图解 Google 类通用搜索引擎背后的技术点
Posted 程序员的那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解 Google 类通用搜索引擎背后的技术点相关的知识,希望对你有一定的参考价值。
(给程序员的那些事加星标)
来源:后端技术指南针 (本文来自作者投稿)
写在前面
今天准备和盆友们一起学习下关于通用搜索引擎的一些技术点。
鉴于搜索引擎内容非常多,每一部分都够写好几篇文章的所以本文只是抛砖引玉,深入挖掘还得老铁们亲力亲为。
通过本文你将对通用搜索引擎的基本原理和组成有一个较为清晰的认识,用心读完,肯定有所收获!
废话不说,各位抓紧上车,冲鸭!
初识搜索引擎
2.1 搜索引擎分类
搜索引擎根据其使用场景和规模,可以简单分为两大类:
通用搜索引擎
通用搜索又称为大搜,诸如谷歌、百度、搜狗、神马等等都属于这一类。
垂直搜索引擎
垂直搜索又称为垂搜,是特定领域的搜索,比如用QQ音乐搜周杰伦的歌等。

两类搜索引擎虽然数据规模和数据特征不一样,但都是为了填平用户和海量信息之间的鸿沟。
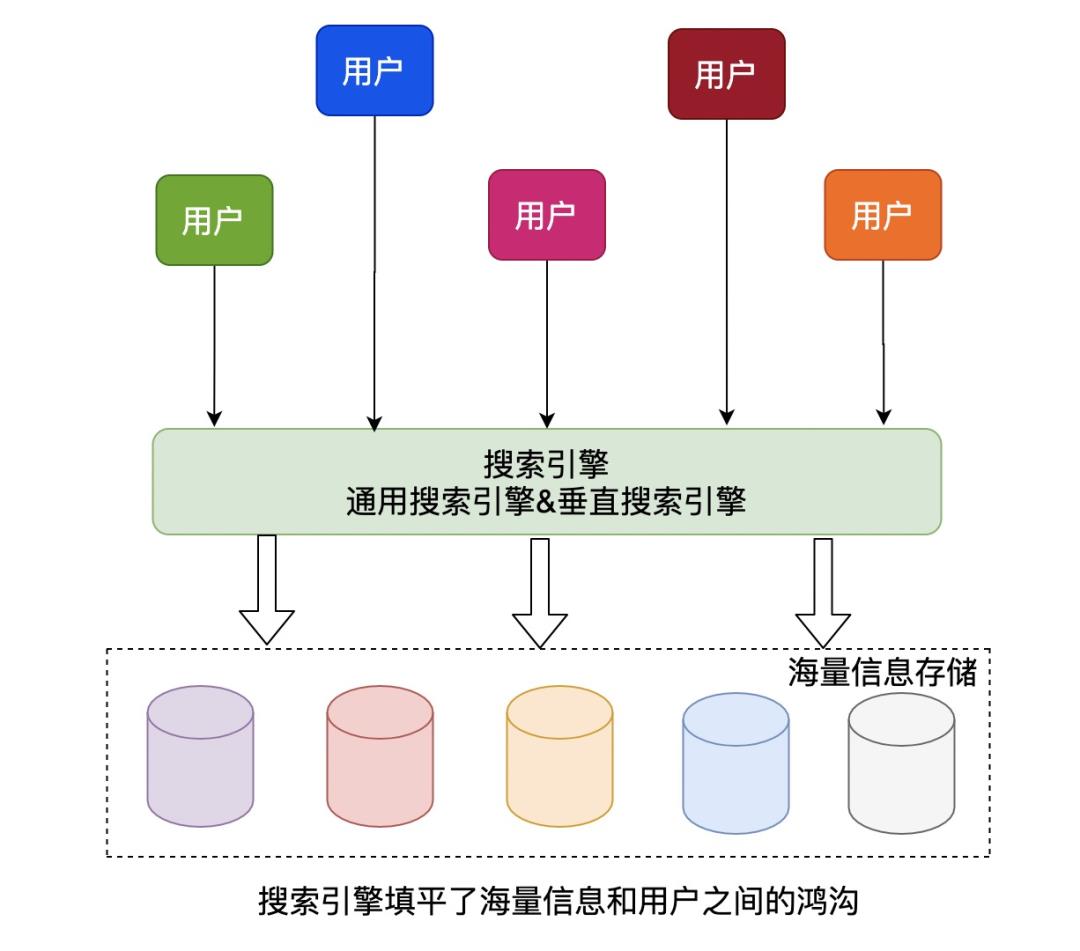
2.2 搜索和推荐
搜索和推荐经常被相提并论,但是二者存在一些区别和联系。
-
共同点
宏观上来说,搜索和推荐都是为了解决用户和信息之间的隔离问题,给用户有用的/需要的/喜欢的信息。 -
区别点
搜索一般是用户主动触发,按照自己的意图进行检索,推荐一般是系统主动推送,让用户看到可能感兴趣的信息。
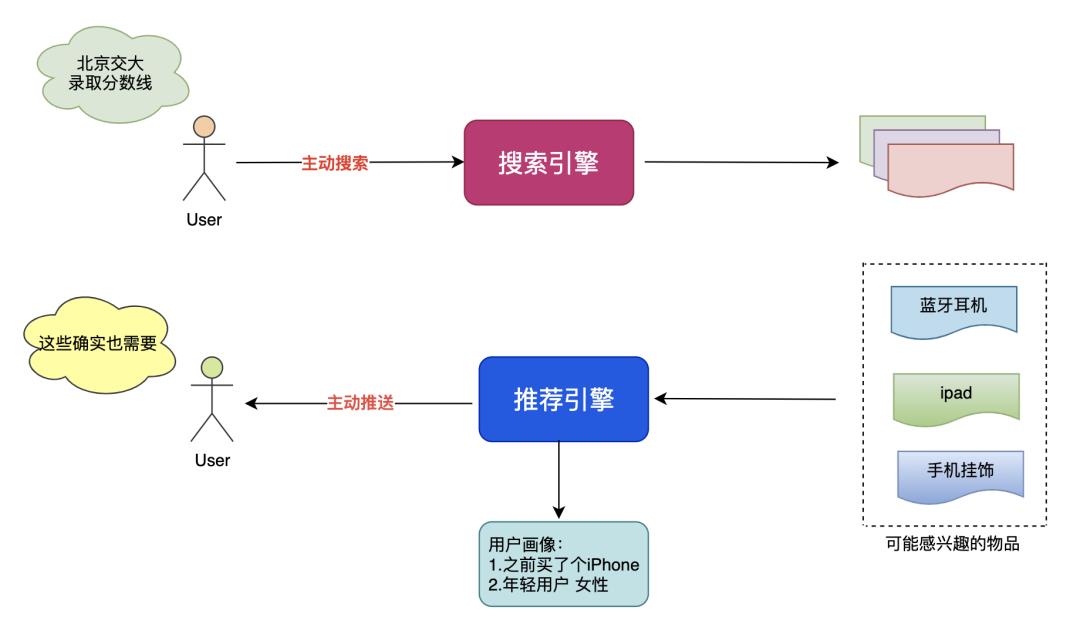
2.3 搜索引擎评价标准
通用搜索引擎的整体概览
3.1 搜索引擎的基本流程
