分别用SQL和Spark(Scala)解决50道SQL题
Posted 天下皆通途
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分别用SQL和Spark(Scala)解决50道SQL题相关的知识,希望对你有一定的参考价值。
众生皆苦,唯人自渡。
最近学习了Hive以及练习了一下SQL,网上有流传比较多的50道SQL题,用SQL的形式以及Spark(Scala)的形式写了写,熟悉一下基本的操作。
用SQL的形式以及Spark(Scala)的形式写完这些题后,感受就是SQL写起来是真的丑,而用Spark(Scala)却真正能体会到所谓的函数式编程的优雅和流畅。
完整的代码在:
https://github.com/ybm1/spark_learning/tree/master/src/scala/bigdata/spark_sql_exercies
在说这些题之前,首先简明扼要的概括一下比较重要的知识点。
Hive一些重要概念
首先要知道Hive是一个大数据的处理工具,并且提供了一套类SQL的语言给用户,使得用户可以以较低地学习成本来对大数据进行分析和处理。
其次要知道Hive的架构,其数据存储用的是Hadoop的HDFS,其计算引擎是用的Hadoop的Mapreduce,而它最大的贡献可以说就是提供了一个HQL的外层给用户使用,而Hive的本质是把其提供的类SQL的表层语言HQL翻译为Mapreduce进行执行。
另外一个非常重要的组件是所谓的元数据,元数据保存了Hive中各个表的信息,一个表中的数据真正储存在HDFS上,而我们能够通过HQL语言对其进行访问的必要条件是元数据中必须有该表的信息,否则即使HDFS上有数据也无法通过HQL进行访问(此时往往需要对表进行MSCK REPAIR TABLE table_name来修复元数据信息。),所以想要查数据,首先HDFS上要有数据,另外元数据不缺少,两个缺一不可。
在知道了元数据的概念后,就可以区分一个常见的问题:内部表和外部表的区别。一句话回答这个问题:删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
由于Mapreduce的速度较慢,所以现在也有把计算引擎换成spark,flink等引擎的,为了加速。而提供给用户的还是SQL,另外也有UDF的使用,两者结合可以解决很多问题了。
Hive还有一个常用的分区概念,分区是为了更好的进行数据管理,一般的分区就是根据时间分区,尤其是每天要例行跑任务的时候。
这部分的参考资料:
https://www.bilibili.com/video/BV1W4411B7cN?p=1
https://www.jianshu.com/p/420ddb3bde7f
https://blog.csdn.net/qq_36743482/article/details/78418343
https://blog.csdn.net/qq_36743482/article/details/78393678
https://www.cnblogs.com/airnew/p/9776023.html
SQL方面重要的知识点
基本的查询没有太大的难度,除此之外,有几个比较难的部分:
子查询(嵌套查询)
各种join的使用
窗口函数的使用UDF的使用SQL语句的调优
如果能把这几块再搞清楚,就差不多了。网上有一些练习题,以这些练习题为例来对上面的问题进行举例吧。题目连接:https://www.jianshu.com/p/476b52ee4f1b。
首先说一下题目的基本情况,一共有4个表,分别是学生信息表,课程信息表,教师信息表,和学生成绩表,题目就是围绕这4个表展开进行各种捣鼓。我这里就在本地用Spark进行题目的解答,分别使用Spark本身的dataframe的算子操作和Spark.sql进行操作,Spark.sql中支持的方法和HQL差不多。
首先把数据模拟出来:
// 分别创建 学生表Student;科目表Course;教师表Teachers;成绩表Score;
def get_Student_table(spark: SparkSession): DataFrame = {
val Student_arr: Array[(String, String, String, String)] =
Array(("01", "赵雷", "1990-05-01", "男"),
("02", "赵雷", "1990-08-21", "男"),
("03", "孙小风", "1990-06-20", "男"),
("04", "李云", "1990-12-06", "女"),
("05", "周大风", "1991-12-01", "女"),
("06", "吴兰", "1992-01-01", "女"),
("07", "吴兰", "1992-01-01", "女"))
val Student = spark.createDataFrame(Student_arr).
