程序员必须了解的数据结构:ArrayHashMap 与 List
Posted 智能算法
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了程序员必须了解的数据结构:ArrayHashMap 与 List相关的知识,希望对你有一定的参考价值。
来自:众成翻译,译者 sea_ljf,《奇舞周刊》排版编辑
链接:https://www.zcfy.cc/article/data-structures-for-beginners-arrays-hashmaps-and-lists
当开发程序时,我们(通常)需要在内存中存储数据。根据操作数据方式的不同,可能会选择不同的数据结构。有很多常用的数据结构,如:Array、Map、Set、List、Tree、Graph 等等。(然而)为程序选取合适的数据结构可能并不容易。因此,希望这篇文章能帮助你了解(不同数据结构的)表现,以求在工作中合理地使用它们。
本文主要聚焦于线性的数据结构,如:Array、Set、List、Sets、Stacks、Queues 等等。原始数据类型
原始数据类型是构成数据结构最基础的元素。下面列举出一些原始原始数据类型:
整数,如:1, 2, 3, …
字符,如:a, b, "1", "*"
布尔值, true 与 false.
浮点数 ,如:3.14159, 1483e-2.
1. Array
数组可由零个或多个元素组成。由于数组易于使用且检索性能优越,它是最常用的数据结构之一。
你可以将数组想象成一个抽屉,可以将数据存到匣子中。
数组就像是将东西存到匣子中的抽屉

当你想查找某个元素时,你可以直接打开对应编号的匣子(时间复杂度为O(1))。然而,如果你忘记了匣子里存着什么,就必须逐个打开所有的匣子(时间复杂度为 O(n)),直到找到所需的东西。数组也是如此。
根据编程语言的不同,数组存在一些差异。对于 javascript 和 Ruby 等动态语言而言,数组可以包含不同的数据类型:数字,字符串,对象甚至函数。而在 Java 、 C 、C ++ 之类的强类型语言中,你必须在使用数组之前,定好它的长度与数据类型。JavaScript 会在需要时自动增加数组的长度
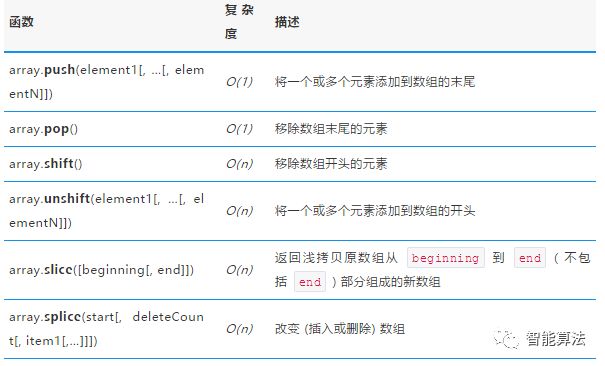
1.1 Array 的内置方法
根据编程序言的不同,数组(方法)的实现稍有不同。比如在 JavaScript 中,我们可以使用 unshift 与 push 添加元素到数组的头或尾,同时也可以使用 shift 与 pop 删除数组的首个或最后一个元素。让我们来定义一些本文用到的数组常用方法。
常用的 JS 数组内置函数
1.2 向数组插入元素
将元素插入到数组有很多方式。你可以将新数据添加到数组末尾,也可以添加到数组开头。
先看看如何添加到末尾:
function insertToTail(array, element) {
array.push(element);
return array;
}
const array = [1, 2, 3];
console.log(insertToTail(array, 4)); // => [ 1, 2, 3, 4 ]
根据规范,push 操作只是将一个新元素添加到数组的末尾。因此,
Array.push 的时间复杂度度是 O(1)。
现在看看如添加到开头:
function insertToHead(array, element) {
array.unshift(element);
return array;
}
const array = [1, 2, 3];
console.log(insertToHead(array, 0));// => [ 0, 1, 2, 3, ]
你觉得添加元素到数组开头的函数,时间复杂度是什么呢?看起来和上面(push)差不多,除了调用的方法是 unshift 而不是 push。但这有个问题,unshift 是通过将数组的每一项移到下一项,腾出首项的空间来容纳新添加的元素。所以它是遍历了一次数组的。
Array.unshift 的时间复杂度度是 O(n)。
1.3 访问数组中的元素
如果你知道待查找元素在数组中的索引,那你可以通过以下方法直接访问该元素:
function access(array, index) {
return array[index];
}
const array = [1, 'word', 3.14, { a: 1 }];
access(array, 0);// => 1
access(array, 3);// => {a: 1}
正如上面你所看到的的代码一样,访问数组中的元素耗时是恒定的:
访问数组中元素的时间复杂度是 O(1)。
注意:通过索引修改数组的值所花费的时间也是恒定的。
1.4 在数组中查找元素
如果你想查找某个元素但不知道对应的索引时,那只能通过遍历数组的每个元素,直到找到为止。
function search(array, element) {
for (let index = 0;
index < array.length;
index++) {
if (element === array[index]) {
return index;
}
}
}
const array = [1, 'word', 3.14, { a: 1 }];
console.log(search(array, 'word'));// => 1
console.log(search(array, 3.14));// => 2
鉴于使用了 for 循环,那么:
在数组中查找元素的时间复杂度是 O(n)
1.5 在数组中删除元素
你觉得从数组中删除元素的时间复杂度是什么呢?
