HashMap1.8
Posted 职业代码搬运
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap1.8相关的知识,希望对你有一定的参考价值。
HashMap 简介
HashMap 实现了 Map 接口规范,和继承了 AbstractMap 类
HashMap 是一个集合容器,以键值对的形式,进行数据的存储
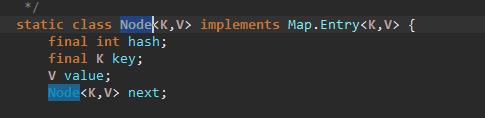
HashMap 底层数据存储
问:HashMap 的数据存储结构到底是什么样的?
答:HashMap 底层的数据存储结构是 数组+链表
问:那么 HashMap 为什么要使用数组 + 链表 ,直接使用数组不就可以了。
答:
第一:数组的存储空间是连续的,占用内存连续,查询快(寻址容易),但是写速度慢(如果插入一个数,需要把后面的数据向后移动,所以速度慢)
第二:链表的存储空间离散,占用的内存比较松散,查询慢(寻址慢),但是写速度快(插入一个数据,只需要进行引用指向就可以了)
两者相结合,既提高了查询速度,同时也提高了增加和删除的速度,所以使用 数据 + 链表的形式。
问:你说HashMap 底层数据,那么数组不是声明空间之后就是固定长度的吗,那么数据增加要怎么存?
数组在声明长度之后,确实就定型了。并且默认初始长度为 1 << 4=16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
在HashMap 中一个方法:resize()
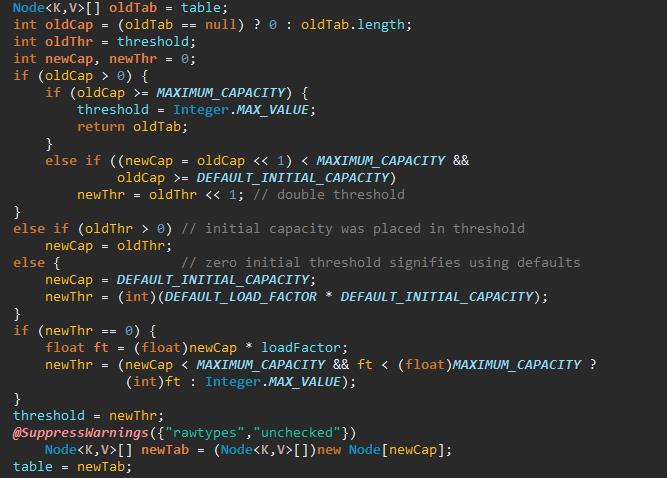
主要逻辑:
1、判断 旧的数组长度是否超过 HashMap 中定义的最大值,或者扩容之后的长度不超过定义的最大值 MAXIMUM_CAPACITY=1 << 30
2、判断旧的数组的长度是否大于 当前容量的75% (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY)
