从 Scala 迁移到 Go,永不回头
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从 Scala 迁移到 Go,永不回头相关的知识,希望对你有一定的参考价值。
#点击图片,报名深圳源创会#
OSC-协作翻译
原文:Making the move from Scala to Go, and why we’re not going back
链接:https://movio.co/blog/migrate-Scala-to-Go
译者:Tocy, 无若, butta, 被盗用户, WeiXiaodong
这篇博客文章自发布以来受到了广泛的关注,已出现在 Hacker News、Golang Weekly 和 Scala Times 各大社区,感谢大家!有读者认为这篇文章是对 Scala 的攻击,但并不是这样的。正如文中所解释的,Movio 使用 Scala;一些小型开发团队使用 Scala 作为主语言。 我们两年前也曾经主持过 Scala Downunder。Scala 社区在过去 4 年里教给我们很多知识。因此,Scala 和 Go 在 Movio 中是共存的。
文中我们简述了选择从 Scala 迁移到 Go 的原因及将 Scala 代码库重写到 Go 的内情。 作为一个整体,Movio 要接受各种不同的观点,在这篇文章中的“我们”仅是一方观点的持有者。不可否认,Scala 仍然是 Movio 的一些小组的主语言。
为什么我们首选 Scala?
是什么使得 Scala 如此有吸引力? 如果你看一下我们的发展背景,这就很容易解释了。下面是一些人随着时间的推移对所喜爱的语言的连续变化:
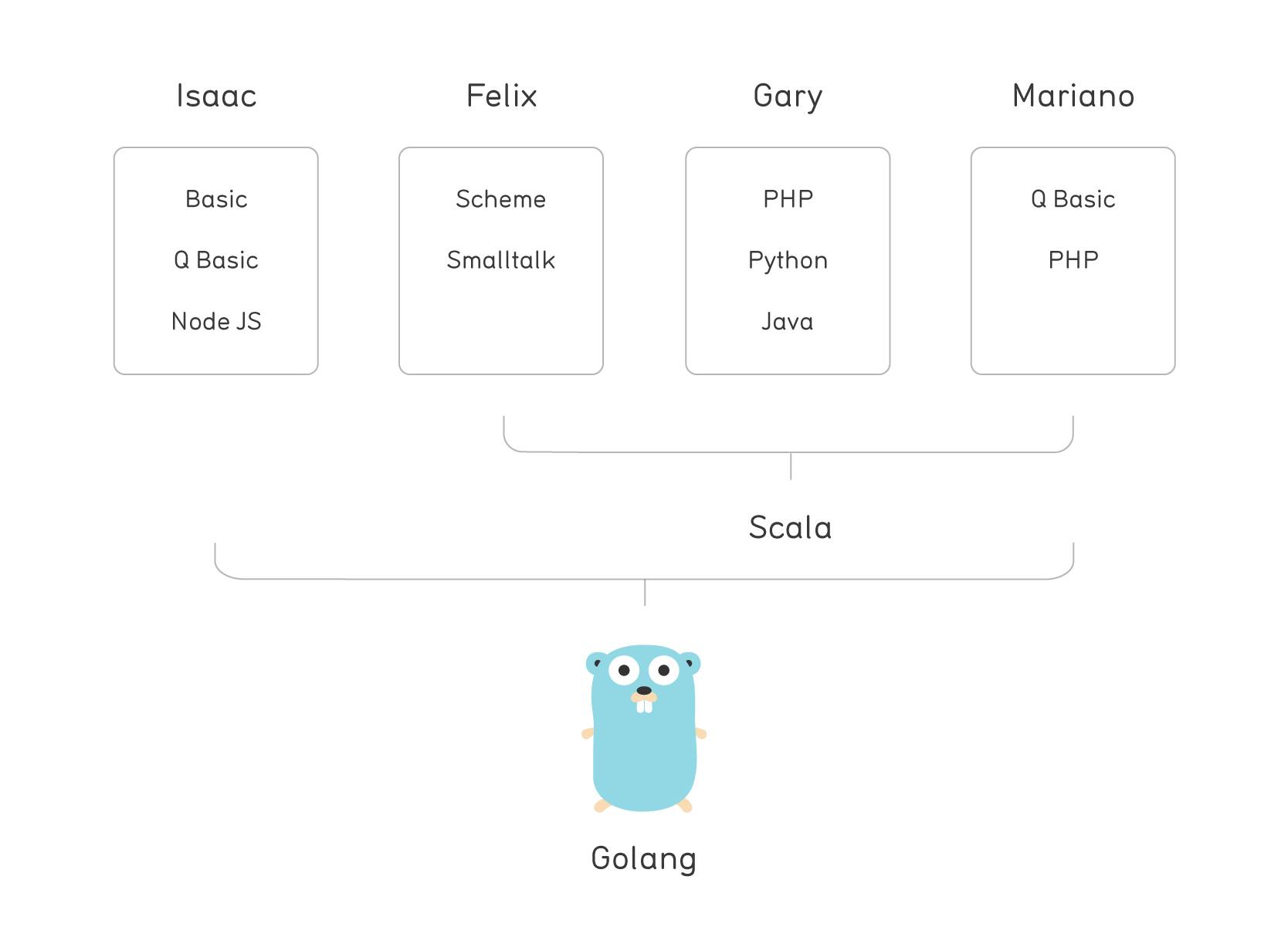
正如你所看到的,我们大部分来自不断变化的程序世界。