toDF("SID", "Sname", "Sage", "Ssex")
Student
}
def get_Course_table(spark: SparkSession): DataFrame = {
val Course_arr: Array[(String, String, String)] =
Array(("01", "语文", "01"),
("02", "数学", "02"),
("03", "化学", "03"),
("04", "英语", "04"),
("05", "地理", "05"),
("06", "体育", "06"),
("07", "历史", "07"))
val Course = spark.createDataFrame(Course_arr).
toDF("CID", "Cname", "TID")
Course
}
def get_Teacher_table(spark: SparkSession): DataFrame = {
val Teacher_arr: Array[(String, String)] =
Array(("01", "张三"),
("02", "李逵"),
("03", "李白"),
("04", "李商隐"),
("05", "司马懿"),
("06", "诸葛村夫"),
("07", "王朗"))
val Teacher = spark.createDataFrame(Teacher_arr).
toDF("TID", "Tname")
Teacher
}
def get_Score_table(spark: SparkSession): DataFrame = {
val Score_arr: Array[(String, String, Double)] =
Array(
("01", "01", 30),
("01", "02", 30),
("01", "03", 30),
("01", "04", 28),
("01", "07", 28),
("02", "01", 38),
("02", "03", 45),
("02", "02", 93),
("02", "04", 82),
("02", "06", 69),
("03", "01", 28),
("03", "03", 40),
("03", "05", 70),
("03", "02", 28),
("03", "04", 40),
("04", "07", 30),
("05", "01", 10),
("05", "02", 38),
("05", "03", 89),
("05", "04", 42),
("05", "05", 10),
("05", "06", 38),
("05", "07", 29),
("06", "01", 65),
("06", "02", 69),
("06", "03", 70),
("06", "04", 55),
("06", "06", 69),
("06", "07", 70),
("07", "01", 70),
("07", "02", 69),
("07", "03", 70),
("07", "04", 55),
("07", "05", 70),
("07", "06", 69),
("07", "07", 70))
val Score = spark.createDataFrame(Score_arr).
toDF("SID", "CID", "score")
Score
}
然后分别建立需要的表和dataframe(这里只展示关键代码,全部代码会在后面附上):
val conf = new SparkConf().setAppName("Demo").
set("spark.default.parallelism", "3600").
set("spark.sql.shuffle.partitions", "3600").
set("spark.memory.fraction", "0.8").
setMaster("local[*]")
val spark = SparkSession.builder.config(conf).enableHiveSupport.getOrCreate
val sc = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
val Student = get_Student_table(spark).createOrReplaceTempView("Student")
val Course = get_Course_table(spark).createOrReplaceTempView("Course")
val Teacher = get_Teacher_table(spark).createOrReplaceTempView("Teacher")
val Score = get_Score_table(spark).createOrReplaceTempView("Score")
val Student_df = get_Student_table(spark)
val Course_df = get_Course_table(spark)
val Teacher_df = get_Teacher_table(spark)
val Score_df = get_Score_table(spark)
下面就可以愉快的做题了。总的来说这50道题,大部分题还是中等以及以下难度,有个别题比较难(尤其是第8题和第9题),我从其中摘出一些比较有代表性的题,剩下的题毕竟基础,应该问题不大。
精选题解
1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
关键点:自连接
自连接即一个表自己和自己做join,在一些题目中很有效,尤其涉及到自身表的一些查询时
下面是解答,由于join也可以用where来代替,所以有两种SQL写法,下面同样提供了Spark解法。
println("第1题sql解法==============>")
val s1_sql = spark.
