,必然要存储服务的信息,我们知道 ZK 是将服务信息保存在树形节点上。而下面是 Eureka 的数据存储结构:
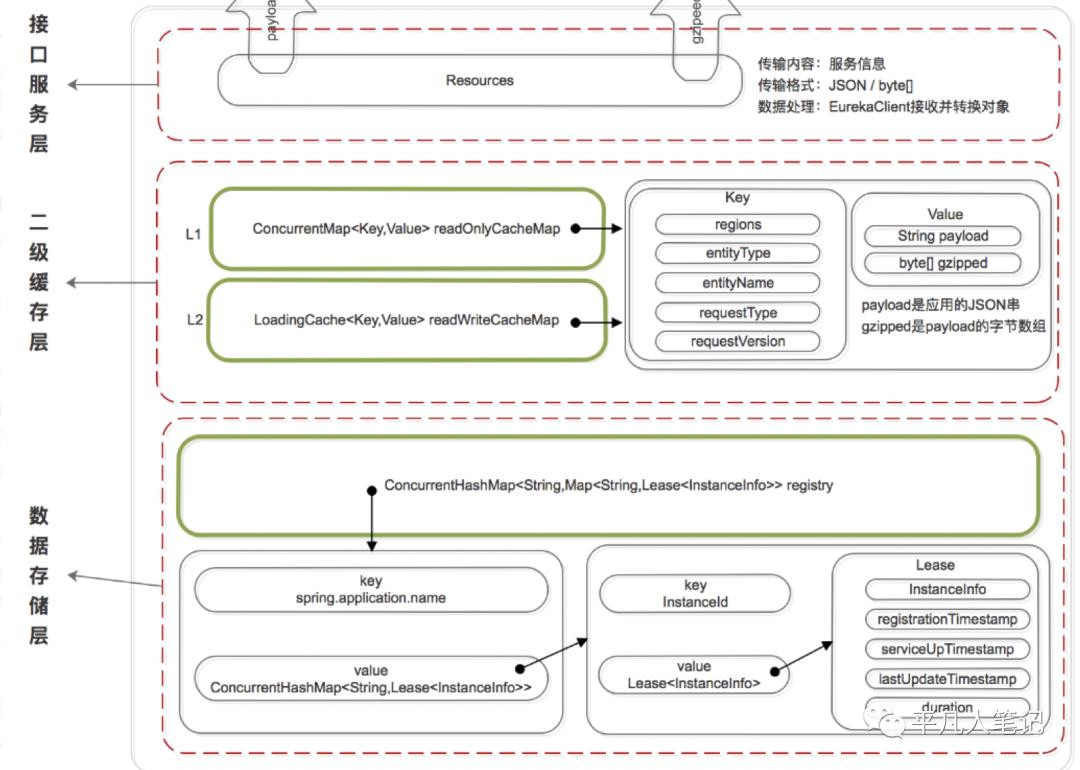
Eureka 的数据存储分了两层:数据存储层和缓存层。
Eureka Client 在拉取服务信息时,先从缓存层获取(相当于 Redis),如果获取不到,先把数据存储层的数据加载到缓存中(相当于 mysql),再从缓存中获取。
值得注意的是,数据存储层的数据结构是服务信息,而缓存中保存的是经过处理加工过的、可以直接传输到 Eureka Client 的数据结构。
Eureka 这样的数据结构设计是把内部的数据存储结构与对外的数据结构隔离开了,就像是我们平时在进行接口设计一样,对外输出的数据结构和数据库中的数据结构往往都是不一样的。
数据存储层
这里为什么说是存储层而不是持久层?因为 rigistry 本质上是一个双层的 ConcurrentHashMap,存储在内存中的。
第一层的 key 是spring.application.name,value 是第二层 ConcurrentHashMap;
第二层 ConcurrentHashMap 的 key 是服务的 InstanceId,value 是 Lease 对象
Lease 对象包含了服务详情和服务治理相关的属性。
二级缓存层
Eureka 实现了二级缓存来保存即将要对外传输的服务信息,数据结构完全相同。
一级缓存:ConcurrentHashMap<Key,Value> readOnlyCacheMap,本质上是 HashMap,无过期时间,保存服务信息的对外输出数据结构。
二级缓存:Loading<Key,Value> readWriteCacheMap,本质上是 guava 的缓存,包含失效机制,保存服务信息的对外输出数据结构。