随着 Scala 的出现,函数式编程开始热起来。纯函数使确定性测试变得容易,然后 TDD 得到普及,用以检测我们的软件质量问题。
我认为我第一次看到类型系统的积极一面是在 Scala 上。就个人而言,经历无数的 php 静默错误和一些奇怪行为后,有了支持类型检查和妥当的测试,代码终于能正常运行。除此之外,它要在重构之后继续之前的工作,否则会破坏类型检查或测试用例。虽然 Java 也能提供这些功能,但并没有 FP 的优雅,却拥有所有的 EE 的麻烦。
Scala 还有一些特质。它允许你创建自己的运算符或覆盖现有运算符,本质上是具有非字母数字标识符的一元和二元函数。您还可以通过宏(供编译器调用的用户定义函数)来扩展编译器,并通过隐式类(也称为“pimp库”模式)来丰富第三方库。
但 Scala 也有它自身的问题。
慢编译
Martin Odersky 曾提出的一个话题承认并彻底描述了 Scala 编译器的慢,并为此感到沮丧。与庞然大物和复杂的依赖关系树结合,这是一个复杂的解决机制 —— 之后几年里,工程师们就像保姆照顾婴儿那样看护着它 —— 在核心模块中添加一个模型类,这是一次休整,但利弊共存。最重要的是,编码的反馈时间会变得难以接受。(例如:代码测试重构在迭代间延迟)。
慢部署
缓慢的编译时间和一个庞然大物会导致缓慢 CI,反过来,就导致了冗长的部署。幸运地是,聪明的工程师可以并行在不同的节点上测试,把整体上的 CI 时间从一个小时压低到 20 分钟。结果很成功,但在敏捷部署上还是存在问题。
Tooling(工具集)
IDE 支持很差。 Ensime 在多个 Scala 版本项目(在不同模块上的不同版本)上存在的问题使得导入、非 grep 型跳转到定义等的优化无法实施。这意味着所有开源和社区驱动的 IDE(例如 Vim、Emacs、Atom)都会有不太理想的特性集。这种语言似乎太复杂,而不能创建工具集!