sql(
"""
|select st.Sname,s1.SID,s1.CID,s1.score,s2.CID as CID2,s2.score as score2
|from Score s1, Score s2,Student st
|where s1.SID=s2.SID and st.SID = s1.SID
|and s1.CID='01' and s2.CID='02'
|and s1.score>s2.score
|""".stripMargin)
val s1_sql_1 = spark.
sql(
"""
|select st.Sname,s1.SID,s1.CID,s1.score,s2.CID as CID2,s2.score as score2
|from Score s1 join Score s2 on s1.SID=s2.SID
|join Student st on st.SID=s2.SID
|where s1.CID='01' and s2.CID='02'
|and s1.score>s2.score
|""".stripMargin)
s1_sql.show()
s1_sql_1.show()
println("第1题spark解法==============>")
val Score2 = Score_df.
//注意这里的重命名列的方法
withColumnRenamed("CID", "CID2").
withColumnRenamed("score", "score2")
val s1_sp = Score_df.
join(Score2, Seq("SID"), joinType = "inner").
join(Student_df, Seq("SID"), joinType = "inner").
// 注意是三等号
filter($"CID" === "01" && $"CID2" === "02").
filter($"score" > $"score2").
select("Sname", "SID", "CID", "score", "CID2", "score2")
s1_sp.show()
7、查询没有学全所有课程的同学的信息
关键点:子查询(嵌套查询) (让一个SQL变得很长而且很丑的罪魁祸首)
子查询的意思就是,把一个中间结果作为一个新表继续使用
根据子查询的返回值有3种情况:
返回一张数据表(Table):可以用在from后面以及join中
返回一列值(Column):一般在where中与in搭配(in 可以用join来代替以进行优化),也可以和group by和having使用,主要用来过滤
返回单个值(Scalar) :在where中使用,比较简单
其中还涉及到了相关子查询和无关子查询,可以去看参考资料
参考:
https://www.cnblogs.com/CareySon/archive/2011/07/18/2109406.html
https://www.cnblogs.com/glassysky/p/11559082.html
https://blog.csdn.net/zark721/article/details/63680532
下面给出解答:
println("第7题sql解法==============>")
val s7_sql = spark.sql(
"""
select st.Sname,st.SID,count(distinct sc.CID) as nums
from Student st
join Score sc on st.SID = sc.SID
group by st.Sname,st.SID
having nums <
(select count(distinct sc.CID) from
Score sc)
""".stripMargin)
s7_sql.show()
println("第7题spark解法==============>")
val all_cids = Score_df.
agg(countDistinct($"CID").as("al")).
collectAsList().get(0)(0)
// 最后是通过array方法把值取出来,
// 注意collect()方法返回的是scala的数组array,
// 而collectAsList是Java的API(不过好像也能用,只是此时需要用get方法来获得值)
val s7_sp = Student_df.
join(Score_df, Seq("SID")).
groupBy($"Sname", $"SID").
agg(countDistinct($"CID").as("nums")).
