万万没想到,HashMap默认容量的选择,竟然背后有这么多思考!?
Posted Java编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万万没想到,HashMap默认容量的选择,竟然背后有这么多思考!?相关的知识,希望对你有一定的参考价值。
来自公众号: Hollis
Map<String, String> map = new HashMap<String, String>();
什么是容量
Map<String, String> map = new HashMap<String, String>();
map.put("hollis", "hollischuang");
Class<?> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
Field size = mapType.getDeclaredField("size");
size.setAccessible(true);
System.out.println("size : " + size.get(map));
capacity : 16、size : 1
容量与哈希

hash的实现
hash : 该方法主要是将Object转换成一个整型。 indexFor : 该方法主要是将hash生成的整型转换成链表数组中的下标。
static int indexFor(int h, int length) {
return h & (length-1);
}
位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
X % 2^n = X & (2^n – 1)
6 % 8 = 6 ,6 & 7 = 6
10 & 8 = 2 ,10 & 7 = 2
运算过程如下如:
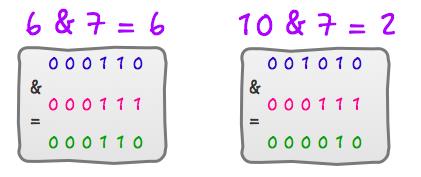
所以,return h & (length-1);只要保证length的长度是2^n 的话,就可以实现取模运算了。
在JDK 8中,关于默认容量的定义为: static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 ,其故意把16写成1<<4,就是提醒开发者,这个地方要是2的幂。 值得玩味的是: 注释中的 aka 16 也是1.8中新增的,
指定容量初始化
在JDK 1.7和JDK 1.8中,HashMap初始化这个容量的时机不同。 JDK 1.8中,在调用HashMap的构造函数定义HashMap的时候,就会进行容量的设定。 而在JDK 1.7中,要等到第一次put操作时才进行这一操作。
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
Step 1,5->7 Step 2,7->8 Step 1,9->15 Step 2,15->16 Step 1,19->31 Step 2,31->32
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
1100 1100 1100 >>>1 = 0110 0110 0110
1100 1100 1100 | 0110 0110 0110 = 1110 1110 1110
1110 1110 1110 >>>2 = 0011 1011 1011
1110 1110 1110 | 0011 1011 1011 = 1111 1111 1111
1111 1111 1111 >>>4 = 1111 1111 1111
1111 1111 1111 | 1111 1111 1111 = 1111 1111 1111
扩容
if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
总结
●编号1161,输入编号直达本文
●输入m获取文章目录
分享程序员找工作经验
程序员笔试、面试题
以上是关于万万没想到,HashMap默认容量的选择,竟然背后有这么多思考!?的主要内容,如果未能解决你的问题,请参考以下文章