既然是缓存,那必然要有更新机制,来保证数据的一致性。下面是缓存的更新机制:
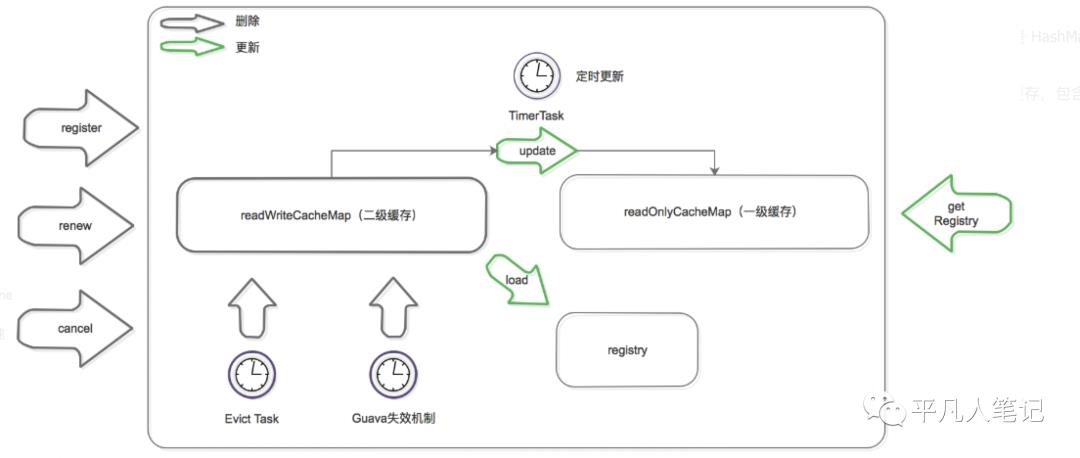
更新机制包含删除和加载两个部分,上图黑色箭头表示删除缓存的动作,绿色表示加载或触发加载的动作。
删除二级缓存:
Eureka Client 发送 register、renew 和 cancel 请求并更新 registry 注册表之后,删除二级缓存;
Eureka Server 自身的 Evict Task 剔除服务后,删除二级缓存;
二级缓存本身设置了 guava 的失效机制,隔一段时间后自己自动失效;
加载二级缓存:
Eureka Client 发送 getRegistry 请求后,如果二级缓存中没有,就触发 guava 的 load,即从 registry 中获取原始服务信息后进行处理加工,再加载到二级缓存中。
Eureka Server 更新一级缓存的时候,如果二级缓存没有数据,也会触发 guava 的 load。
更新一级缓存:
Eureka Server 内置了一个 TimerTask,定时将二级缓存中的数据同步到一级缓存(这个动作包括了删除和加载)。
服务注册机制
服务提供者、服务消费者、以及服务注册中心自己,启动后都会向注册中心注册服务(如果配置了注册)。下图是介绍如何完成服务注册的:
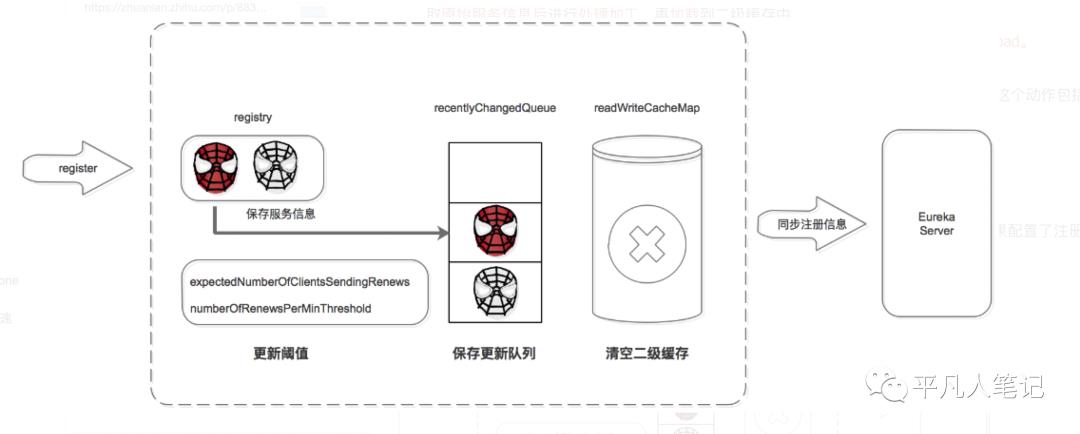
注册中心服务接收到 register 请求后:
保存服务信息,将服务信息保存到 registry 中;
更新队列,将此事件添加到更新队列中,供 Eureka Client 增量同步服务信息使用。
清空二级缓存,即 readWriteCacheMap,用于保证数据的一致性。
更新阈值,供剔除服务使用。