filter($"nums" < all_cids)
s7_sp.show()
这里在having中使用了子查询,用子查询先把全部课程的量统计出来,然后查询出聚合后课程量少于这个量的那些人就可以了。
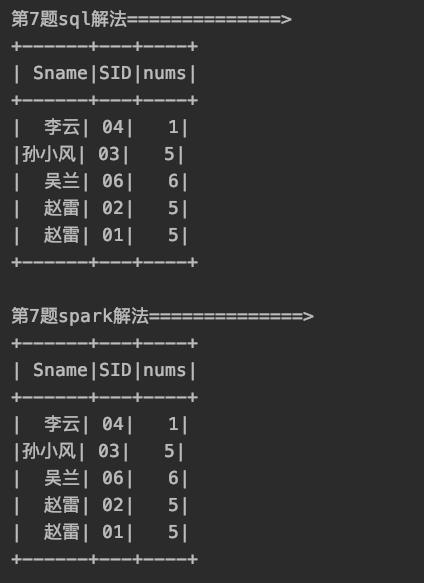
8、查询至少有一门课与学号为" 01 "的同学所学相同的同学的信息(这题很难)
关键点:这题难在思路,以及一些
UDF和函数的使用上
我的思路是:把"01"同学所学的课找出来做成一个array,然后再把其他同学所学的课找出来做成一个array,然后分别和"01"同学的做交集,根据交集的长度来进行查询
所用到的关键函数:collect_set(col),自带函数,与group by搭配,可以把分组后的某列做成一个array并且去重array_intersect(col_1,col_2),自带函数,返回两个列的交集,这两个列的类型必须都是array型的,这个函数是自带的,当然也可以通过注册UDF的形式实现arr_len这个函数是自己定义的,用来求array的长度with table as (select ...),自带函数,由于逻辑较复杂,用该语句来生成临时表,便于简化SQL
下面给出解答:
// 注册一个求两个数组交集的udf,spark sql中有自带的array_intersect也可以使用
spark.udf.register("two_cols_intersect", (a: Seq[String], b: Seq[String]) => a.intersect(b))
// 注册一个求array长度的UDF
spark.udf.register("arr_len", (a: Seq[String]) => a.toArray.length)
println("第8题sql解法==============>")
val s8_sql = spark.sql(
"""
|with t1 as (
|select collect_set(S1.CID) as c_1
| from Score S1
| where S1.SID = "01"
| group by
| S1.SID),
|t2 as (
|select S.SID,collect_set(S.CID) as c_all
|from Score as S
|group by
|S.SID
|)
|select t3.SID as SID,t3.nums as nums
|from
|(select t2.SID as SID,
|arr_len(array_intersect(t2.c_all,(select t1.c_1 from t1))) as nums
|from t2) as t3
|where nums >=1 and SID != "01"
|order by SID
|""".stripMargin)
s8_sql.show()
println("第8题spark解法==============>")
val t1_c1 = Score_df.
filter($"SID" === "01").
groupBy($"SID").
agg(collect_set($"CID").as("c1")).
map(a => a.getAs[Seq[String]]("c1").toArray).
collectAsList(). // 这个以及下面的get方法非常重要,可以获得一个具体的东西
get(0)
// println(t1_c1.mkString(","))
val s8_sp = Score_df.
groupBy($"SID").
agg(collect_set($"CID").as("c_all")).
map(a => {
val sid = a.getAs[String]("SID")
val c_all = a.getAs[Seq[String]]("c_all").
toArray.intersect(t1_c1).length
(sid, c_all)
}).
toDF("SID", "nums").
// 注意 === 和=!=是Column类中定义的新函数
filter($"SID" =!= "01" && $"nums" >= 1).
sort($"SID")
s8_sp.show()
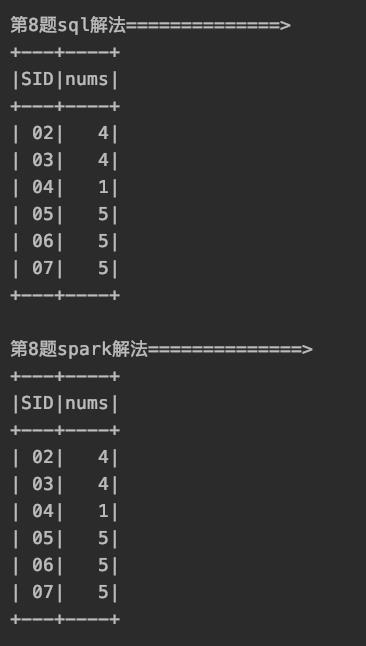
9、查询和" 01 "号的同学学习的课程 完全相同的其他同学的信息
有了第八题的思路,第九题可以类似去做
先把"01"学生的全部课程拿出来,然后做完交集后,根据交集长度进行查询即可
println("第9题sql解法==============>")
val s9_sql = spark.sql(
"""
|with t1 as (
|select collect_set(S1.CID) as c_1
| from Score S1
| where S1.SID = "01"
| group by
| S1.SID),
|t2 as (
|select S.SID,collect_set(S.CID) as c_all
|from Score as S
|group by
|S.SID
|)
|select t3.SID as SID,t3.nums as nums
|from
|(select t2.SID as SID,
|arr_len(two_cols_intersect(t2.c_all,(select t1.c_1 from t1))) as nums
|from t2) as t3
|where nums = (select arr_len(c_1) from t1)
| and SID != "01"
|order by SID
|""".stripMargin)
s9_sql.show()
println("第9题spark解法==============>")
val t1_c1_s = Score_df.