Scala 集成也尝试进行多个项目构建,最引人注目的是 Jetbrains 的 Intellij Scala 插件,它支持跳转到定义,允许我们跳转到旧版 JAR 包,而不是已修改的文件中。我们可以使用高级语言特性查看已破坏的高亮显示。
从积极的一面来看,我们只要根据笔记本电脑的散热板的响度,就能准确地判断该程序员使用的是 IDEA 还是 sbt。但对于 MacBook Pro 用户来说,散热非常耗电,不能没有电源插座。
在全球 Scala 社区的发展(以及非 Scala 社区)
对面向对象的批评由来已久,但真正进入人们视线是在 Lawrence Krubner 发布博文之后。从那以后,选择非面向对象语言的想法开始被接受。
我们中就有好几个成员一度在学习 Haskell。
Coda Hale 发给 Scala team 的邮件“Yammer 放弃 Scala”在 2011 年引起轰动,虽然消息陈旧,但当大家观念发生转变后,就会发现 Coda Hale 说的很有道理。参考以下叙述:
“因为有些内容只有库作者需要理解,部分的复杂度已经被移除了。但是当一个库的 API 牵涉到所有的复杂度时(因为大部分的功能在调用空间中解决细节问题),工程师就需要对库运行的机制和转变成 cargo-culting 代码片段的设计模型有一个精确地认识。”
从那时起,大玩家也纷纷加入,比如 Twitter 和 LinkedIn。
以下是 Raffi Krikorian 在 Twitter 上发布内容的引用:
“与四年前不同,这次我使用 Java 作为重写的部分,而不是 Scala。 [...] 一位工程师需要花两个月的时间才能充分高效率编写 Scala 代码。“
Paul Phillips 离开 Scale 的核心团队,他在一次长谈中对它进行了讨论,并绘制了一个恼人的语言状态图 - 与我们已知的形象形成鲜明的对比。
其中恼人的原因,你可以在这个 JSON AST 辩论中找到 Scala 社区的所有先驱。 读完之后的感觉就像这样:

需要一个替代品
在“Go”进入公众视野前,似乎没有真正可以替代 Scala 的语言。看看 Coursera 博客文章“为什么我们爱 Coursera 中的 Scala?”的节选:
“我个人发现编译和加载时间是可以接受的(它没有 PHP 编辑测试循环那么紧凑,但是相比于 Scala,我们可以接受其中的类型检查和其他细节)。”
这是另一个来自同一个博客的节选:
“Scala 确实很慢。并且,动态语言要求你不断地重新运行或测试代码,直到找出所有类型错误、语法错误和 null 反向引用。 ”
为什么 ‘Go’ 有意义
易于学习
我们当中的一些人在 下班后的MOOC 上用6个月时间来学好 Scala ,而重新拾起“Go” 只要两周。实际上,我们第一次接触 Go 代码是在十个月前的一个 Code Retreat 上,那个时候我就能编写一个非常简单的 类似马里奥的游戏 了。
我们总是害怕低级语言,它们会强迫我们处理不必要的复杂层,其实这些只是在高级抽象的 Scala 中被隐藏了,例如:Futures 隐藏了 signal(信号),syscall(系统调用)和 mutexe(互斥器),不过这对于所谓的全栈开发者来说可能并不算什么事。
自古以来,当我们不确定怎么让某些东西工作的时候就会阅读 语言规范。很简单对吧,规范很好懂的!对于我这样的普通人来说意义非凡。我对 Scala(和 Java) 不满意的是看不到一个问题的完整上下文,因为它太复杂了。在看代码时,一份亲切完整的指导手册应该能在我对语言进行臆测时给我信心,并成为印证我决断正确与否的准则。
越简单的代码越易读
没有 map,没有 flatMap,没有 fold,没有泛型(generics),没有继承(inheritance)......我们是错过了他们吗?而让我们去做,大概只要两周。
我们一时半会说不清为何它在没有借鉴 Go 的情况下,也具有良好的表现力。但无论如何,Russ Cox,Golang 的领导者在 “Go 的平衡” 上做得很好(详情请看他在 2015 年写的 keynote)。
事实证明,在没有约束的情况下写出的代码,会让他人难以理解,无法把握其中的逻辑。反过来说,有人也会因为理解了别人无法理解的代码而自命不凡。但从动力学上来看,这种公开考量智力的事并不利于团队的发展,而当复杂的代码出现时,这种情况又在所难免。
从代码复杂性的角度来说,这不仅仅针对我们的团队;很多非常聪明的人都会这样做(持续去做)直到走向极端。有趣的是,因为在 Scala-land(也包括 Java-land)上依赖地狱无处不在,在我们最终使用一些工程的时候,我们就会觉得我们的代码库太复杂(例如:scalaz)了,因为它们出现了传递依赖。
这些例子随机选自我们使用(持续维护)的 Scala 库:
Strong Syntax
(你能明白文件的目的是什么吗?)