3、当条件满足,则对数据进行扩容,扩容长度为 oldTab.length <<1
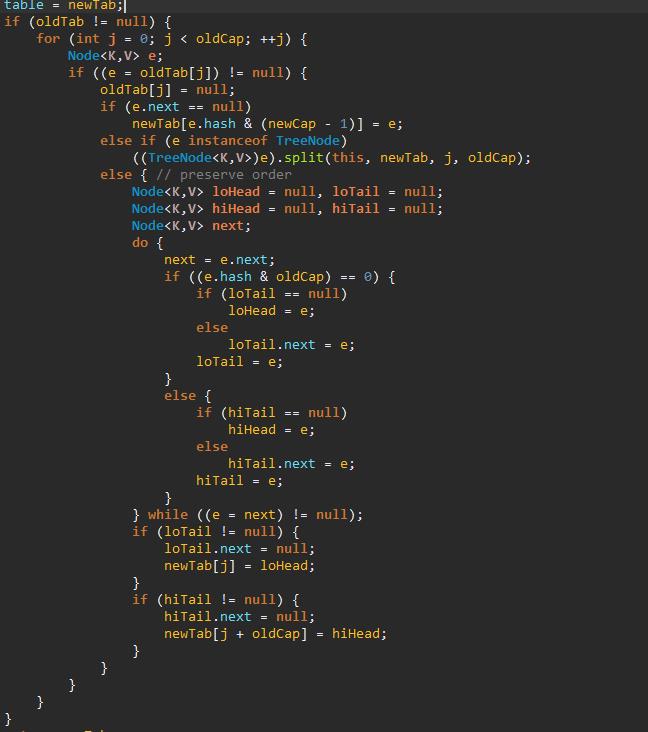
之后对数组进行迁移,以及 链表节点的转移
问:那么在put 数据的时候,数据是怎么找到他存放的位置的。
答:HashMap 在进行 put 数据的使用,通过计算 获取 数组长度上的位置,然后存放数据。、

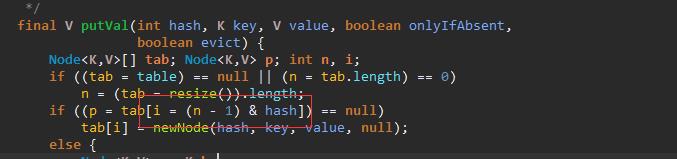
从上面代码可以的出来:数组位置的计算为:
( 当前数组的长度 - 1 ) & hash
举一个计算例子: 假设当前有一个 字符串 “QGUOFENG" ,此时的HashMap 长度为默认的 16
代码:
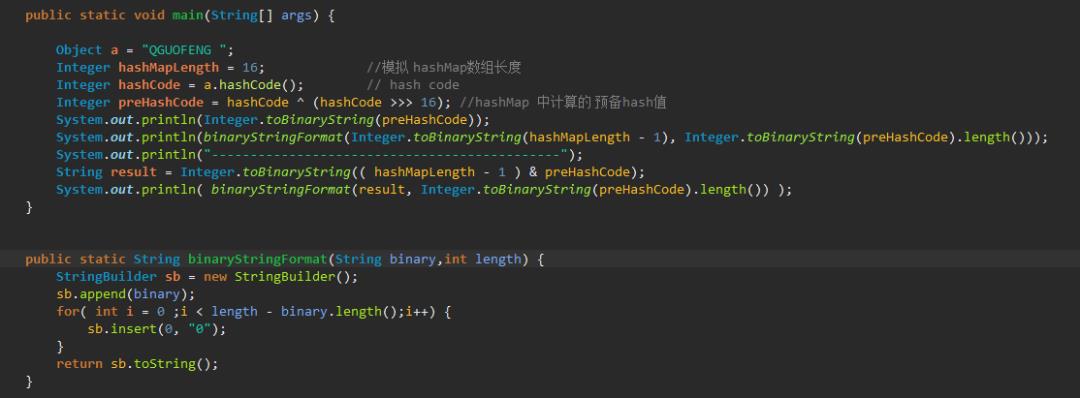
结果:14
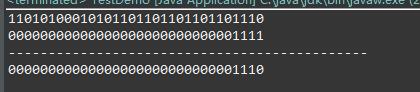
从 hashMap 获取 数据位置的计算中,我们可以知道:
为了通过hash值进行数组位置的定位,让获取到的数组位置,在数组的合法范围之内,数组的长度的设计 是关键所在。
比如:当前数组长度 16 则 进行 & 运算的结果为 1111,其实就是 15 ,在 1 前面全部为零,则计算出来的结果就取决于 hash 的最后4为。
同时数组长度的设计为 2 的倍数,所以,每次 与 hash 值进行计算的 必定为 000.00 + 111...111 的值,保证了,每次进行位置获取的时候,足够的随机,并且不会超出数据合法范围
问:那既然数组都有扩容机制,对应的链表应该也有吧,总不能一 直无线的增加节点吧。
答:是的,链表也有对应的策略,因为难免出现 hash 总是 指向同一个位置,导致链表过长。在 resize() 中的split()方法
在 putVal 中,当 数节点的长度大于等于8的时候进行,红黑树的变更
在 resize() 中的split() 中,当 书节点的长度小于6的时候,将树变成链表结构
以上是关于HashMap1.8的主要内容,如果未能解决你的问题,请参考以下文章