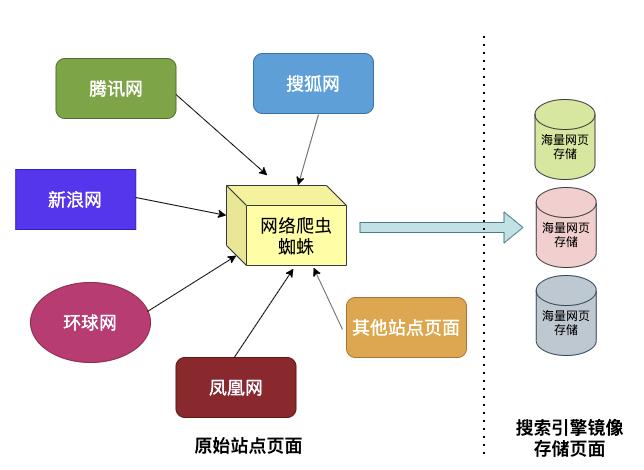
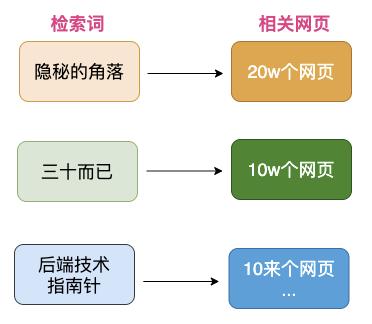
3.2 搜索引擎的基本组成
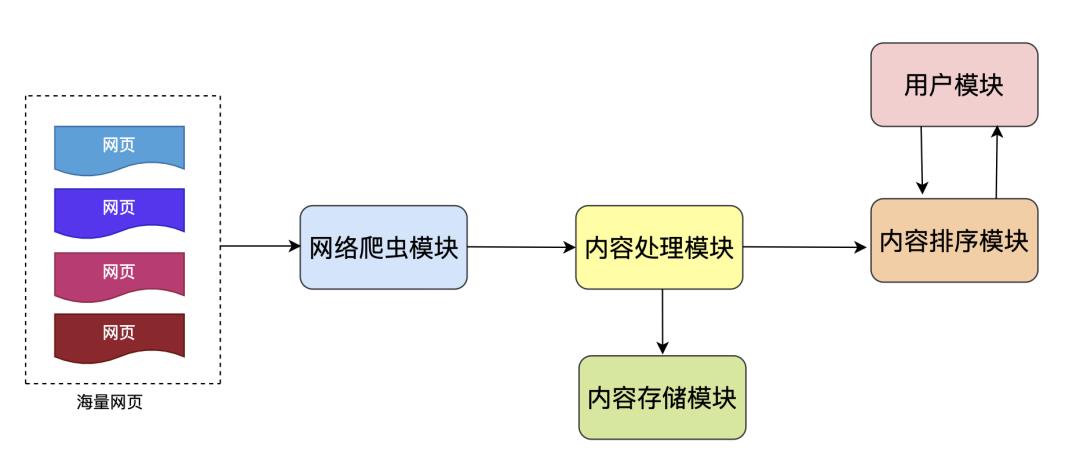
-
网络爬虫模块
搜索引擎中的网络爬虫就是网页的搬运工,负责将互联网上允许被抓取的网页进行下载,如果把搜索引擎看作一家餐厅,网络爬虫模块就是餐厅的采购员。 -
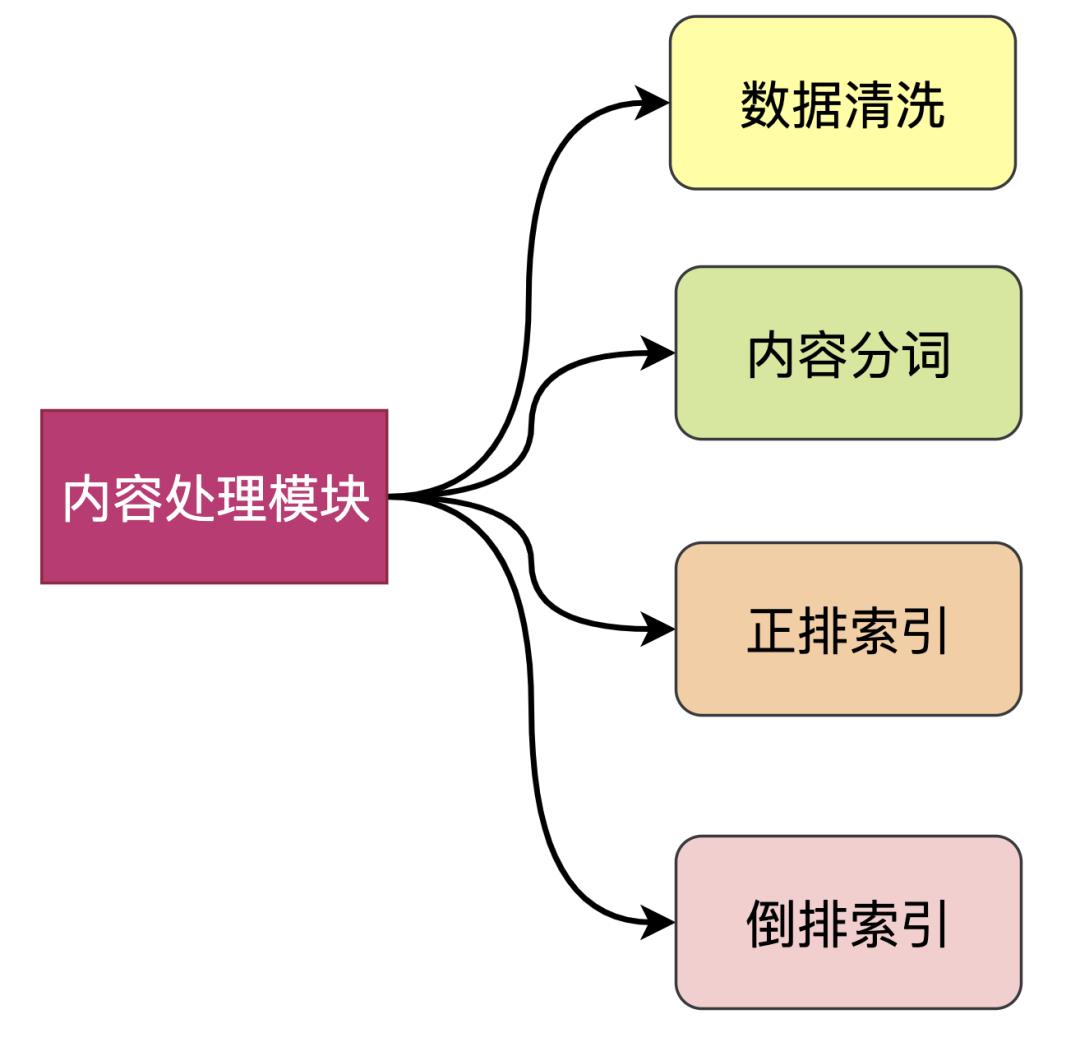
内容处理模块
负责将网络爬虫下载的页面进行内容解析、内容清洗、主体抽取、建立索引、链接分析、反作弊等环节。 -
内容存储模块
存储模块是搜索引擎的坚强后盾,将抓取的原始网页、处理后的中间结果等等进行存储,这个存储规模也是非常大的,可能需要几万台机器。 -