filter($"SID" === "01").
groupBy($"SID").
agg(collect_set($"CID").as("c1")).
map(a => a.getAs[Seq[String]]("c1").toArray).
collectAsList().
get(0)
val c1_l = t1_c1_s.length
val s9_sp = Score_df.
groupBy($"SID").
agg(collect_set($"CID").as("c_all")).
map(a => {
val sid = a.getAs[String]("SID")
val c_all = a.getAs[Seq[String]]("c_all").
toArray.intersect(t1_c1_s).length
(sid, c_all)
}).
toDF("SID", "nums").
// 注意 === 和=!=是Column类中定义的新函数
filter($"SID" =!= "01" && $"nums" === c1_l).
sort($"SID")
s9_sp.show()
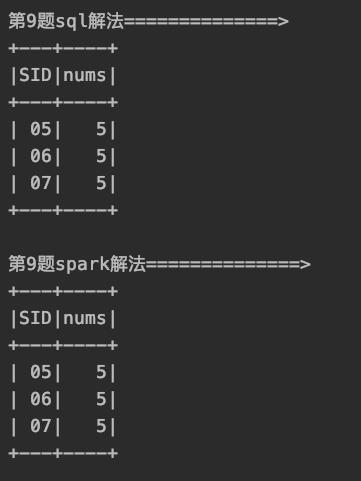
12、检索" 01 "课程分数小于 60,按分数降序排列的学生信息
关键点:用到了子查询和
in以及用join来代替in
把临时表作为右连接的右表(或者左连接的左表)即可
println("第12题sql解法==============>")
val s12_sql_1 = spark.sql(
"""
|select SID,CID,score
|from Score
|where
|SID in
|(select SID
|from Score
|where CID ="01" and score <=60)
|order by SID,score desc
|""".stripMargin)
s12_sql_1.show(5)
val s12_sql_2 = spark.sql(
"""
|select S.SID as SID,S.CID as CID,S.score as score
|from Score S
|right join
|(select SID
|from Score
|where CID ="01" and score <=60) as t1
|on S.SID = t1.SID
|order by SID,score desc
|""".stripMargin)
// 注意这里用join来代替了in,因为in往往会使执行速度变慢,
// 把临时表作为右连接的右表(或者左连接的左表)即可
s12_sql_2.show(5)
println("第12题spark解法==============>")
val s12_sp = Score_df.
filter($"CID"==="01" && $"score" <=60).
select($"SID").
join(Score_df,Seq("SID"),joinType = "left").