Content Type
(在 Github 上已经停止维护)
Abstract Table
(你能给我解释一下外键的签名吗?)
Channels 和 goroutine 让工作变得如此简单
Channel 和 goroutine 在 资源管理上比基于 Future 和 Promise 的线程池更轻,这是不争的事实。编码时也更容易理解。
总结一下,我认为两种语言基于两种不同的方式基本上做了一样的工作,最后目的是一样的。“Go”简单的原因可能是它的工具集有限,你在反复使用之后就掌握了。而 Scala 的选项演变频繁,很难精通它的技术。
案例学习
近期,我们一直在努力解决一个问题,其中我们不得不处理一些账单信息。
数据通过流发送,并且必须持久保存到 MariaDB 数据库中。由于高速数据的开销,直接持久保存是不切实际的,我们不得不使用缓存和聚合,并且在缓冲区满或超时之后持久保存。
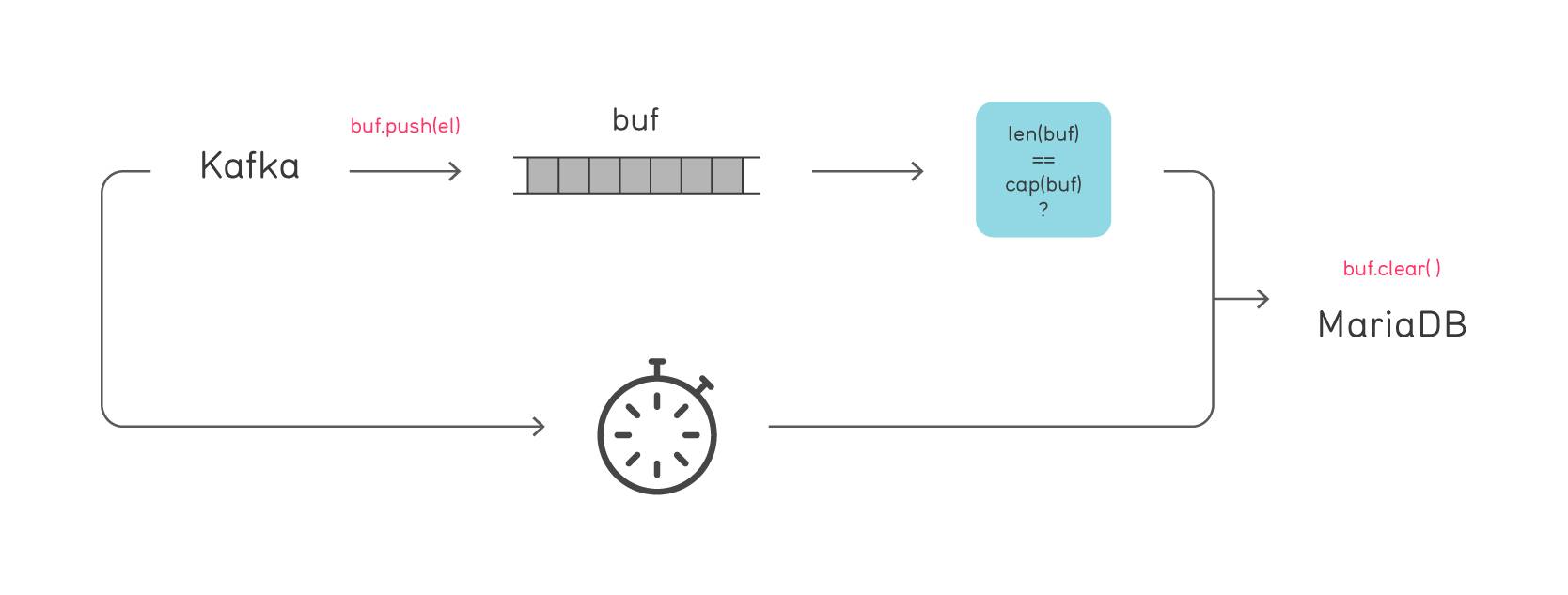
首先,我们犯了一个在同步模式下调用 'persist' 函数的错误。这保证了基于缓冲区满的调用不会与基于超时的调用并发执行。但因为流处理和 `persist` 函数确实是并发运行并且操纵了缓冲区,我们不得不同步这些函数!