用户解析模块
用户模块负责接收用户的查询词、分词、同义词转换、语义理解等等,去揣摩用户的真实意图、查询重点才能返回正确的结果。 -
内容排序模块
结合用户模块解析的查询词和内容索引生成用户查询结果,并对页面进行排序,是搜索引擎比较核心的部分。
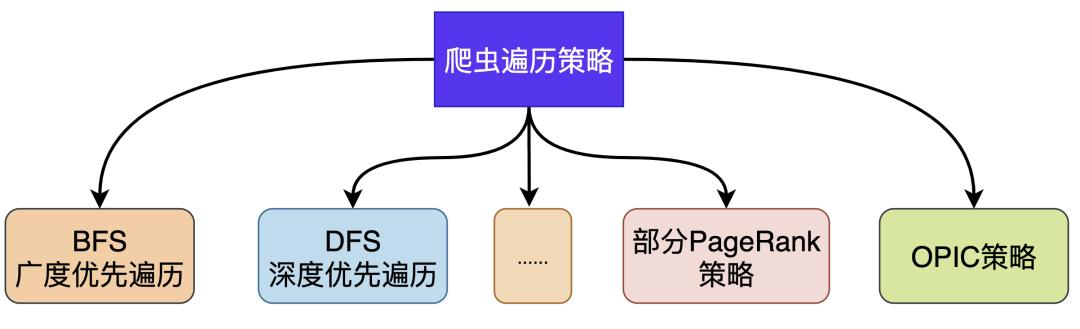
网络爬虫模块简介
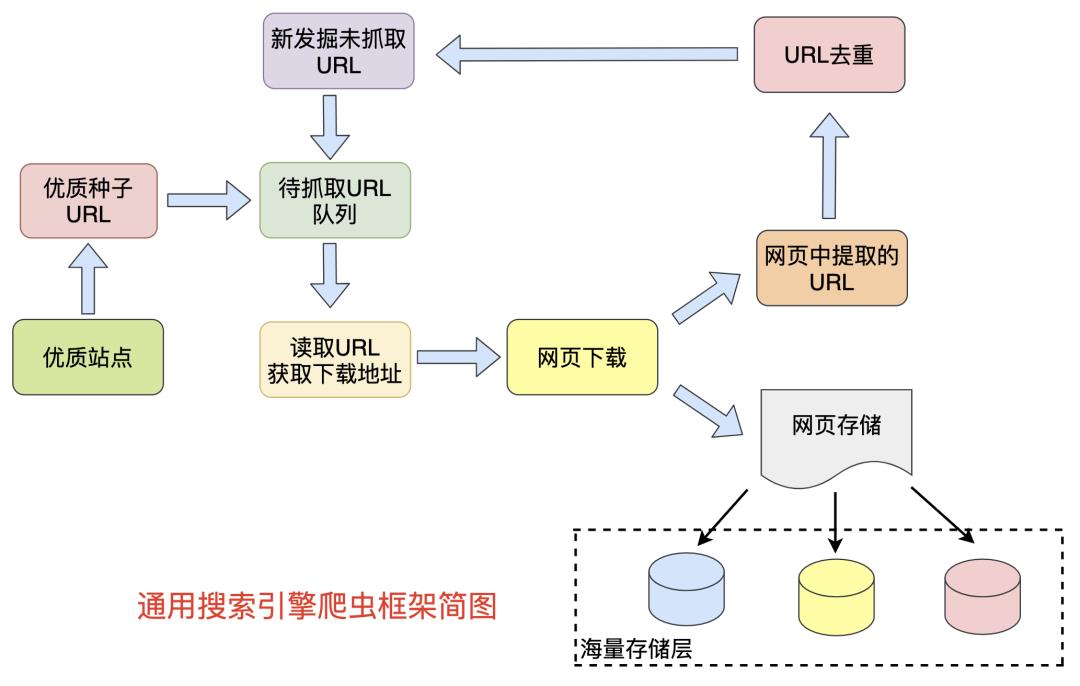
-
将热门站点的优质URL作为种子,放到待抓取的URL队列中 -
读取待抓取URL获取地址进行下载 -
将下载的网页内容进行解析,将网页存储到hbase/hdfs等,并提取网页中存在的其他URL -
发掘到新的URL进行去重,如果是未抓取的则放到抓取队列中 -
直到待抓取URL队列为空,完成本轮抓取
