Spark常用的算子以及Scala函数总结
Posted 人工智能LeadAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark常用的算子以及Scala函数总结相关的知识,希望对你有一定的参考价值。
上海站 | 高性能计算之GPU CUDA培训
正文共11264个字,7张图,预计阅读时间28分钟。

Spark与Scala
首先,介绍一下scala语言:
Scala 是一种把面向对象和函数式编程理念加入到静态类型语言中的混血儿。
为什么学scala?
spark提供了R、Python等语言的接口,为什么还要重新学一门新的语言呢?
1、spark本身就是用scala写的,采用与底层框架相同的语言有很多好处,例如以后你要看源码......
2、性能开销小,scala可以直接编译运行在java的JVM上
3、能用上最新的版本。一般新版本都是最先支持scala,虽然现在python的接口也在不断的丰富
4、到了工作岗位,你的师父(都是有几年相关经验的),前期由于python的支持还没有像scala那样完善,因此会从scala开始使用spark的,你不学scala还让你师父转python啊!
新手学习Spark编程,在熟悉了Scala语言的基础上,首先需要对以下常用的Spark算子或者Scala函数比较熟悉,才能开始动手写能解决实际业务的代码。
简单来说,Spark 算子大致可以分为以下两类:
1、Transformation 变换/转换算子:这种变换并不触发提交作业,完成作业中间过程处理。
Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
2、Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。
Action 算子会触发 Spark 提交作业(Job),并将数据输出 Spark系统。
从小方向来说,Spark 算子大致可以分为以下三类:
1、Value数据类型的Transformation算子,这种变换并不触发提交作业,针对处理的数据项是Value型的数据。
2、Key-Value数据类型的Transfromation算子,这种变换并不触发提交 作业,针对处理的数据项是Key-Value型的数据对。
3、Action算子,这类算子会触发SparkContext提交Job作业
下面是我以前总结的一些常用的Spark算子以及Scala函数:
map():将原来 RDD 的每个数据项通过 map 中的用户自定义函数 f 映射转变为一个新的元素。
mapPartitions(function) :map()的输入函数是应用于RDD中每个元素,而mapPartitions()的输入函数是应用于每个分区。
mapValues(function) :�该操作只会��改动value
flatMap(function) :并将生成的 RDD 的每个集合中的元素合并为一个集合
flatMapValues(function):通过上面的例子可知,该操作也是只操作value,不改变key。
reduceByKey(func,numPartitions:用于对每个key对应的多个value进行merge操作
groupByKey(numPartitions):将元素通过函数生成相应的 Key,数据就转化为 Key-Value 格式,之后将 Key 相同的元素分为一组。
sortByKey(accending,numPartitions)
cogroup(otherDataSet,numPartitions)
join(otherDataSet,numPartitions):找出左右相同同的记录
LeftOutJoin(otherDataSet,numPartitions):以左边表为准,逐条去右边表找相同字段,如果有多条会依次列出
RightOutJoin(otherDataSet, numPartitions)
lookup():查询指定的key,u返回其对应的value。
filter(): filter 函数功能是对元素进行过滤,对每个 元 素 应 用 f 函 数, 返 回 值 为 true 的 元 素 在RDD 中保留,返回值为 false 的元素将被过滤掉。
full outer join()包括两个表的join结果,左边在右边中没找到的结果(NULL),右边在左边没找到的结果,FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
collect():函数可以提取出所有rdd里的数据项:RDD——>数组(collect用于将一个RDD转换成数组。)
reduce():根据映射函数f,对RDD中的元素进行二元计算,返回计算结果。
count():返回RDD内元素的个数
first():返回RDD内的第一个元素,first相当于top(1)
top:top可返回最大的k个元素。
case:匹配,更多用于 PartialFunction(偏函数)中 {case …}
saveAsTextFile:函数将数据输出,存储到 HDFS 的指定目录
cache : cache 将 RDD 元素从磁盘缓存到内存,内部默认会调用persist(StorageLevel.MEMORY_ONLY),也就是说它无法自定义缓存级别的。
persist():与cache一样都是将一个RDD进行缓存,在之后的使用过程汇总不需要重新的计算了。它比cache灵活,可以通过自定义
StorageLevel类型参数,来定义缓存的级别。coalesce():对RDD的分区进行�在分区,(用于分区数据分布不均匀的情况,利用HashPartitioner函数将数据重新分区)
reparation:与coalesce功能一样,它只是coalesce中shuffle设置为true的简易实现。(数据不经过shuffle是无法将RDD的分区变多的)
distinct(): distinct将RDD中的元素进行去重操作
subtract(): subtract相当于进行集合的差操作,RDD 1去除RDD 1和RDD 2交集中的所有元素。
基于SparkShell的交互式编程
1、map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。
val a = sc.parallelize(1 to 9, 3)
# x =>*2是一个函数,x是传入参数即RDD的每个元素,x*2是返回值
val b = a.map(x => x*2)
a.collect
# 结果Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
b.collect