sort(asc("SID"),desc("score"))
s12_sp.show(5)
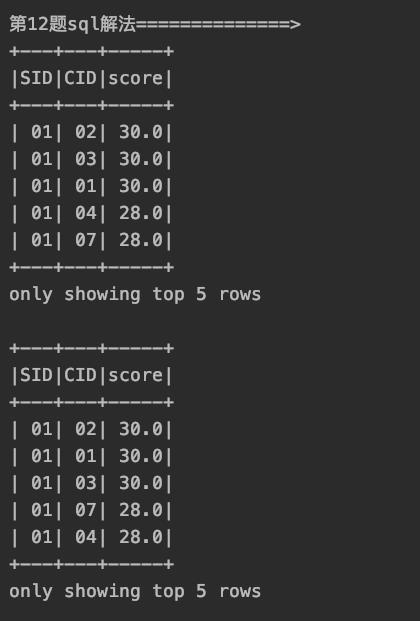
14、查询各科成绩最高分、最低分和平均分
以如下形式显示:课程 ID,课程 name,及格率,中等率,优良率,优秀率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列**
关键点:
case when then end的使用
println("第14题sql解法==============>")
val s14_sql = spark.sql(
"""
|select C.Cname,S.CID,
|count(case when S.score>=60 then 1 end)/count(S.CID) as jige_ratio,
|count(case when S.score>=70 and S.score <80 then 1 end)/count(S.CID) as zhongdeng_ratio,
|count(case when S.score>=80 and S.score <90 then 1 end)/count(S.CID) as youliang_ratio,
|count(case when S.score>=90 then 1 end)/count(S.CID) as youxiu_ratio,
|count(S.CID) as nums
|from Score S join
|Course C on S.CID=C.CID
|group by C.Cname,S.CID
|order by nums desc,CID
|""".stripMargin)
s14_sql.show()
println("第14题spark解法==============>")
val s14_sp = Score_df.
join(Course_df,Seq("CID")).
groupBy($"Cname",$"CID").
agg((count(when($"score">=60,1).otherwise(null))/count($"CID")).as("jige_ratio"),
(count(when($"score">=70 && $"score"<80 ,1).otherwise(null))/count($"CID")).as("zhongdeng_ratio"),
(count(when($"score">=80 && $"score"<90 ,1).otherwise(null))/count($"CID")).as("youliang_ratio"),
(count(when($"score">=90,1).otherwise(null))/count($"CID")).as("youxiu_ratio"),
count($"CID").as("nums")).
sort(desc("nums"),asc("CID"))
s14_sp.show()
15、按各科成绩进行排序,并显示排名, Score 重复时保留名次空缺
关键点:窗口函数(3个排名函数)的使用
窗口函数也是实际中大量使用的一个关键点。
其解决了什么问题呢?group by操作是多进一出操作,如果既想要看到分组后的结果,又想看原来未聚合的列之前的信息,就必须用窗口函数了。
窗口函数不改变一个表的大小,即:使用窗口函数之前表的大小和使用之后一样。表的大小指表的行数。
窗口函数的窗口的意义是over()前面的聚合函数的作用范围,窗口由partition by和order by这两个来决定,在指定好了窗口后,聚合函数会得到该得到的结果。
over()之前可以跟一般的聚合函数,如sum(),count()等,还可以跟特别的排名函数(rank(),dense_rank()和row_number()),函数不同功能不同。
partition by决定根据某个字段进行分区,即在分区内进行前面的聚合操作,它有改变聚合函数作用范围的作用,其作用范围从不加partition by的全表范围改为根据某个字段分组的范围。
order by也可以对聚合函数的作用范围进行修改,order by默认情况下聚合(如果有partition by 就还要在分区内)从起始行到当前行的数据,一般用于排名、TopK和累加计算等方面。
窗口函数参考资料:
https://blog.csdn.net/qq_26937525/article/details/54925827
https://blog.csdn.net/scgaliguodong123_/article/details/60135385
https://blog.csdn.net/fox64194167/article/details/80790754
对15题直接用排名函数就可以解决:
println("第15题sql解法==============>")
val s15_sql = spark.sql(
"""
|select SID,CID,score,
|rank() over(partition by CID order by score desc) as rank1,
|dense_rank() over(partition by CID order by score desc) as rank2,
|row_number() over(partition by CID order by score desc) as rank3
|from Score
|""".stripMargin)
s15_sql.show(5)
println("第15题spark解法==============>")
val rankSpec1 = Window.partitionBy("CID").orderBy(Score_df("score").desc)
val s15_sp = Score_df.
withColumn("rank1", rank.over(rankSpec1)).
withColumn("rank2", dense_rank.over(rankSpec1)).