网页内容处理模块
5.1 数据清洗

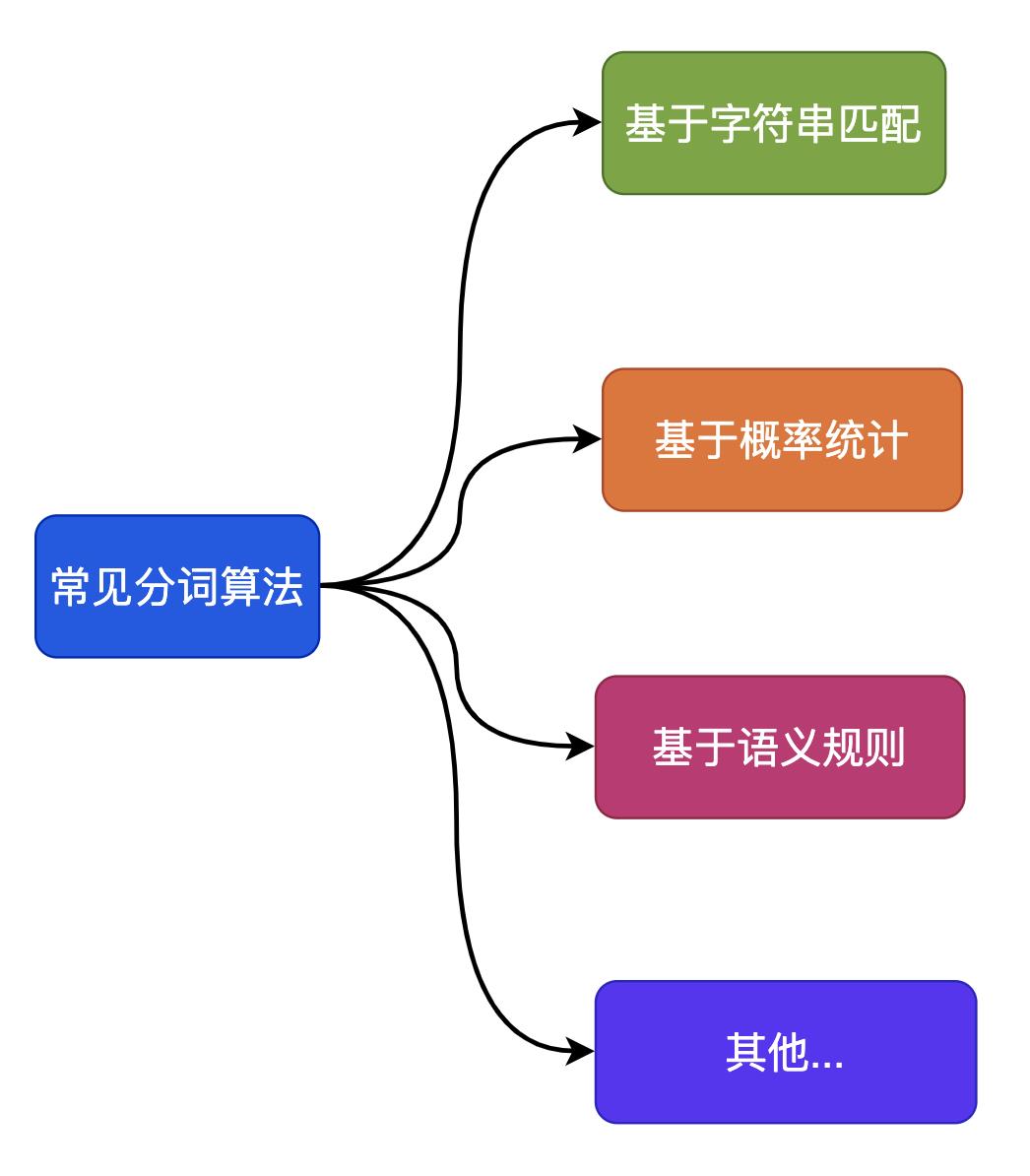
5.2 中文分词
网页分词在线工具:http://www.78901.net/fenci/
抓取网页:https://tech.huanqiu.com/article/3zMq4KbdTAA

-
基于字符串匹配的分词算法 -
基于概率统计的分词算法 -
基于语义规则的分词算法 -
其他算法
5.3 正排索引
5.4 倒排索引
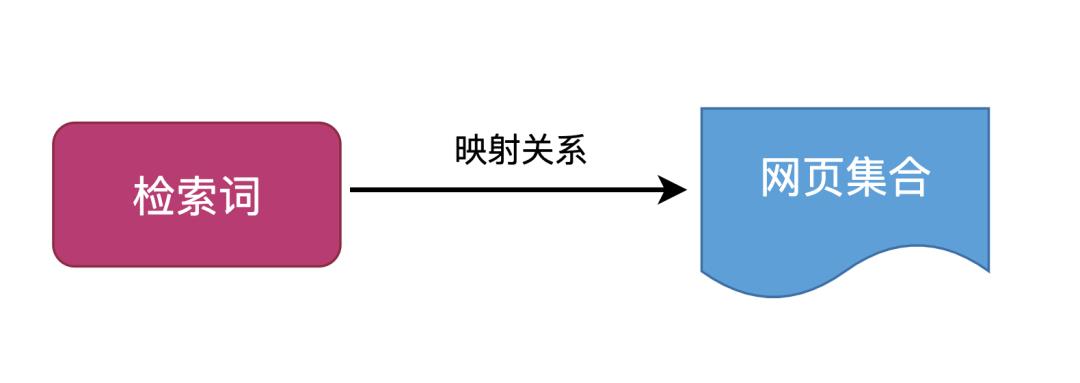
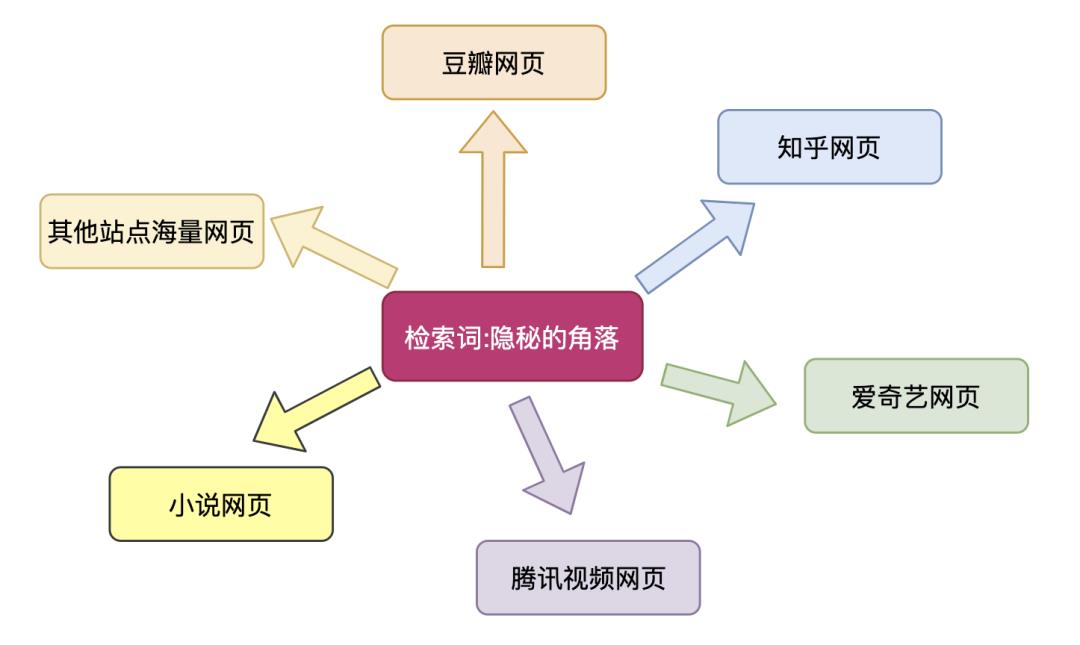
5.5 本章小结
正排索引:具体到一篇网页有多少关键词,特指属于该网页本身的内容集合,是一个网页。 倒排索引:一个检索关键词对应多少相关联的网页,也就是可备选网页集合,是一类网页。