# 结果Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18)
list/key--->key-value
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", " eagle"), 2)
val b = a.map(x => (x, 1))
b.collect.foreach(println(_))
# /*
# (dog,1)
# (tiger,1)
# (lion,1)
# (cat,1)
# (panther,1)
# ( eagle,1)
# */
val l=sc.parallelize(List((1,'a'),(2,'b')))
var ll=l.map(x=>(x._1,"PV:"+x._2)).collect()
ll.foreach(println)
# (1,PVa)
#(2,PVb)
=================================================================
2、mapPartitions(function)
map()的输入函数是应用于RDD中每个元素,而mapPartitions()的输入函数是应用于每个分区 package test
import scala.Iterator
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TestRdd {
def sumOfEveryPartition(input: Iterator[Int]): Int = {
var total = 0
input.foreach { elem =>
total += elem
}
total
}
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Rdd Test")
val spark = new SparkContext(conf)
val input = spark.parallelize(List(1, 2, 3, 4, 5, 6), 2)//RDD有6个元素,分成2个partition
val result = input.mapPartitions(
partition => Iterator(sumOfEveryPartition(partition)))//partition是传入的参数,是个list,要求返回也是list,即Iterator(sumOfEveryPartition(partition))
result.collect().foreach {
println(_)
# 6 15,分区计算和
}
spark.stop()
}
}
=================================================================
3、mapValues(function)
原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素。因此,该函数只适用于元素为KV对的RDD
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", " eagle"), 2)
val b = a.map(x => (x.length, x))
b.mapValues("x" + _ + "x").collect
# //结果
# Array(
# (3,xdogx),
# (5,xtigerx),
# (4,xlionx),
# (3,xcatx),
# (7,xpantherx),
# (5,xeaglex) # )
# val grouped = mds.groupBy(md => md.matched)
# grouped.mapValues(x => x.size).foreach(println)
=================================================================
4、flatMap(function)
与map类似,区别是原RDD中的元素经map处理后只能生成一个元素,而原RDD中的元素经flatmap处理后可生成多个元素
val a = sc.parallelize(1 to 4, 2)
val b = a.flatMap(x => 1 to x)//每个元素扩展
b.collect
/*
结果 Array[Int] = Array( 1,
1, 2,
1, 2, 3,
1, 2, 3, 4)
*/
===============================================
5、flatMapValues(function)
val a = sc.parallelize(List((1,2),(3,4),(5,6)))
val b = a.flatMapValues(x=>1 to x)
b.collect.foreach(println(_))
/*结果
(1,1)
(1,2)
(3,1)
(3,2)
(3,3)
(3,4)
(5,1)
(5,2)
(5,3)
(5,4)
(5,5)
(5,6)
*/
val list = List(("mobin",22),("kpop",20),("lufei",23))
val rdd = sc.parallelize(list)
val mapValuesRDD = rdd.flatMapValues(x => Seq(x,"male"))
mapValuesRDD.foreach(println)
输出:
(mobin,22)
(mobin,male)
(kpop,20)
(kpop,male)
(lufei,23)
(lufei,male)
如果是mapValues会输出:对比区别】
(mobin,List(22, male))
(kpop,List(20, male))
(lufei,List(23, male)) =================================================================
6、reduceByKey(func,numPartitions):
按Key进行分组,使用给定的func函数聚合value值, numPartitions设置分区数,提高作业并行度
val arr = List(("A",3),("A",2),("B",1),("B",3))
val rdd = sc.parallelize(arr)
val reduceByKeyRDD = rdd.reduceByKey(_ +_) r
educeByKeyRDD.foreach(println)
sc.stop