同步服务信息,将此事件同步至其他的 Eureka Server 节点。
服务续约机制
服务注册后,要定时(默认 30S,可自己配置)向注册中心发送续约请求,告诉注册中心“我还活着”。
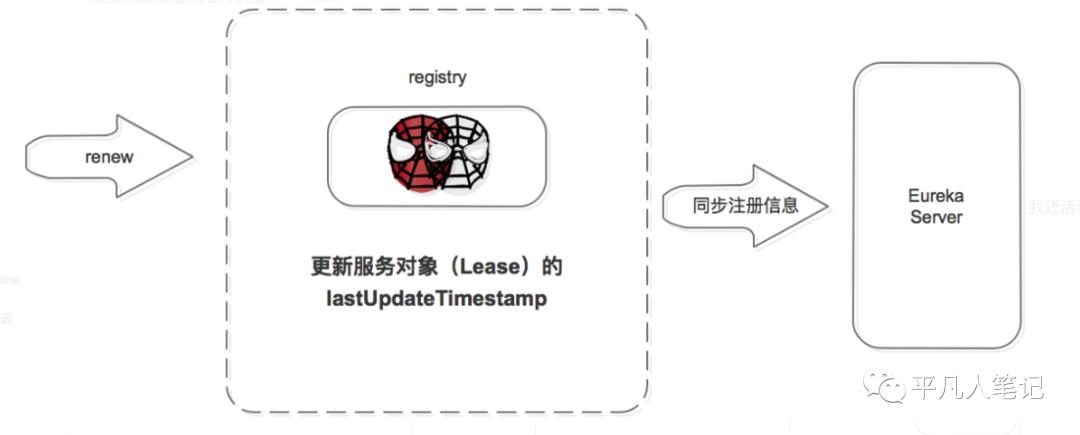
注册中心收到续约请求后:
更新服务对象的最近续约时间,即 Lease 对象的 lastUpdateTimestamp;
同步服务信息,将此事件同步至其他的 Eureka Server 节点。
剔除服务之前会先判断服务是否已经过期,判断服务是否过期的条件之一是续约时间和当前时间的差值是不是大于阈值。
服务注销机制
服务正常停止之前会向注册中心发送注销请求,告诉注册中心“我要下线了”。
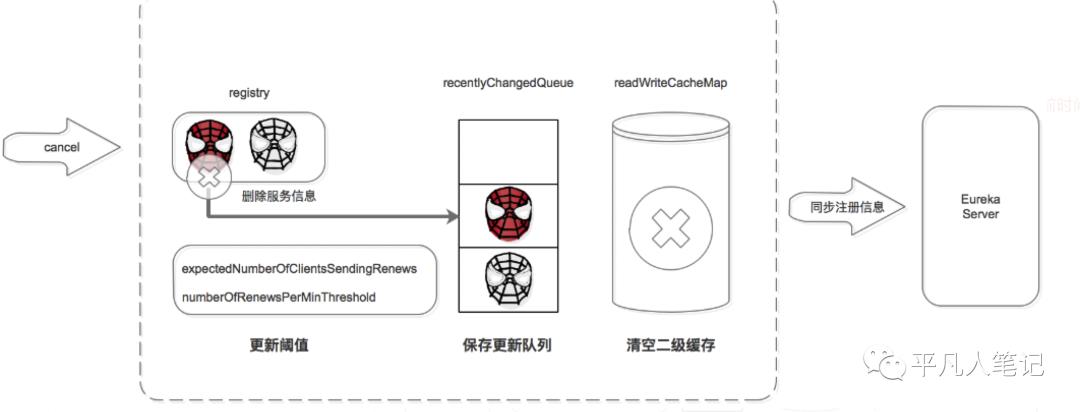
注册中心服务接收到 cancel 请求后:
删除服务信息,将服务信息从 registry 中删除;
更新队列,将此事件添加到更新队列中,供 Eureka Client 增量同步服务信息使用。
清空二级缓存,即 readWriteCacheMap,用于保证数据的一致性。
更新阈值,供剔除服务使用。
同步服务信息,将此事件同步至其他的 Eureka Server 节点。
服务正常停止才会发送 Cancel,如果是非正常停止,则不会发送,此服务由 Eureka Server 主动剔除。
服务剔除机制
Eureka Server 提供了服务剔除的机制,用于剔除没有正常下线的服务。

服务的剔除包括三个步骤,首先判断是否满足服务剔除的条件,然后找出过期的服务,最后执行剔除。
判断是否满足服务剔除的条件
有两种情况可以满足服务剔除的条件:
关闭了自我保护
如果开启了自我保护,需要进一步判断是 Eureka Server 出了问题,还是 Eureka Client 出了问题,如果是 Eureka Client 出了问题则进行剔除。
