Netty-网络IO模型
Posted 架构师的历练
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netty-网络IO模型相关的知识,希望对你有一定的参考价值。
虽然目前的容器化微服务平台Avatar是基于k8s进行搭建,但对于小型私有云部署来说,虚机的微服务方案依然有其存在的意义(私有云方案常常是个位数Node的搭建,比如4~5个,在这上面部署一套K8完整方案,说实话是有点重型了),因此,对于Spring Cloud、Dubbo这类常用的基于虚机的微服务框架,也是需要经常去github上面关注一下其更新进展。
Avatar平台在正式上线的这段时间里,有一半精力都花在定位网关和与之相关的网络问题上面(问题现象是时不时会出现超时的情况,最终通过优化网络流量模型得以彻底解决),在这过程中,我发现,无论是Spring Cloud的Zuul、Dubbo的底层通信框架、Hadoop的Avro,以及业界许多主流的RPC框架,底层都是基于Netty来构建,包括很多业务网关也常用netty+ajax来搭建。那么,作为开发者,我们就很有必要来深入解析Netty。
说个题外话,上周面试了一位服务过国内很多著名ICT公司,做过省内著名互联网公司CTO助理的一名高端架构师,可能是因为在面试过程中,我刨根问底地问了很多简历中提到的技术实现方案(如就近接入、灰度部署、分布式事务、多数据中心容灾等等),应聘者有些恼羞成怒,抛下一句,“这些问题都问得太细节,我都不屑于回答”。好吧。。。可能是我的问题,但我认为,对技术细节和原理的掌握,也是一个架构师设计一个成功架构的基石之一。
一、我们先来介绍一下Linux网络IO模型
Linux的内核将所有外部设备都看做一个文件,操作时会调用内核命令并返回一个fd(file descriptor),我们称之为文件描述符,是一个无符号整数。其数量取决于内存、int大小的定义和系统设定,一个进程的最大打开文件描述符可通过ulimit -n来查看,并且可以修改。而对一个socket的读写也会有相应的描述符,称为socketfd。
根据Unix网络编程对于IO模型的分类,Unix提供了5种IO模型:
1、阻塞IO模型:在缺省情况下,所有文件操作都是阻塞的。以socket为例,调用recvfrom,其内核调用直到数据包到达且被复制到buffer中或发生错误时才返回,在此期间一直会等待,进程在从调用revcfrom开始到它返回的整个期间内都是阻塞的。
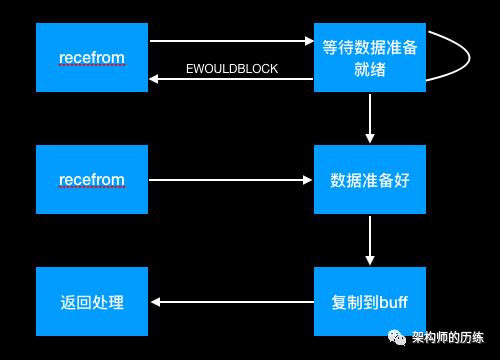
2、非阻塞IO模型
recvfrom从应用层到内核的时候,如果buffer区没有数据,就直接返回EWOULDBLOCK错误,需要应用轮循查询buffer是否有数据。
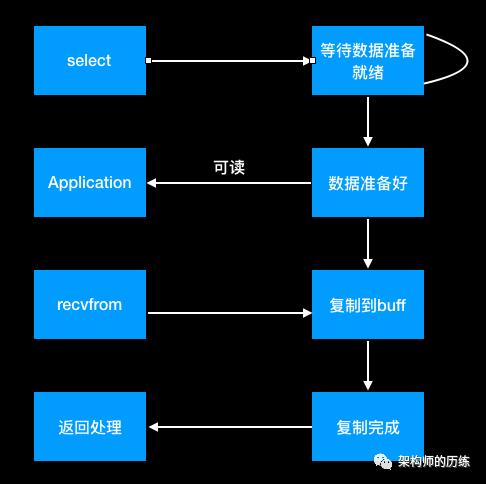
3、IO复用模型
Linux提供select/poll,进程通过将一个或多个fd传递给select或poll调用,阻塞在select操作上,这样select/poll可以侦测多个fd是否处于就绪状态。select/poll顺序扫描fd,Linux还提供了一个epoll,使用基于事件驱动方式代替顺序扫描,性能会好于顺序扫描。
4、信号驱动IO模型
首先创建socket,并通过sigaction执行信号处理函数,此系统调用立即返回,进程继续工作。当数据准备就绪时,就为该进程生成一个SIGIO信号,通过信号回调通知应用程序调用recvfrom来读取数据,并通知主循环函数处理数据。