# (A,5)
# (A,4)
=================================================================
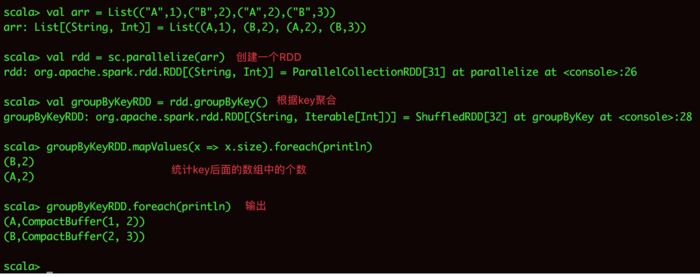
7、groupByKey(numPartitions):
按Key进行分组,返回[K,Iterable[V]],numPartitions设置分区数,提高作业并行度【value并不是累加,而是变成一个数组】
//省略
val arr = List(("A",1),("B",2),("A",2),("B",3))
val rdd = sc.parallelize(arr)
val groupByKeyRDD = rdd.groupByKey()
groupByKeyRDD.foreach(println)
sc.stop
# (B,CompactBuffer(2, 3))
# (A,CompactBuffer(1, 2))
# 统计key后面的数组汇总元素的个数
scala> groupByKeyRDD.mapValues(x => x.size).foreach(println)
# (A,2)
# (B,2)
=================================================================
8、sortByKey(accending,numPartitions):
返回以Key排序的(K,V)键值对组成的RDD,accending为true时表示升序,为false时表示降序,numPartitions设置分区数,提高作业并行度。
//省略
scval arr = List(("A",1),("B",2),("A",2),("B",3))
val rdd = sc.parallelize(arr)
val sortByKeyRDD = rdd.sortByKey() sortByKeyRDD.foreach(println)
sc.stop
# (A,1)
# (A,2)
# (B,2)
# (B,3)
# 统计单词的词频
val rdd = sc.textFile("/home/scipio/README.md")
val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_)
val wcsort = wordcount.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)) wcsort.saveAsTextFile("/home/scipio/sort.txt")
# 升序的话,sortByKey(true)
=================================================================
9、cogroup(otherDataSet,numPartitions):
对两个RDD(如:(K,V)和(K,W))相同Key的元素先分别做聚合,最后返回(K,Iterator<V>,Iterator<W>)形式的RDD,numPartitions设置分区数,提高作业并行度
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd1 = sc.parallelize(arr, 3)
val rdd2 = sc.parallelize(arr1, 3)
val groupByKeyRDD = rdd1.cogroup(rdd2)
groupByKeyRDD.foreach(println)
sc.stop
# (B,(CompactBuffer(2, 3),CompactBuffer(B1, B2)))# (A,(CompactBuffer(1, 2),CompactBuffer(A1, A2)))
=================================================================
10、join(otherDataSet,numPartitions):
对两个RDD先进行cogroup操作形成新的RDD,再对每个Key下的元素进行笛卡尔积,numPartitions设置分区数,提高作业并行度
//省略
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val groupByKeyRDD = rdd.join(rdd1)
groupByKeyRDD.foreach(println)
# (B,(2,B1))
# (B,(2,B2))
# (B,(3,B1))
# (B,(3,B2))
# (A,(1,A1))
# (A,(1,A2))
# (A,(2,A1))
# (A,(2,A2
=================================================================
11、LeftOutJoin(otherDataSet,numPartitions):
左外连接,包含左RDD的所有数据,如果右边没有与之匹配的用None表示,numPartitions设置分区数,提高作业并行度/
/省略
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3),("C",1))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val leftOutJoinRDD = rdd.leftOuterJoin(rdd1) leftOutJoinRDD .foreach(println)
sc.stop
# (B,(2,Some(B1)))
# (B,(2,Some(B2)))
# (B,(3,Some(B1)))
# (B,(3,Some(B2)))
# (C,(1,None))
# (A,(1,Some(A1)))
# (A,(1,Some(A2)))
# (A,(2,Some(A1)))
# (A,(2,Some(A2)))
=================================================================
12、RightOutJoin(otherDataSet, numPartitions):
右外连接,包含右RDD的所有数据,如果左边没有与之匹配的用None表示,numPartitions设置分区数,提高作业并行度
//省略
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"),("C","C1"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val rightOutJoinRDD = rdd.rightOuterJoin(rdd1) rightOutJoinRDD.foreach(println)