这里比较核心的条件是自我保护机制,Eureka 自我保护机制是为了防止误杀服务而提供的一个机制。
Eureka 的自我保护机制“谦虚”的认为如果大量服务都续约失败,则认为是自己出问题了(如自己断网了),也就不剔除了;
反之,则是 Eureka Client 的问题,需要进行剔除。
而自我保护阈值是区分 Eureka Client 还是 Eureka Server 出问题的临界值:如果超出阈值就表示大量服务可用,少量服务不可用,则判定是 Eureka Client 出了问题。
如果未超出阈值就表示大量服务不可用,则判定是 Eureka Server 出了问题。
条件 1 中如果关闭了自我保护,则统统认为是 Eureka Client 的问题,把没按时续约的服务都剔除掉(这里有剔除的最大值限制)。
这里比较难理解的是阈值的计算:
自我保护阈值 = 服务总数 * 每分钟续约数 * 自我保护阈值因子。
每分钟续约数 =(60S/ 客户端续约间隔)
最后自我保护阈值的计算公式为:
自我保护阈值 = 服务总数 * (60S/ 客户端续约间隔) * 自我保护阈值因子。
举例:如果有 100 个服务,续约间隔是 30S,自我保护阈值 0.85。
自我保护阈值 =100 * 60 / 30 * 0.85 = 170。
如果上一分钟的续约数 =180>170,则说明大量服务可用,是服务问题,进入剔除流程;
如果上一分钟的续约数 =150<170,则说明大量服务不可用,是注册中心自己的问题,进入自我保护模式,不进入剔除流程。
找出过期的服务
遍历所有的服务,判断上次续约时间距离当前时间大于阈值就标记为过期。并将这些过期的服务保存到集合中。
剔除服务
在剔除服务之前先计算剔除的数量,然后遍历过期服务,通过洗牌算法确保每次都公平的选择出要剔除的任务,最后进行剔除。
