Scala实现爬取某网站数据
Posted Nathon的学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scala实现爬取某网站数据相关的知识,希望对你有一定的参考价值。
之前通过scala简单的爬取了网页,接下来尝试着爬取大型网站的数据。DT时代,数据即为资产,现如今很多企业一方面会保护自己的数据,另一方面也会获取别人的数据来提取价值,想办法造"血"来获取自己想要的信息。
比如,我对歌曲很感兴趣,在我不知道歌曲的分类的时候,想看看有哪些歌是深受大众喜爱的,流传度最广的。这里通过scala爬取豆瓣网的音乐模块(如下图,包含了音乐信息,评分等),然后将需要的数据保存下来。
由于音乐的标签种类很多,诸如:流行,古典,摇滚等,每一个种类也有上百页。如果一页页去爬取,显然速度慢了。于是,采用scala的多线程进行爬取,提高性能,为了保证在多线程下的并发安全性,采用了ConcurrentHashmap的数据结构。部分核心代码如下:
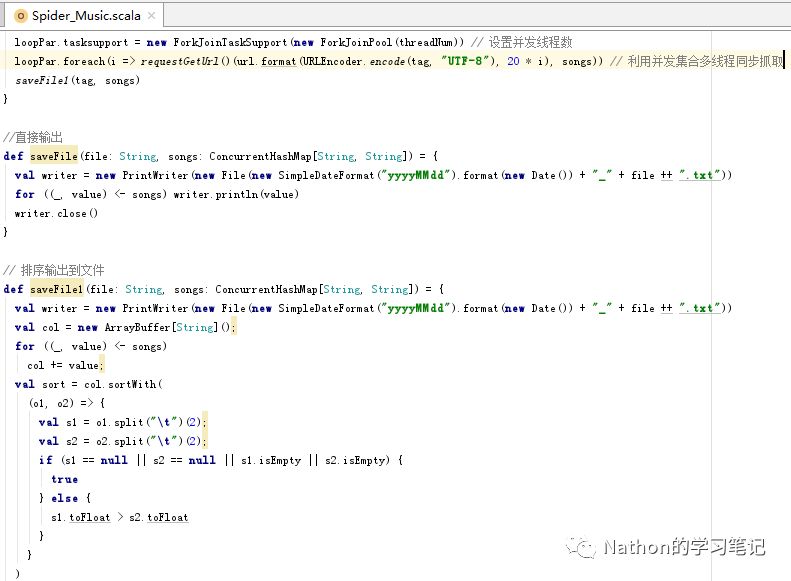
最后,我将抓取的数据信息保存在本地文件中,当然也可以持久化到DB里面(Redis),方便读取。
在抓取的流行范畴音乐类里面,我爬取了10页的内容,并将数据的评分进行排序,可以看到大家对歌曲的评分。
以上是关于Scala实现爬取某网站数据的主要内容,如果未能解决你的问题,请参考以下文章