前Googler:Docker从上手到差点放弃
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前Googler:Docker从上手到差点放弃相关的知识,希望对你有一定的参考价值。
本文是数人云深圳技术分享课上Coding CTO,前Google SRE 孙宇聪同学演讲实录的部分内容(本文标题由高效运维根据内容而诙谐设定)。如需转载,请保留全部内容,否则必究。
个人介绍:从Google到Coding
先吹吹牛,介绍一下我自己。我2007年加入的Google,2009年去的Google美国总部。我去了以后参加两个大项目,一个项目是YouTube,国内不存在的视频网站,当年经历了YouTube爆发式增长的阶段,从无到有的过程。
后来转到Google cloud platform,当时做的主要是Google所有内部百万台服务器的运维服务,要管理机器从工厂造出来那一刻,接上电源以后,然后安装、部署,包括运行软件,最后都要销毁,当时两个团队20人,管全球100多万台机器,我们不是管机器的,是让系统管机器。
我目前公司 Coding,基于终端业务的码市,用张老板的话说让自由人自由连接,需求方找到程序员,程序员找到需求方。我们开发针对很多程序员的生产力工具,如项目管理、代码仓库、在线开发的WebIDE、演示平台。
2015年上半年,基本上大上半年的时间,我们搞了所谓的Docker化,最开始我们内部使用的都是一个所谓单机部署,每个人都要自己拷贝这样的文件,然后执行命令。
我们后来搞了一个Docker化,Docker化的结果是,所有的代码打包成了Docker Image。Docker生产环境有自己的私有Registry,用Docker container运行代码。
搞完这些后,我们发现Docker到处是坑。
小姐身子丫鬟命:Docker Engine (Runtime)
Docker daemon,也就是运行时,当时大家觉得很厉害,一开始都说用容器必须用Docker,后来发现Docker daemon不是唯一的一个启动容器的途径,跟以前搞的都是一回事。
Docker daemon会遇到一个问题,任何人用Docker第一天都发现,Docker 里面没有init,daemon也没有reap子进程,如果程序fork很多进程,会在系统中出现很多僵尸进程,最终导致 docker daemon 出现问题,国内目前也没有把这个问题解决。
每次跑一个Docker程序的时候都要担心,我们会担心这个Docker有没有处理好僵尸进程的问题。
二是Docker后面的存储系统没有一个靠谱的,用AUFS,很多垃圾文件不清理,我从事软件开发这么多年从来没有过,很少见,大部分都是已经打包好的程序,不会占用很多磁盘iNode。
最新版OverlayFS产生一些死锁还有崩溃,BTRfs也是。
当时我们对人生产生了怀疑,为什么我们要自找这么多事,我们原来跑得好好的,为什么搞到Docker上来,遇到了一些新问题。
我们甚至把Docker daemon改成Open SSH,但Docker daemon和Open SSH其实是一回事,就是提供远程命令执行的工具。
你也可以理解为一个木马,发一个指令就跑一个程序,而且跑的还有问题,我们不如直接SSH连接上运行这个程序,都比这个靠谱,当时很难受。
后来发现,Docker daemon本质上是一个所谓的系统工具,它不停地扫描系统中的文件路径,进入这个状态。它有两个问题:
一是原子性操作的问题,你Docker删除很麻烦,要删目录,调一堆系统API,任何一个地方出现问题都会造成垃圾,造成系统死锁。
Docker daemon一重启,别的肯定也会要重启,容易对个人在团队里的声誉造成很大的影响。

Docker daemon?坑坑坑!