最终,我们诉诸 Actor 系统,毕竟我们的模块依赖中仍然有 Akka,并且它确实做了工作。我们只需要确保添加到缓冲区和清除缓冲区是由同一个 Actor 处理的消息即可,这样就永远不会并发运行。但要做到这样子我们需要:学习 Actor 系统,教新手导入这些依赖,在代码和配置文件中正确配置 Akka 等。此外,流来自 Kafka Consumer,在我们的包装器中,我们需要为在“Future”中运行的每个消费消息提供一个 `digest` 函数。避免混淆 Futures 和 Actors 的问题需要额外的考虑时间。
进入通道。
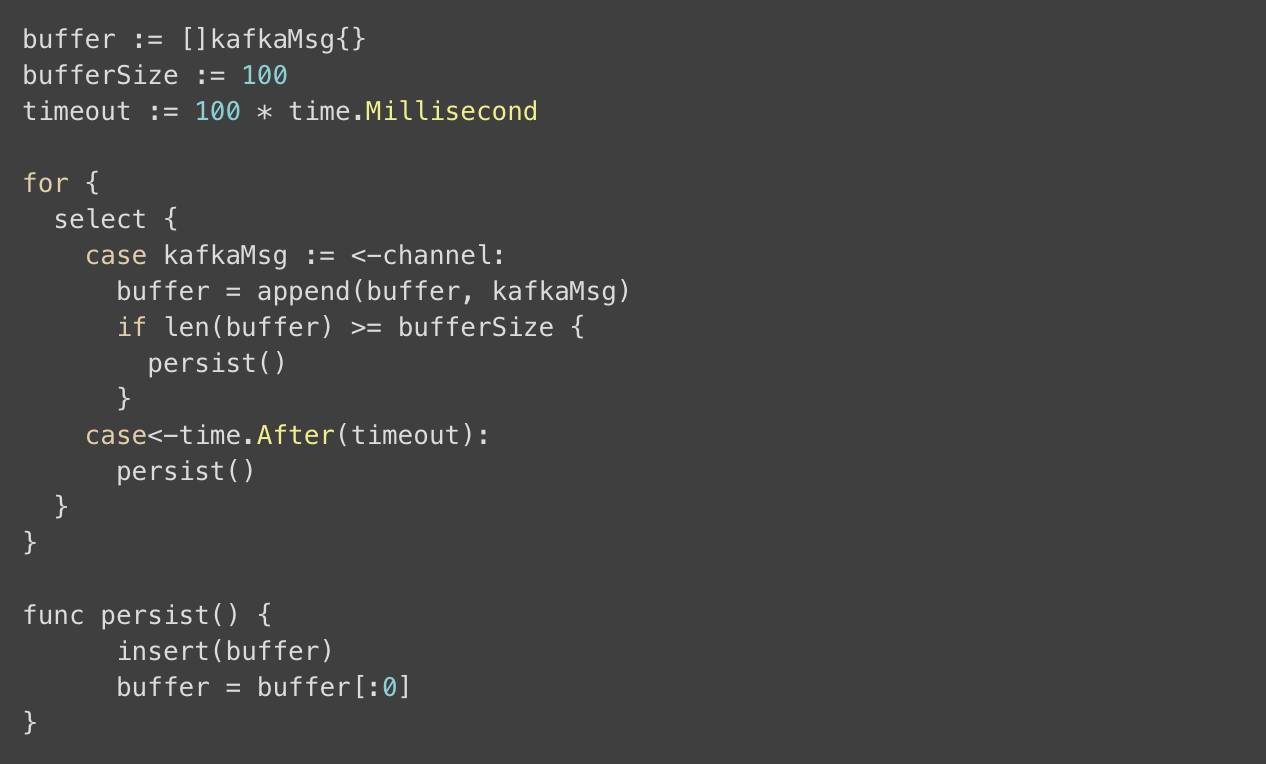
完成;Kafka 将数据发送给通道处理。消耗流和持续缓存的持久不会同时运行,并且在没有收到消息超过 100ms 之后,定时器将被重置。
进一步阅读,几个说明性频道示例:
有序输出的并行处理
服务器端背压的简单处理策略
它编译快,运行也快
Go 的运行速度很快。
我们的 Go 微服务目前:
● 可在 5s 或更短时间内构建
● 在 1-2 秒内测试(包括集成测试)
● 输出一个 Docker 容器,在 CI 基础架构中不超过半分钟
● 在 10 秒或更短时间内部署(通过 Kubernetes)新容器(关键因素是使用小图像)
每秒的反馈循环能使有效提升工作效率。
微服务的灵丹妙药:开发完成后一分钟内部署到简单的平台
我们发现 Go 微服务非常适合分布式系统。
可从以下需要来考虑它有多适合:
● 小型容器:我们的 Go docker 容器平均大小是 16.5MB,Scala 是 220MB
● 低内存占用:方式可能会有不同;最近,我们取得了一个重大的成功就是在一个很糟糕的场景使用中, 实现了一个重要的每毫秒(μs)内存占用从 Scala 的 4G 变为 Go 所需的 300M
● 快速开启及快速关闭:只需一个可执行文件;并不需要启动一个虚拟机