先一起思考下这两种情况:
从数组的末尾删除元素所需时间是恒定的,也就是 O(1)。
然而,无论是从数组的开头或是中间位置删除元素,你都需要调整(删除元素后面的)元素位置。因此复杂度为 O(n)。
说多无谓,看代码好了:
function remove(array, element) {
const index = search(array, element);
array.splice(index, 1);
return array;
}
const array1 = [0, 1, 2, 3];
console.log(remove(array1, 1));// => [ 0, 2, 3 ]
我们使用了上面定义的 search 函数来查找元素的的索引,复杂度为 O(n)。然后使用JS 内置的 splice 方法,它的复杂度也是 O(n)。那(删除函数)总的时间复杂度不是 O(2n) 吗?记住,(对于时间复杂度而言,)我们并不关心常量。
对于上面列举的两种情况,考虑最坏的情况:
在数组中删除某项元素的时间复杂度是 O(n)。
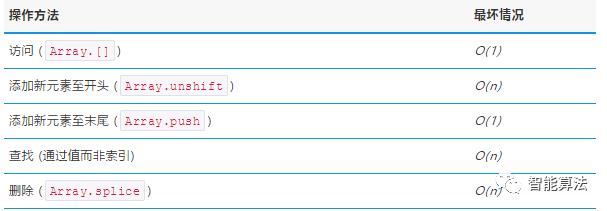
1.6 数组方法的时间复杂度
在下表中,小结了数组(方法)的时间复杂度:
数组方法的时间复杂度
2. HashMaps
HashMap有很多名字,如 HashTable、HashMap、Map、Dictionary、Associative Array 等。概念上它们都是一致的,实现上稍有不同。
哈希表是一种将键 映射到 值的数据结构。
回想一下关于抽屉的比喻,现在匣子有了标签,不再是按数字顺序了。
HashMap 也和抽屉一样存储东西,通过不同标识来区分不同匣子。

此例中,如果你要找一个玩具,你不需要依次打开第一个、第二个和第三个匣子来查看玩具是否在内。直接代开被标识为“玩具”的匣子即可。这是一个巨大的进步,查找元素的时间复杂度从 O(n) 降为 O(1) 了。
数字是数组的索引,而标识则作为 HashMap 存储数据的键。HashMap 内部通过 哈希函数 将键(也就是标识)转化为索引。
至少有两种方式可以实现 hashmap:
数组:通过哈希函数将键映射为数组的索引。(查找)最差情况: O(n),平均: O(1)。
二叉搜索树: 使用自平衡二叉搜索树查找值(另外的文章会详细介绍)。 (查找)最差情况: O(log n),平均:O(log n)。
我们会介绍树与二叉搜索树,现在先不用担心太多。实现 Map 最常用的方式是使用 数组与哈希转换函数。让我们(通过数组)来实现它吧
通过数组实现 HashMap
 indexes")
正如上图所示,每个键都被转换为一个 hash code。由于数组的大小是有限的(如此例中是10),(如发生冲突,)我们必须使用模函数找到对应的桶(译者注:桶指的是数组的项),再循环遍历该桶(来寻找待查询的值)。每个桶内,我们存储的是一组组的键值对,如果桶内存储了多个键值对,将采用集合来存储它们。
我们将讲述 HashMap 的组成,让我们先从哈希函数开始吧。
2.1 哈希函数
实现 HashMap 的第一步是写出一个哈希函数。这个函数会将键映射为对应(索引的)值。
完美的哈希函数 是为每一个不同的键映射为不同的索引。
借助理想的哈希函数,可以实现访问与查找在恒定时间内完成。然而,完美的哈希函数在实践中是难以实现的。你很可能会碰到两个不同的键被映射为同一索引的情况,也就是 冲突。
当使用类似数组之类的数据结构作为 HashMap 的实现时,冲突是难以避免的。因此,解决冲突的其中一种方式是在同一个桶中存储多个值。当我们试图访问某个键对应的值时,如果在对应的桶中发现多组键值对,则需要遍历它们(以寻找该键对应的值),时间复杂度为 O(n)。然而,在大多数(HashMap)的实现中, HashMap 会动态调整数组的长度以免冲突发生过多。因此我们可以说分摊后的查找时间为 O(1)。本文中我们将通过一个例子,讲述分摊的含义。
HashMap 的简单实现
一个简单(但糟糕)的哈希函数可以是这样的:
class NaiveHashMap {
constructor(initialCapacity = 2) {
this.buckets = new Array(initialCapacity);
}
set(key, value) {
const index = this.getIndex(key);
this.buckets[index] = value;
}
get(key) {
const index = this.getIndex(key);
return this.buckets[index];
}
hash(key) {
return key.toString().length;
}
getIndex(key) {
const indexHash = this.hash(key);
const index = indexHash % this.buckets.length;
return index;
}
}
完整代码
我们直接使用桶而不是抽屉与匣子,相信你能明白喻义的意思 :)
HashMap 的初始容量(译者注:容量指的是用于存储数据的数组长度,即桶的数量)是2(两个桶)。当我们往里面存储多个元素时,通过求余 % 计算出该键应存入桶的编号(,并将数据存入该桶中)。
留意代码的第18行(即 return key.toString().length;)。之后我们会对此进行一点讨论。现在先让我们使用一下这个新的 HashMap 吧。
// Usage:
const assert = require('assert');
const hashMap = new NaiveHashMap();
hashMap.set('cat', 2);
hashMap.set('rat', 7);
hashMap.set('dog', 1);
hashMap.set('art', 8);
console.log(hashMap.buckets);
/*
bucket #0: <1 empty item>,
bucket #1: 8
*/
assert.equal(hashMap.get('art'), 8); // this one is ok
assert.equal(hashMap.get('cat'), 8); // got overwritten by art
以上是关于程序员必须了解的数据结构:ArrayHashMap 与 List的主要内容,如果未能解决你的问题,请参考以下文章
[译] 初学者应该了解的数据结构:ArrayHashMap 与 List