Docker daemon有很多问题,Docker是当时可选的东西,给我们带来好处,但是随之而来的也有一些问题。
Docker团队自己也意识到有问题,后来美国的容器界神仙(不仅仅Docker)打一下架,觉得我们同意搞一个所谓的OCI,它成立了一个标准,就产生了一个Runc的东西,用于具体执行container。
Docker公司一听说这个东西就赶紧把代码捐出来,给了Runc,好处是他对代码很熟悉,赶紧搞了一个containerD,是grpc warpper,通过grpc访问的一个服务,最后用户还保证Docker不变。
对Docker来说,OCI像毒药,逼着他吃,但是吃完也对他本身造成威胁。
对最终用户是好事,如果我们发现Docker不靠谱,就直接用containerd交流,如果containerd也不靠谱,就绕过去让他和Runc交流,你不再绑在一个Docker。
跟虚拟化是一样的,以前大家觉得虚拟化就是Vmware,必须得用Vmware的一套东西才能看得见。
现在分层,先有KVM,然后有QEMU和containerD差不多,再上面有Openstack。和Google的东西一样,把逻辑分层,不再是一团,从上到下捅到底,每一层都被替换,灵活性更高、性能也会更好。
鸡肋的Docker Image:一个不那么圆的轮子
而后我们又发现Docker Image本身也不怎么样,最后大家的评论是非常鸡肋。
Docker Image就是一个压缩包,如果你想把一个东西传给另一个人打一个包压缩一下发过去,是一样的,Image又能分层,又能节省传输。
这个东西都是扯淡,因为我们内网一秒好几百M,省出10M的磁盘空间对我们来说是省几毫秒。
Docker Image来自于DockerFile,Dockerfile有一些表面问题,首先是不会写,这个东西是他自己发明的,对于开发者来说,这个东西对你是有学习障碍的东西。
你学习过程中荡涤了你的灵魂,又开始怀疑人生。所以用Docker就经常怀疑人生,你觉得以前学的东西都不好使了,用了一段时间以后发现这些都是骗人的,你要干的事还是一样。
Docker的核心问题,或者是Image核心问题一是编译代码,二是打包成镜像发出去。怎么编译,怎么打包,这两件事是完全分开的,不应该搀在一起。
你下次写Docker Image的时候,发现写DockerFile,既做编译,又做打包,恭喜你,你已经成功地给自己挖很多坑,运行的时候发现打包一次需要好几小时,下载一堆东西,最后打包的镜像好几十G,这些事情我们都干过。
我们第一个镜像是打包完3G多,当时我们震惊了,这么辛苦写了这么多的代码吗,运行程序就达到3G。
实践1:Build&Package&Run
最后我们理解了,你要做好一个事情,Build和Package要分家,先Build好代码,再把编译的结果塞到Image运行。Build要灵活,要针对所有系统来做。
你的代码是什么样就应该怎么Build,你要写Java,最后产生一个结果是Java包,如果不是就说明你的代码写得有问题,你应该在这个问题上解决,最后就产生Java包,Package就是把Java和Java包放在一起运行。
我们最后的Dockerfile就三行,第一行是from某个基础镜像,一个Java运行时,第二行是add某个Java包,第三是CMD运行。
DockerFile基本上我们处于鸡肋状态,用它还可以利用它去推代码,这部分功能还是有点用的。但是真正用DockerFile,我们不会用它做复杂逻辑。
把Build和Package分开,我们用的所有编程语言都已经把编译工具搞好,所有的编译工具都能产生一个单独的包。我们尝试用DockerFile同时解决build和package这两个问题,真是没事找事。。。
用Docker的时候发现我干了一堆事,看起来很牛,但是实际效果并不好。作为程序员得审视这个问题,就是能不能产生价值啊:
如果不产生价值你是在给Docker打工,盲目跟从Docker,他说这么干就这么干,他如果改了你这些东西就浪费了。如果你抓住本质,Docker怎么改对你就没有影响。
Package的构成我们还是用的Docker image的方式,写了三行,一是Java的运行时环境,二是Java包,三是怎么运行Java,这是所谓的Package。
后来发现三行太多,应该写两行,他让我们写一行就写一行。为什么第三行不用写?Java程序执行起来都一样,都是Java -jar这些东西,你要加一些参数。不会写到Image里会发现,Java调一下内存要重新打包吗?太不合理了。