执行剔除服务后:
删除服务信息,从 registry 中删除服务。
更新队列,将当前剔除事件保存到更新队列中。
清空二级缓存,保证数据的一致性。
服务获取机制
Eureka Client 获取服务有两种方式,全量同步和增量同步。获取流程是根据 Eureka Server 的多层数据结构进行的:
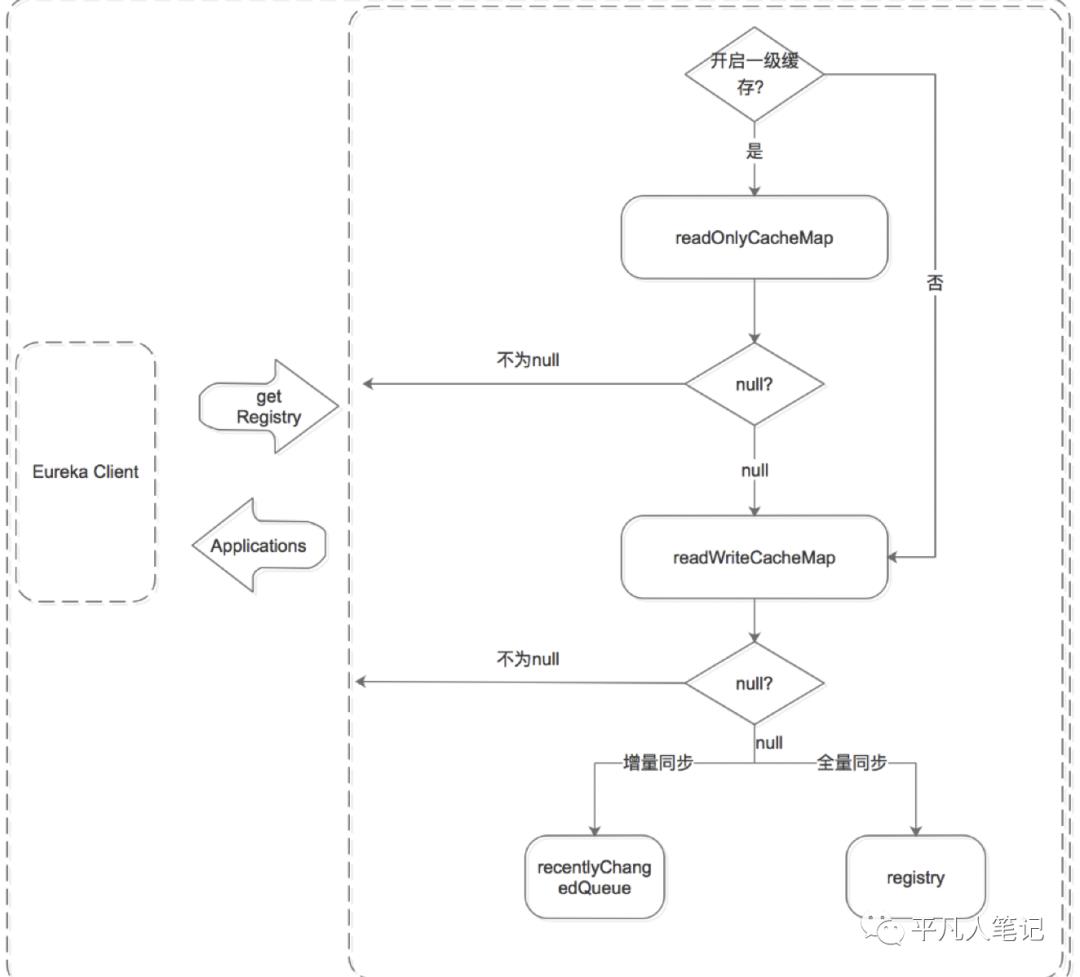
无论是全量同步还是增量同步,都是先从缓存中获取,如果缓存中没有,则先加载到缓存中,再从缓存中获取。(registry 只保存数据结构,缓存中保存 ready 的服务信息。)
先从一级缓存中获取
a> 先判断是否开启了一级缓存
b> 如果开启了则从一级缓存中获取,如果存在则返回,如果没有,则从二级缓存中获取
c> 如果未开启,则跳过一级缓存,从二级缓存中获取
再从二级缓存中获取
a> 如果二级缓存中存在,则直接返回;
b> 如果二级缓存中不存在,则先将数据加载到二级缓存中,再从二级缓存中获取。
注意加载时需要判断是增量同步还是全量同步,增量同步从 recentlyChangedQueue 中 load,全量同步从 registry 中 load。
服务同步机制
服务同步机制是用来同步 Eureka Server 节点之间服务信息的。
它包括 Eureka Server 启动时的同步,和运行过程中的同步。
启动时同步
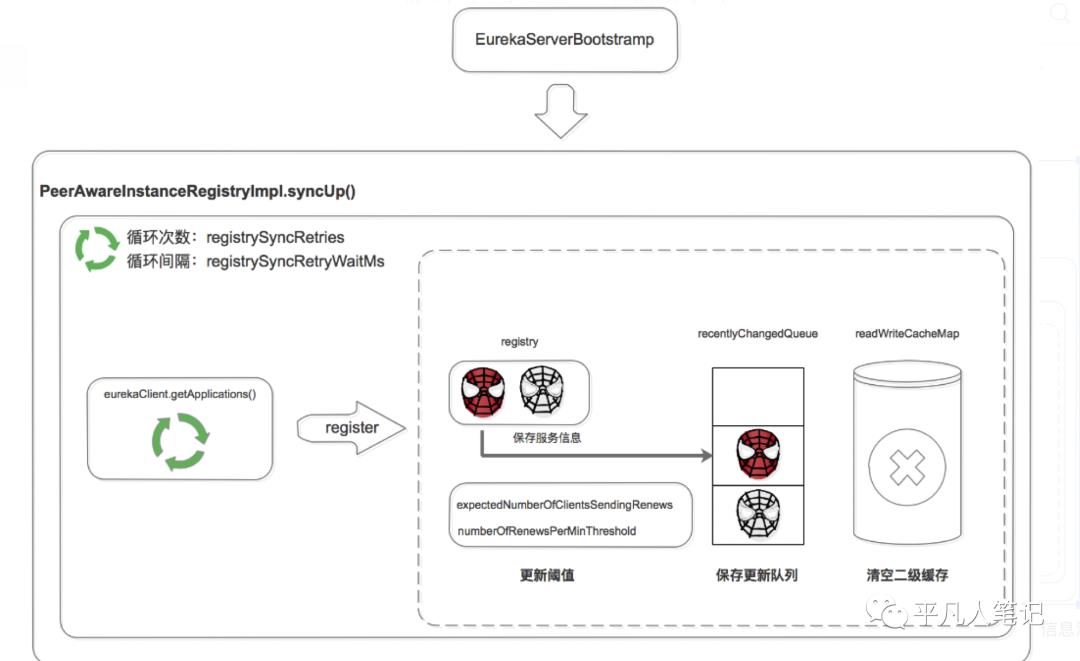
Eureka Server 启动后,遍历 eurekaClient.getApplications 获取服务信息,并将服务信息注册到自己的 registry 中。
注意这里是两层循环,第一层循环是为了保证已经拉取到服务信息,第二层循环是遍历拉取到的服务信息。
运行过程中同步