臃肿的 Scala 镜像文件除了在云服务上花费很高,更关键的是部署到容器会产生延迟。重新计划一个 Kubernetes 节点的容器需要从一个已注册的点重新拉取镜像;镜像越大,花费的时间就越大。更不用说要把最新的镜像拉到我们本地的笔记本中
最后:工具
现在已经有很多 IDE 了:
Go都能用!工具正在抓紧时间稳步改善,新工具也在不断出现。
但是我个人最希望我们的 GO 能够崛起:我们要有我们自己的工具!
下面是一些我们开源项目常用的工具:
kt
Kafka 用来生产、消费和获取Kafka主题信息的工具,和jq组合使用很好。
kubemrr
Kubernetes Mirror; bash/zsh 中的 kubectl 自动不全工具(比如参数名称)
sql
mysql pipe 可以向一个、多个或所有 MySQ L实例发送查询请求,支持本地和远程查询或通过 SSH 查询。输出结果也很友好。可以和 chart 结合使用,这是另一个快速 ad-hoc 作图工具。
flowbro
一个实时和事后规划的 kafka 分布式系统虚拟化工具。
那么,Go 是否无所不能?
目前还达不到。Movio 的用例只是又长又复杂的需求的一小部分。
● 结合你自己的用例做选择。例如,如果你的工作主要围绕着数据科学,你最好用 Python 栈。
● 根据你的开发项目而定。你要使用的库可能 Go 没有或者有但不 Java 库那么完善。例如,Kafka 的开发者提供了 Java 的客户端库,那么开发 Go 版本自然比 JVM 版本滞后一些。
● 根据微服务的情况而定;高于一定的复杂度,我们将用更多的微服务来完成。而复杂逻辑也许难以用 Go 提供的简单工具来实现。(目前还未遇到此类问题)
可以肯定的是,Golang 非常适合我们!它会如何为你所用呢?:P

以上是关于从 Scala 迁移到 Go,永不回头的主要内容,如果未能解决你的问题,请参考以下文章