网页排序和用户模块
6.1 网页排序的必要性

6.2 网页排序的常见策略
-
基于词频和位置权重的排序
TF-IDF (term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。 TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
-
基于链接分析的排序
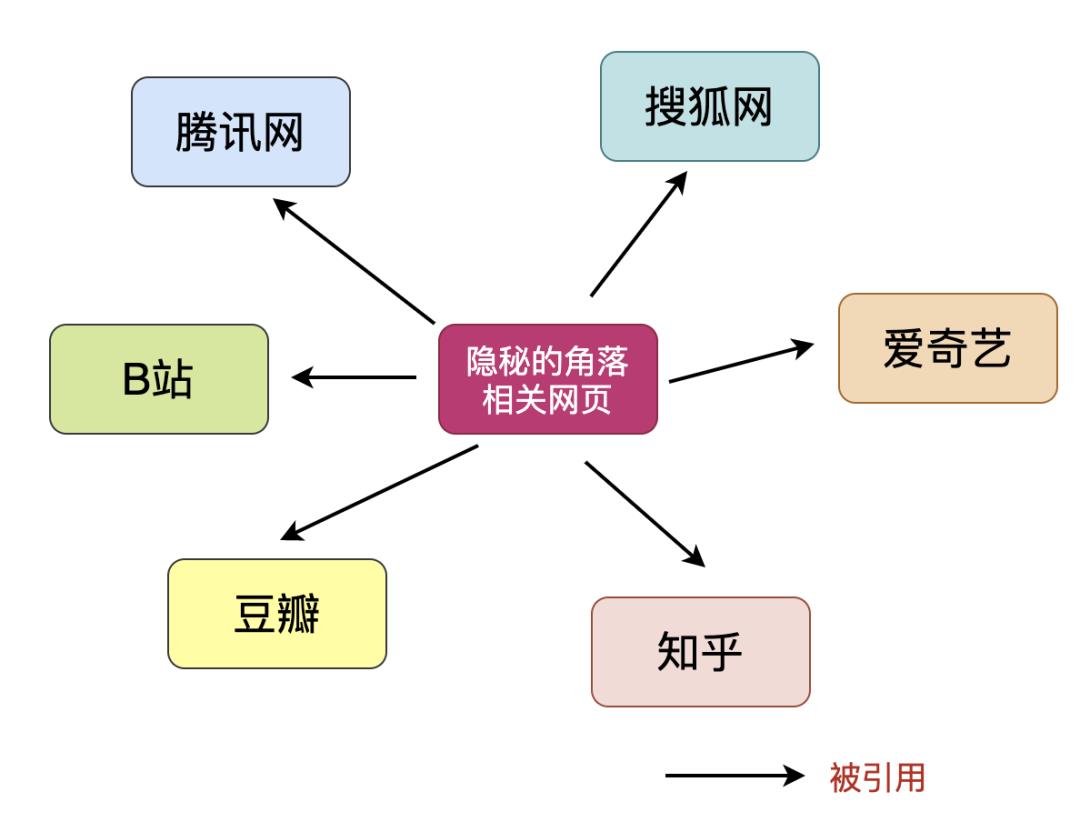
网页的重要程度用PageRank值来衡量,网页的PageRank值体现在两个方面:引用该网页其他网页个数和引用该页面的其他页面的重要程度。