sc.stop
# (B,(Some(2),B1))
# (B,(Some(2),B2))
# (B,(Some(3),B1))
# (B,(Some(3),B2))
# (C,(None,C1))
# (A,(Some(1),A1))
# (A,(Some(1),A2))
# (A,(Some(2),A1))
# (A,(Some(2),A2))
=================================================================
13、lookup()
var rdd1=sc.parallelize(List((1,"a"),(2,"b"),(3,"c")))
# rdd1: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[81] at parallelize at rdd1.lookup(1)
# res34: Seq[String] = WrappedArray(a)
=================================================================
14、filter()
val filterRdd = sc.parallelize(List(1,2,3,4,5)).map(_*2).filter(_>5) filterRdd.collect
# res5: Array[Int] = Array(6, 8, 10)
=================================================================
16、collect()
scala> var rdd1 = sc.makeRDD(1 to 10,2)
# rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[36] at makeRDD at :21
scala> rdd1.collect
# res23: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
=================================================================
17、reduce() scala>
var rdd1 = sc.makeRDD(1 to 10,2)
# rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[36] at makeRDD at :21
# 求和scala> rdd1.reduce(_ + _)
# res18: Int = 55 scala> var rdd2 = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2),("C",1)))
# rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[38] at makeRDD at :21
# 分项求和
scala> rdd2.reduce((x,y) => {
| (x._1 + y._1,x._2 + y._2)
| })
res21: (String, Int) = (CBBAA,6) =================================================================
18、count() scala>
var rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")),2)
# rdd1: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[34] at makeRDD at :21
scala> rdd1.count# res15: Long = 3
=================================================================
19、first() scala>
var rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")),2)
# rdd1: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[33] at makeRDD at :21
scala> rdd1.first# res14: (String, String) = (A,1)
=================================================================
21、casescala>
val aa=List(1,2,3,"asa")# aa: List[Any] = List(1, 2, 3, asa)scala> aa. map {
| case i: Int => i + 1
| case s: String => s.length
| }
# res16: List[Int] = List(2, 3, 4, 3)
补充:reduceByKeyt与groupByKey的区别?
[优化代码的最基本思路]
(1)当采用reduceByKeyt时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。借助下图可以理解在reduceByKey里究竟发生了什么。 注意在数据对被搬移前同一机器上同样的key是怎样被组合的(reduceByKey中的lamdba函数)。然后lamdba函数在每个区上被再次调用来将所有值reduce成一个最终结果。整个过程如下:
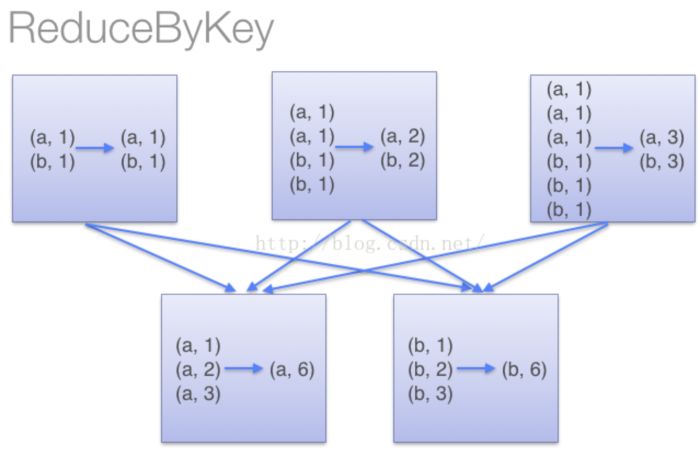
ReduceByKey
(2)当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时。整个过程如下:
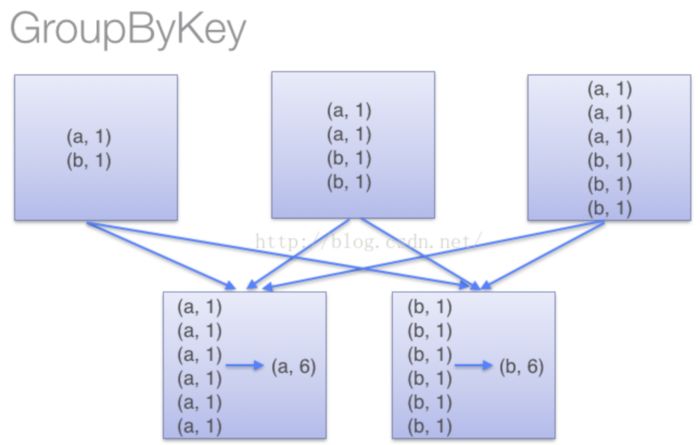
groupByKey
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
原文链接:https://www.jianshu.com/p/addc95d9ebb9
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
大家都在看
以上是关于Spark常用的算子以及Scala函数总结的主要内容,如果未能解决你的问题,请参考以下文章