最后CMD就不写了,Docker直接执行,在配置文件里执行。基本上所有的服务,要么是三行,要么是两行。
实践2:去其糟粕,取其精华
在使用的过程中我们发现,Docker有很多花里胡哨的东西,结果却是什么也没用,我们用的是非常简单的,就把Docker当成容器。
为什么呢?第一点你看到大部分文章讲Docker作为公有云平台我们应该如何使用Docker,这是国内公司的通病。
搞Docker的部门大部分是公司的运维部门,国内的运维部门没有权限改代码,只能改自己的平台,作为公司的平台部门得提供各种SDN的服务,研发人员根本不需要这东西。
如果你没有SDN,就是主机,就是host网络模式,给你分配一个端口,保证你的端口是可用的,这个就行了,以前Borg就是这样,Google搞了十年,每个开发的人都知道,我们启动的时候得找一下本地端口什么样,要么可以配置,要么可以自动寻找一个可用端口。
Docker来了说你不用干这个事,我给你一个IP,给你一个80,你永远可以访问这个。但是他没有做到,做了很多后面的东西,SDN,各种打包,性能很差。
这个事一般他不告诉你,当你上了贼船以后,为什么我们的程序性能这么差。
他说困难是暂时的,面包会有的,未来两年这个性能就提高了。我说未来两年我们程序都不用了,早就换了,这个明显是不合理的。
经常有人问我你们用Docker这么多,怎么解决共享存储的问题。
我说我们没有共享存储,以前是什么样还是什么样。
很多程序,共享存储一是要改代码,或者说有一个很牛的,我们能够申请一个文件系统,自动挂载上面。后来我们发现这个东西没有一个有用的,对我们来说没有区别。
我们的编程模型还是针对本地服务,我们在编程的时候已经考虑到如果本地文件不存在怎么办,迁移数据怎么办,我们都有现成的解决方案。为什么要换?我们还是用Host模型。
数据就是写在机器上,如果你要迁移这台机器,如果这个东西有状态,你就应该处理这个状态,而不是运维部门帮你解决处理状态的问题,这是公司里效率最低的方式:
还得跟运维部门协调,我们要迁移了,运维部门说我帮你把数据拷过去,这个是不行的。
Docker有一个更大的坑,我把这个东西都转成Docker运行,你一看时区都是GMT时区,有种到了爱尔兰的感觉,所有的log时间对不上了。
Docker没告诉你,主机里的locale,你的编码设置、时区设置,每个用户passwd都是用的默认的设置。
这给我们造成很大困扰。每一个打包的人得关心到底是什么样?到底怎么正确设置时区,密码这些东西?
后来我们直接就mount,跟主机一样,如果今天这个程序运行在中国的一台主机上,他就应该用这台主机的模式。
我们用容器,很多时候变成我们真的只关心,第一是运行时的版本,第二是代码的版本,只有这两个东西是会变的,其他东西都是跟着主机一起走,这个模型是最简单,最有利于推广云计划、分布式计算的。
不管你做不做容器都应该往几个方向努力,一是所谓的对生产环境的管理模式:宠物式管理和放牛式管理。
宠物式管理是你搞一台机器,给这个机器起好听的名,很多公司有专门的机器叫数据库,这个机器有特殊的人调试。
突然有一天这个机器挂了,你得把这个机器修好,这是宠物式管理,你得把这个东西修好,不修好整个业务就停了,数据库是最典型的。
除了数据库外我们采用的所有管理方式都是放牛式管理,你放一百头牛,有一只牛吃完口吐白沫倒下了,你的第一反应不是你的牛吃病了,一定是咔,然后再拿一头新牛过来,如果做到这一点很多事就很简单,你随时保证资源,保证有一百头牛在跑就行了。
二是在国内公有云平台上,最依赖的还是静态手动资源配置。因为我们大部分业务都是所谓的daemon job,服务型任务,你的东西一启动它就要一直运行,占用一定的数量的内存,一定数量的CPU,就持续提供服务。
所以这个东西要迁移对你没有任何好处,可能能够提高你资源利用率,如果你搞一台新机器把这个东西分过去。但是同样的,你在这也是用CPU,那也是用CPU,对你来说花钱一样花。
所以很多时候动态调配在daemon job是没意义的,除非不停地有机器挂,公有云虚拟化了,已经减少了很多这方面的问题。
我们最关心的是留出足够的富裕量,搞出冗余,不受任何一个单独虚拟机的影响。
动态调配对我们意义不大,动态调配唯一有用的地方是你有批处理、周期性任务,他运行时间比较短,你又不关心在什么地方运行,这是容器平台截然不同的两个的使用场景,这两个应用场景可能有不同的方案解决。
实践3:工具化、代码化、半自动化
最后得出的结论,算我提出的一个口号,怎么样能够减轻你运维的压力,或提高你开发的效率?