withColumn("rank3", row_number.over(rankSpec1))
s15_sp.show(5)
18、查询各科成绩前三名的记录
关键点:窗口函数和
TopK问题
println("第18题sql解法==============>")
val s18_sql = spark.sql(
"""
|select t1.SID,t1.CID,t1.score,t1.rank1 from
|(select SID,CID,score,
|rank() over (partition by CID order by score desc) as rank1
|from Score) as t1
|where t1.rank1 <=3
|order by t1.CID
|""".stripMargin)
s18_sql.show()
println("第18题spark解法==============>")
val rankSpec3 = Window.partitionBy("CID").orderBy(Score_df("score").desc)
val s18_sp = Score_df.
withColumn("rank1", rank.over(rankSpec3)).
filter($"rank1"<=3).
sort("CID")
s18_sp.show()
33、成绩不重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
34 成绩有重复的情况下,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
上面两题统一解答。
关键点:子查询,临时表,窗口函数和多表
join
println("第33题sql解法==============>")
val s33_sql = spark.sql(
"""
|with t1 as (select CID from
|Course C
|where TID =
|(select TID from Teacher where Tname="张三")),
|t2 as (
|select S.CID,S.SID,S.score,
|rank() over(partition by S.CID order by S.Score desc) as rank1
|from Score S
|join t1
|on S.CID = t1.CID)
|select t2.CID,St.SID,St.Sname,t2.score,t2.rank1
|from
|t2 join Student St
|on St.SID = t2.SID
|where t2.rank1 =1
|""".stripMargin)
s33_sql.show(5)
println("第33题spark解法==============>")
val s33_sp_t1 = Teacher_df.
filter($"Tname"==="张三").
select($"TID").
join(Course_df,Seq("TID"),joinType = "inner").
select($"CID").
join(Score_df,Seq("CID"),joinType = "inner").
select($"CID",$"SID",$"score")
val rankSpec2 = Window.partitionBy("CID").orderBy(s33_sp_t1("score").desc)
val s33_sp = s33_sp_t1.
withColumn("rank1", rank.over(rankSpec2)).
filter($"rank1"===1).
join(Student_df,Seq("SID"),joinType = "inner").
select($"CID",$"SID",$"Sname",$"score",$"rank1")
s33_sp.show(5)
35、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
关键点:窗口函数中根据多个字段分区
这题似乎有点歧义,两种理解:
找出课程不同,但是成绩相同的不同学生
找出同一学生,课程不同但是分数相同的那些学生
我按照第一种理解做的(因为我感觉比较不同科目的分数好像没啥意义),从SQL上来说两种理解就是按照不同的分区进行计数的区别。
println("第35题sql解法==============>")
val s35_sql = spark.sql(
"""
|select * from
|(select SID,CID,score,
|count(SID) over(partition by CID,score) as nums
|from Score) as t1
|where t1.nums > 1
|order by t1.CID,t1.SID
|""".stripMargin)
s35_sql.show(5)
println("第35题spark解法==============>")
val rankSpec3 = Window.partitionBy("CID","score")
val s35_sp = Score_df.
withColumn("nums", count("SID").over(rankSpec3)).
filter($"nums" > 1).
sort($"CID",$"SID")
s35_sp.show(5)
其他的题目都比较基础了,用一些常用的手段就可以搞定,就不一一列举了。
总结
本文对Hive以及SQL和Spark的用法进行了一些总结,如果问题欢迎交流。
北交大统计学硕士
会点Python/R,cpp在路上
机器学习工程师/数据分析师修炼中
主攻广告和推荐方向
也爱看点文学、心理和宗教的东西
无可无不可,天下皆通途
长按扫码关注
以上是关于分别用SQL和Spark(Scala)解决50道SQL题的主要内容,如果未能解决你的问题,请参考以下文章
Spark SQL functions.scala 源码解析String functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析Aggregate functions(基于 Spark 3.3.0)