当 Eureka Server 节点有 register、renew、cancel 请求进来时,会将这个请求封装成 TaskHolder 放到 acceptorQueue 队列中,然后经过一系列的处理,放到 batchWorkQueue 中。
TaskExecutor.BatchWorkerRunnable是个线程池,不断的从 batchWorkQueue 队列中 poll 出 TaskHolder,然后向其他 Eureka Server 节点发送同步请求。
这里省略了两个部分:
一个是在 acceptorQueue 向 batchWorkQueue 转化时,省略了中间的 processingOrder 和 pendingTasks 过程。
另一个是当同步失败时,会将失败的 TaskHolder 保存到 reprocessQueue 中,重试处理。
对微服务解决方案 Dubbo 和 Spring Cloud 的对比非常多,这里对注册中心做个简单对比。
Zookeeper |
Eureka |
|
设计原则 |
CP |
AP |
优点 |
数据强一致 |
服务高可用 |
缺点 |
网络分区会影响 Leader 选举,超过阈值后集群不可用 |
服务节点间的数据可能不一致;Client-Server 间的数据可能不一致; |
适用场景 |
单机房集群,对数据一致性要求较高 |
云机房集群,跨越多机房部署;对注册中心服务可用性要求较高 |
实现
1、pom依赖

2、配置文件

3、启动类
4、访问启动页
参考文章:
https://www.infoq.cn/article/jlDJQ*3wtN2PcqTDyokh
https://zhuanlan.zhihu.com/p/88385121
以上是关于深入了解 Eureka 架构原理及实现的主要内容,如果未能解决你的问题,请参考以下文章