你是要把所有做的事情,所有需要人力参与的事情工具化、代码化、半自动化,完全自动化这个事很难,涉及到你要通过实践积累,把各种各样的边缘情况考虑到。
现在对我们来说,80%的是半自动化,执行的时候不出错,很快地执行。这是我们所谓开发编排系统的主要目标。
在一个公司里什么任务运行在什么机器上,很多时候存在开发人员的脑袋里,比如数据库的IP是什么,你如果能想起来,这就说明你们公司的代码化不够。
代码化把人才知道的东西都写到机器里,对我来说不关心数据库的IP是什么,我只要知道它的域名找到对应的机器连接就行了。

对我们的生产环境,第一什么东西跑在什么机器上,怎么连接。二是搞出常用的属性管理,比如名字是什么,端口是什么,有什么特点。
三是我们仿照Google搞了一个Jobs/Tasks的抽象层,Google里面最大的抽象层,你一个任务可以有多个副本在运行,这个任务今天跑5个副本,明天跑100个,这个集群可以直接搞定,我们把这个概念抄过来,相当于每一个任务都有2-3个Tasks。
最后把数据写进代码化的配置文件里时,你发现集群可以复制,你在这个集群上可以跑,在那个集群上只要调调资源的对应关系,具体跑在什么地方,你就会发现这个就是所谓的可复制集群,你本地也可以跑一套,在生产环境、配置文件都可以跑一套:
这是最关键的点,不管你怎么干,你最后都要干一个类似的事,就是把生产环境代码化。
接下来,基于刚才的知识搞了一个小工具,这些工具是提供原子性的操作。up是启动,down是干掉,rollingupdate是一个个更新,保证每个更新完了可以启动进行下一个更新,对研发来说就需要这个东西,他们都理解。
你说我有一个UI页面,你点鼠标,他很不理解,他不知道产生什么事情。任何一个集群管理系统,就是要设置所谓的接口,你要提供一些原子化、半自动操作,去协助开发者达到他想要干的事,这是所谓的编排系统最应该提供的东西。
后来我们应该有一个所谓的diff,运行过程中怎么有配置的改变,改变要看一下先改什么,然后再真正应用这些改变。
后来又搞了网页系统,可以用网页看,以前连网页都没有,后来觉得还是不太方便。在网页系统,以前连网页都没有,上可以直接看log,甚至远程登在某个容器进行操作。这是最小的功能机,最有用的。
实践总结
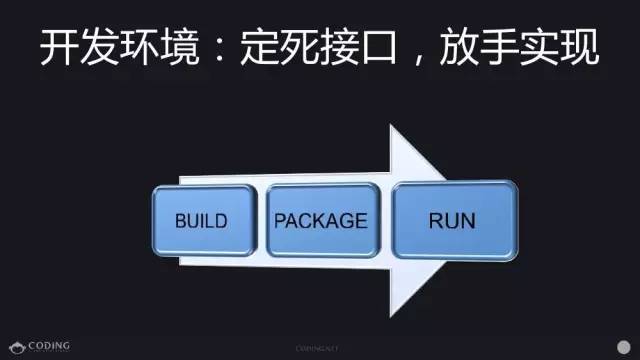
最后总结一下,第一点,想要把容器化、或想要把分布式系统做好,你要定死接口,放手实现,对你来说只需要三个接口,build、package、run,能满足效果,能运行就行了,每个项目都有不同的需求,不可能强求它完全一致。
第二个,生产环境容器化。很多业务有本地依赖,不能挪动。
但是最好的情况,第一,你一定要做到软件把它包起来,你软件用到的所有资源、所有的文件都是集中在container这个里面的,不会用到别人的东西,中间不会产生交集,这是包起来第一步。
这一步很难,很多应用配置文件都写在系统的不同地方,这个机器上可以跑,那个机器跑不起来,只有包起来才能挪动,别的东西能正常访问,这是最重要的。如果这两个东西都做成以后,这个东西做成可复制,可以延伸、可以扩展、可以复制,这就是容器化做好了。
针对DEVOPS实现代码化、工具化,最后实现自动化就行了

数人云
将应用弹性做到极致

据说,你离运维高手之间,只差一个“置顶”的距离?!
怎么“置顶”?很快很简单!请看!
以上是关于前Googler:Docker从上手到差点放弃的主要内容,如果未能解决你的问题,请参考以下文章