5、异步IO模型
它与信号IO模型的主要区别是:信号驱动IO由内核通知我们何时可以开始一个IO操作,异步IO由内核通知我们IO操作何时已经准备好。
二、IO多路复用技术
当需要同时处理多个客户端请求时,可用基于多线程或者IO多路复用技术进行处理。IO多路复用技术原理是通过将多个IO的阻塞复用到一个select的阻塞上,从而使得系统在单线程情况下可以同时处理多个客户端请求。与传统的多线程模型相比,最大的优势是系统开销小,系统不需要额外创建多个线程,也减少了线程之间的切换,提升系统总体的响应速度。
目前支持IO多路复用的有select、poll、epoll。但select存在一些限制:
1、比如单个进程打开的FD是有一定限制的,由FD_SETSIZE设置,默认值为1024,对于需要成千上成连接的大型服务来讲,显然比较少,虽然可以修改,但会带来性能的下降。业界也常采用Apache的多进程方案,但如果涉及进程间同步数据,需要进程之间通过socket或共享内存同步,增加了编码的复杂度。而epoll所支持的上限是OS的最大文件句柄数,一般远远大于1024。
2、select的另一个问题,是当socket较多时,每次扫描都会顺序扫描全部集合,导致效率下降,特别是只有少数socket活跃的时候。而epoll是根据每个fd上的callback实现,效率就要高得多。
epoll只是一种实现方案,在freeBSD下有kqueue。
三、Netty的IO模型
在jdk 1.4之前,java只提供了BIO,当时的很长一段时间里,大型服务器都基于c++开发,因为c++可以基于OS能力自己设计和开发异步I/O能力。1.4之后,java提供了NIO;1.7之后,java提供了AIO。
BIO:采用BIO模式的server,通常由一个独立的Acceptor线程负责监听client的连接,它接收到client连接请求之后,为每个client创建一个新的线程进行处理,处理完成之后,应答client。这个模型最大的问题就是缺少弹性伸缩能力,当client访问增加时,server的线程个数和client并发的数量呈现1:1正比关系,最终导致创建新线程失败,进程宕机。
NIO:所有的数据都是缓冲区处理,缓冲区是一个字节数据ByteBuffer,包括读写。NIO提供了SocketChannel,网络请求通过channel进行读写,channel是全双工的。selector多路复用器是NIO的基础,它会不断地轮询注册其上的Channel,如果某个Channel上面发生了读或写事件,这个Channel就处于就绪状态,会被select轮询出来,一个selector可以轮循多个channel。
一个典型的NIO server流程是:
1、当client的请求上来时,会建立一个channel与之对应并注册到selector上面,并监听accept事件。
2、selector轮循多个channel准备就绪的key。
3、若某个channel发生IO时,则将数据读取到buffer中,并投递到业务线程池中去处理。
Netty是基于BIO模型的,是业界最流行的NIO框架之一,若Servier需要实现NIO编程,建议直接基于Netty进行开发,尽量不要自己基于原生java NIO去实现。
以上是关于Netty-网络IO模型的主要内容,如果未能解决你的问题,请参考以下文章