JDK 1.8 中 HashMap 扩容骚操作的变化问题
Posted 码农每日一题
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK 1.8 中 HashMap 扩容骚操作的变化问题相关的知识,希望对你有一定的参考价值。
码农每日一题

长按关注置顶
工作日每天推送一个短小精干的技术知识点,让您可以随时查漏补缺。
问:简单说说 JDK 1.8 中 HashMap 是如何扩容的?与 JDK 1.7 有什么区别?
答:JDK 1.7 中 HashMap 的扩容机制可以查看前一篇推文《》,简单总结如下图:
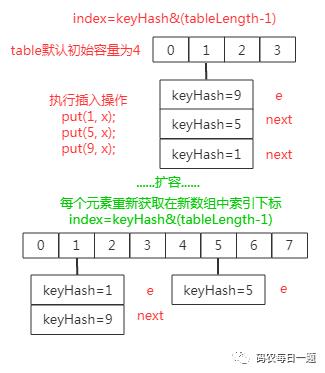
可以看见,1.7 中整个扩容过程就是一个取出数组元素(实际数组索引位置上的每个元素是每个独立单向链表的头部,也就是发生 Hash 冲突后最后放入的冲突元素)然后遍历以该元素为头的单向链表元素,依据每个被遍历元素的 hash 值计算其在新数组中的下标然后进行交换(即原来 hash 冲突的单向链表尾部变成了扩容后单向链表的头部)。
而在 JDK 1.8 中 HashMap 的扩容操作就显得更加的骚气了,由于扩容数组的长度是 2 倍关系,所以对于假设初始 tableSize =4 要扩容到 8 来说就是 0100 到 1000 的变化(左移一位就是 2 倍),在扩容中只用判断原来的 hash 值与左移动的一位按位与操作是 0 或 1 就行,0 的话索引就不变,1 的话索引变成原索引加上扩容前数组,所以其实现如下流程图所示:
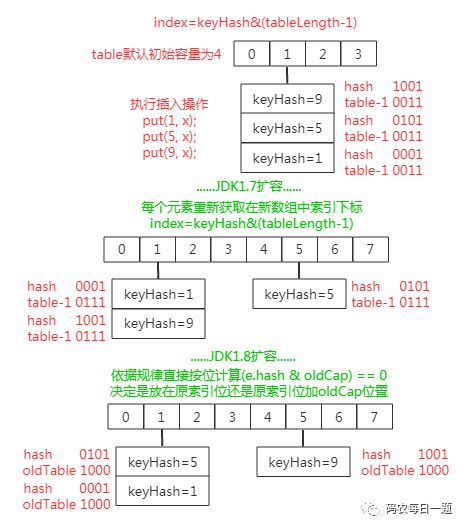
上图就是 1.8 与 1.7 扩容的核心流程图区别,其 1.8 源码核心实现如下:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//记住扩容前的数组长度和最大容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
//超过数组在java中最大容量就无能为力了,冲突就只能冲突
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
} //长度和最大容量都扩容为原来的二倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}......
......
//更新新的最大容量为扩容计算后的最大容量
threshold = newThr;
//更新扩容后的新数组长度
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
//遍历老数组下标索引
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果老数组对应索引上有元素则取出链表头元素放在e中
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//如果老数组j下标处只有一个元素则直接计算新数组中位置放置
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) //如果是树结构进行单独处理
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//能进来说明数组索引j位置上存在哈希冲突的链表结构
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//循环处理数组索引j位置上哈希冲突的链表中每个元素
do {
next = e.next;
//判断key的hash值与老数组长度与操作后结果决定元素是放在原索引处还是新索引
if ((e.hash & oldCap) == 0) {
//放在原索引处的建立新链表
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
//放在新索引(原索引+oldCap)处的建立新链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
//放入原索引处
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
//放入新索引处
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
可以看见,这个设计非常赞,因为 hash 值本来就是随机性的,所以 hash 按位与上 newTable 得到的 0(扩容前的索引位置)和 1(扩容前索引位置加上扩容前数组长度的数值索引处)就是随机的,所以扩容的过程就能把之前哈西冲突的元素再随机的分布到不同的索引去,这算是 JDK1.8 的一个优化点。
此外,在 JDK1.7 中扩容操作时哈西冲突的数组索引处的旧链表元素扩容到新数组时如果扩容后索引位置在新数组的索引位置与原数组中索引位置相同,则链表元素会发生倒置(即如上面图1,原来链表头扩容后变为尾巴);而在 JDK1.8 中不会出现链表倒置现象。
其次,由于 JDK1.7 中发生哈西冲突时仅仅采用了链表结构存储冲突元素,所以扩容时仅仅是重新计算其存储位置而已,而 JDK1.8 中为了性能在同一索引处发生哈西冲突到一定程度时链表结构会转换为红黑数结构存储冲突元素,故在扩容时如果当前索引中元素结构是红黑树且元素个数小于链表还原阈值(哈西冲突程度常量)时就会把树形结构缩小或直接还原为链表结构(其实现就是上面代码片段中的 split() 方法)。
HashMap 是面试的重灾区,也是开发中使用频率超高的集合类,所以会多唠叨几篇,已经唠叨的如下~
《》
《》
《》
《》
放松一下,顺带评论点赞分享一波~
有个人丁丁太短,于是他去学了拉丁舞。
以上是关于JDK 1.8 中 HashMap 扩容骚操作的变化问题的主要内容,如果未能解决你的问题,请参考以下文章