假定一个网页A被另一个网页B引用,网页B就将PageRank值分配给网页B所引用的网页,所以越多引用网页A则其PageRank值也就越高。 另外网页B越重要,它所引用的页面能分配到的PageRank值就越多,网页A的PageRank值也就越高越重要。

6.3 网页反作弊和SEO
搜索引擎优化又称为SEO,即Search Engine Optimization,它是一种通过分析搜索引擎的排名规律,了解各种搜索引擎怎样进行搜索、怎样抓取互联网页面、怎样确定特定关键词的搜索结果排名的技术。
搜索引擎采用易于被搜索引用的手段,对网站进行有针对性的优化,提高网站在搜索引擎中的自然排名,吸引更多的用户访问网站,提高网站的访问量,提高网站的销售能力和宣传能力,从而提升网站的品牌效应。

-
网页内容作弊
比如在网页内容中增加大量重复热词、在标题/摘要等重要位置增加热度词、html标签作弊等等,比如在一篇主题无联系的网页中增加大量"隐秘的角落"热度词、增加<strong> 等强调性html标签。 -
链接分析作弊
构建大量相互引用的页面集合、购买高排名友链等等,就是搞很多可以指向自己网页的其他网页,从而构成一个作弊引用链条。
6.4 用户搜索意图理解
-
检索词为:美食宫保鸡丁
这个检索词算是比较优质了,但是仍然不明确是想找饭店去吃宫保鸡丁?还是想找宫保鸡丁的菜谱?还是想查宫保鸡丁的历史起源?还是宫保鸡丁的相关评价?所以会出现很多情况。 -
检索词为:你说我中午迟点啥呢?
口语化检索词并且存在错别字,其中可能涉及词语纠错、同义词转换等等,才能找到准确的检索词,进而明确检索意图,召回网页。
全文总结
- EOF -
1、
2、
3、
关注「程序员的那些事」加星标,不错过圈内事
圈内事,我在看❤️
以上是关于图解 Google 类通用搜索引擎背后的技术点的主要内容,如果未能解决你的问题,请参考以下文章